-
Book Overview & Buying

-
Table Of Contents

Apps and Services with .NET 8 - Second Edition
By :
Apps and Services with .NET 8
By:
Overview of this book
Elevate your practical C# and .NET skills to the next level with this new edition of Apps and Services with .NET 8.
With chapters that put a variety of technologies into practice, including Web API, gRPC, GraphQL, and SignalR, this book will give you a broader scope of knowledge than other books that often focus on only a handful of .NET technologies. You’ll dive into the new unified model for Blazor Full Stack and leverage .NET MAUI to develop mobile and desktop apps.
This new edition introduces the latest enhancements, including the seamless implementation of web services with ADO.NET SqlClient's native Ahead-of-Time (AOT) support. Popular library coverage now includes Humanizer and Noda Time. There’s also a brand-new chapter that delves into service architecture, caching, queuing, and robust background services.
By the end of this book, you’ll have a wide range of best practices and deep insights under your belt to help you build rich apps and efficient services.
*Email sign-up and proof of purchase required
Table of Contents (19 chapters)
Preface

Introducing Apps and Services with .NET
 Free Chapter
Free Chapter
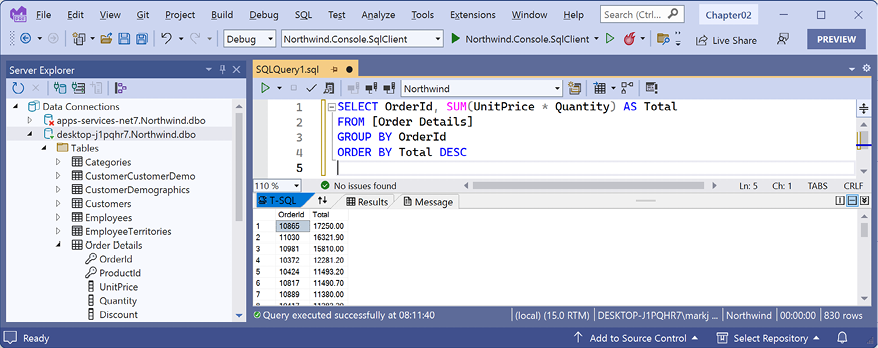
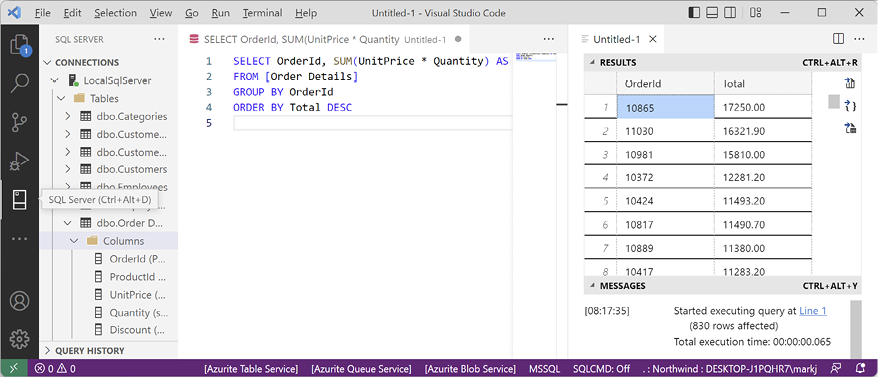
Managing Relational Data Using SQL Server
Building Entity Models for SQL Server Using EF Core
Managing NoSQL Data Using Azure Cosmos DB
Multitasking and Concurrency
Using Popular Third-Party Libraries
Handling Dates, Times, and Internationalization
Building and Securing Web Services Using Minimal APIs
Caching, Queuing, and Resilient Background Services
Building Serverless Nanoservices Using Azure Functions
Broadcasting Real-Time Communication Using SignalR
Combining Data Sources Using GraphQL
Building Efficient Microservices Using gRPC
Building Web User Interfaces Using ASP.NET Core
Building Web Components Using Blazor
Building Mobile and Desktop Apps Using .NET MAUI
Epilogue
Index