-
Book Overview & Buying

-
Table Of Contents

Learning Pandas
By :
Learning Pandas
By:
Overview of this book
If you are a Python programmer who wants to get started with performing data analysis using pandas and Python, this is the book for you. Some experience with statistical analysis would be helpful but is not mandatory.
Table of Contents (16 chapters)
Preface

 Free Chapter
Free Chapter
pandas and Data Analysis
Up and Running with pandas
Representing Univariate Data with the Series
Representing Tabular and Multivariate Data with the DataFrame
Manipulating DataFrame Structure
Indexing Data
Categorical Data
Numerical and Statistical Methods
Accessing Data
Tidying Up Your Data
Combining, Relating, and Reshaping Data
Data Aggregation
Time-Series Modelling
Visualization
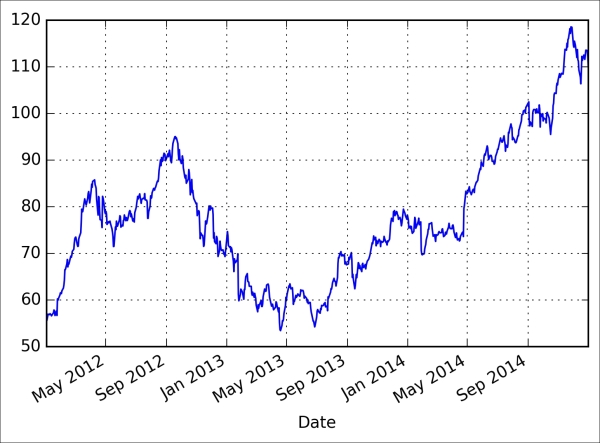
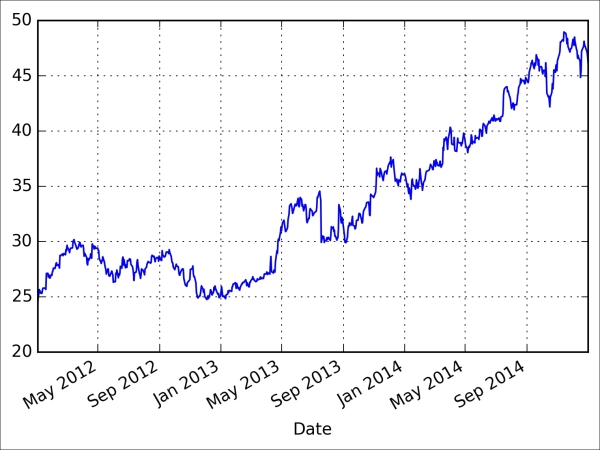
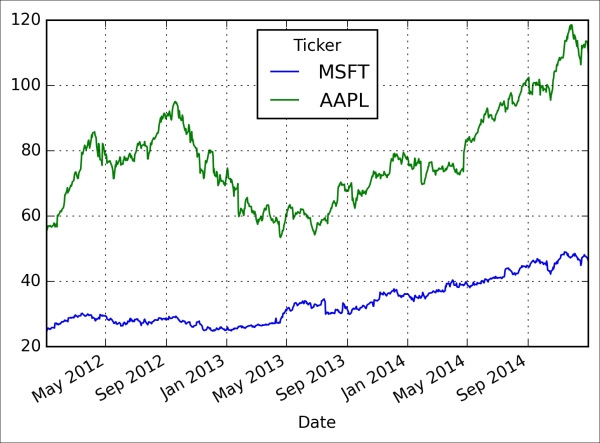
Historical Stock Price Analysis