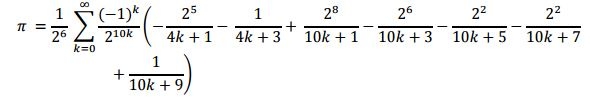The following are two exotic, rapidly converging, infinite series π equations from the famed Ramanujan and the Chudnovsky brothers. These turbocharged π equations require, at most, two iterations to give a π value of fifteen decimal place accuracy. The Chudnovsky brothers' equation was derived from Ramanujan's formula, and the Chudnovsky algorithm was used in December 2009 to calculate π to an accuracy of 2.7 trillion digit, five trillion digits in August 2010, ten trillion digits in October 2011, and 12.1 trillion digits in December 2013. For a more in-depth historical perspective, please see the following links:
The Ramanujan infinite series formula is as follows:
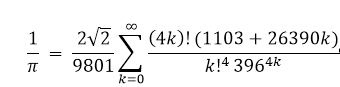
Its MPI code and how it runs are depicted on the following pages:
/*******************************************
* Ramanujan MPI pi code. *
* *
* This infinite seriesconverges rapidly. *
* Only two iterations for *
* 15 decimalplace accuracy. *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/11/2017 *
*******************************************/
#include<mpi.h>// (Open)MPI library
#include<math.h>// math library
#include<stdio.h>// Standard Input/Output library
int main(int argc, char*argv[])
{
int total_iter;
int n,rank,length,numprocs;
double pi,sum,sum0,x,rank_sum,A,B,C,D,E;
char hostname[MPI_MAX_PROCESSOR_NAME];
unsignedlong factorial(unsignedlong number);
unsignedlonglong i,j,k,l,m;
double F = 2.0*sqrt(2.0)/9801.0;
MPI_Init(&argc, &argv); // initiates MPI
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // acquire number of
processes
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // acquire current process id
MPI_Get_processor_name(hostname, &length); // acquire hostname
if (rank == 0)
{
printf("\n");
printf("#######################################################");
printf("\n\n\n");
printf("*** NUMBER OF PROCESSORS: %d\n",numprocs);
printf("\n\n");
printf("MASTER NODE NAME: %s\n", hostname);
printf("\n");
printf("Enter the number of iterations:\n");
printf("\n");
scanf("%d",&n);
printf("\n");
}
// broadcast to all processes, the number of segments you want
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
// this loop increments the maximum number of iterations, thus providing
// additional work for testing computational speed of the processors
// for(total_iter = 1; total_iter < n; total_iter++)
{
sum0 = 0.0;
// for(i = rank + 1; i <= total_iter; i += numprocs)
for(i = rank + 1; i <= n; i += numprocs)
{
k = i-1;
A = 1;
for(l=1; l <= 4*k; l++)// (4*k)!
{
A *= l;
}
B = (double)(1103+26390*k);
C = 1;
for(m=1; m <= k; m++)// k!
{
C *= m;
}
D = (double)pow(396,4*k);
E = (double)A*B/(C*D);
sum0 += E;
}// End of for(i = rank + 1; i <= total_iter; i += numprocs)
rank_sum = sum0;// Partial sum for a given rank
// collect and add the partial sum0 values from all processes
MPI_Reduce(&rank_sum, &sum, 1, MPI_DOUBLE,MPI_SUM, 0, MPI_COMM_WORLD);
} // End of for(total_iter = 1; total_iter < n; total_iter++)
if(rank == 0)
{
pi = 1.0/(F*sum);
printf("\n\n");
/* printf("*** Number of processes: %d\n",numprocs);
printf("\n\n");*/
printf(" Calculated pi = %.16f\n", pi);
printf(" M_PI = %.16f\n", M_PI);
printf(" Relative Error = %.16f\n", fabs(pi-M_PI));
}
// clean up, done with MPI
MPI_Finalize();
return 0;
}// End of int main(int argc, char*argv[])
alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8,
Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 Ramanujan
#######################################################
*** NUMBER OF PROCESSORS: 16
MASTER NODE NAME: Mst0
Enter the number of iterations:
2
