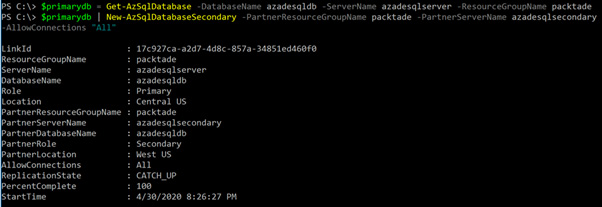
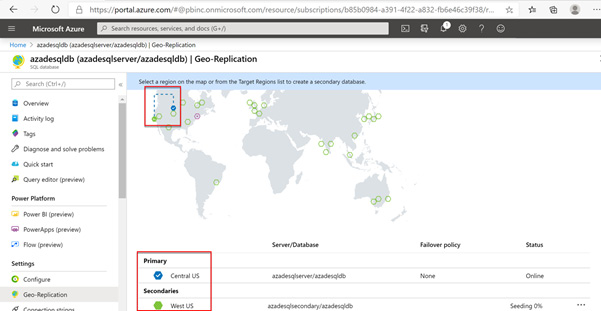
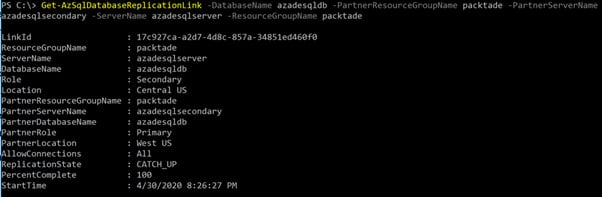
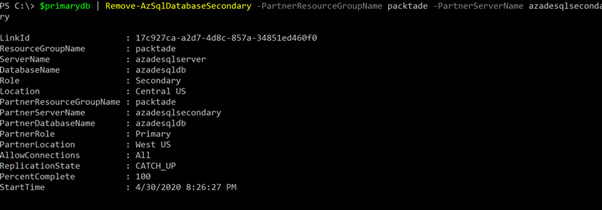
-
Book Overview & Buying

-
Table Of Contents

Azure Data Engineering Cookbook
By :
Azure Data Engineering Cookbook
By:
Overview of this book
Data engineering is one of the faster growing job areas as Data Engineers are the ones who ensure that the data is extracted, provisioned and the data is of the highest quality for data analysis. This book uses various Azure services to implement and maintain infrastructure to extract data from multiple sources, and then transform and load it for data analysis.
It takes you through different techniques for performing big data engineering using Microsoft Azure Data services. It begins by showing you how Azure Blob storage can be used for storing large amounts of unstructured data and how to use it for orchestrating a data workflow. You'll then work with different Cosmos DB APIs and Azure SQL Database. Moving on, you'll discover how to provision an Azure Synapse database and find out how to ingest and analyze data in Azure Synapse. As you advance, you'll cover the design and implementation of batch processing solutions using Azure Data Factory, and understand how to manage, maintain, and secure Azure Data Factory pipelines. You’ll also design and implement batch processing solutions using Azure Databricks and then manage and secure Azure Databricks clusters and jobs. In the concluding chapters, you'll learn how to process streaming data using Azure Stream Analytics and Data Explorer.
By the end of this Azure book, you'll have gained the knowledge you need to be able to orchestrate batch and real-time ETL workflows in Microsoft Azure.
Table of Contents (11 chapters)
Preface

Chapter 1: Working with Azure Blob Storage
 Free Chapter
Free Chapter
Chapter 2: Working with Relational Databases in Azure
Chapter 3: Analyzing Data with Azure Synapse Analytics
Chapter 4: Control Flow Activities in Azure Data Factory
Chapter 5: Control Flow Transformation and the Copy Data Activity in Azure Data Factory
Chapter 6: Data Flows in Azure Data Factory
Chapter 7: Azure Data Factory Integration Runtime
Chapter 8: Deploying Azure Data Factory Pipelines
Chapter 9: Batch and Streaming Data Processing with Azure Databricks