Calculated pi = 3.1415926535897936
M_PI = 3.1415926535897931
Relative Error = 0.0000000000000004
real 0m8.974s
user 0m1.200s
sys 0m0.360sThe Chudnovsky infinite series formula is as follows:
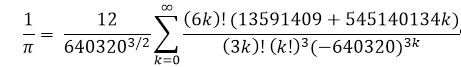
Its MPI code and how it runs are depicted on the following pages:
/*******************************************
* Chudnovsky MPI pi code. *
*
* This infinite series converges rapidly.*
* Only two iterations for 15 decimal *
* place accuracy. *
*
* Author: Carlos R. Morrison *
*
* Date: 1/11/2017 *
*******************************************/
#include<mpi.h>// (Open)MPI library
#include<math.h>// math library
#include<stdio.h>// Standard Input/Output library
int main(int argc, char*argv[])
{
int total_iter;
int n,rank,length,numprocs;
double pi;
double sum0,x,rank_sum,A,B,C,D,E,G,H;
double F = 12.0/pow(640320,1.5),sum;
unsignedlonglong i,j,k,l,m;
char hostname[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv); // initiates MPI
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // acquire number of
processes
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // acquire current process id
MPI_Get_processor_name(hostname, &length); // acquire hostname
if (rank == 0)
{
printf("\n");
printf("#######################################################");
printf("\n\n\n");
printf("*** NUMBER OF PROCESSORS: %d\n",numprocs);
printf("\n\n");
printf("MASTER NODE NAME: %s\n", hostname);
printf("\n");
printf("Enter the number of iterations:\n");
printf("\n");
scanf("%d",&n);
printf("\n");
}
// broadcast to all processes, the number of segments you want
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
// this loop increments the maximum number of iterations, thus
providing
// additional work for testing computational speed of the processors
// for(total_iter = 1; total_iter < n; total_iter++)
{
sum0 = 0.0;
// for(i = rank + 1; i <= total_iter; i += numprocs)
for(i = rank + 1; i <= n; i += numprocs)
{
k = i-1;
A = 1;
for(j=1; j <= 6*k; j++)// (6*k)!
{
A *= j;
}
B = (double)(13591409+545140134*k);
C = 1;
for(l=1; l <= 3*k; l++)// (3k)!
{
C *= l;
}
D = 1;
for(m=1; m <= k; m++)// k!
{
D *= m;
}
E = pow(D,3);// (k!)^3
G = (double)pow(-640320,3*k);
H = (double)A*B/(C*E*G);
sum0 += H;
}// End of for(i = rank + 1; i <= total_iter; i += numprocs)
rank_sum = sum0;// Partial sum for a given rank
// collect and add the partial sum0 values from all processes
MPI_Reduce(&rank_sum, &sum, 1, MPI_DOUBLE,MPI_SUM, 0,
MPI_COMM_WORLD);
} // End of for(total_iter = 1; total_iter < n; total_iter++)
if(rank == 0)
{
printf("\n\n");
// printf("*** Number of processes: %d\n",numprocs);
// printf("\n\n");
pi = 1.0/(F*sum);
printf(" Calculated pi = %.16f\n", pi);
printf(" M_PI = %.16f\n", M_PI);
printf(" Relative Error = %.16f\n", fabs(pi-M_PI));
}
// clean up, done with MPI
MPI_Finalize();
return 0;
}// End of int main(int argc, char*argv[])
alpha@Mst0:/beta/gamma $ time mpiexec -H
Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8,
Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 Chudnovsky
#######################################################
*** NUMBER OF PROCESSORS: 16
MASTER NODE NAME: Mst0
Enter the number of iterations:
2
Calculated pi = 3.1415926535897936
M_PI = 3.1415926535897931
Relative Error = 0.0000000000000004
real 0m5.155s
user 0m1.220s
sys 0m0.340s
alpha@Mst0:/beta/gamma $Go ahead, copy/write and the run the following codes; one of them is very efficient for the number of iteration required to generate a very accurate value for π:
Unknown:
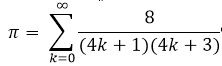
Simon Pluff:
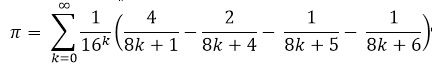
Fabrice — Bellard: