

Gearman is a network-based job-queuing system that was initially developed by Danga Interactive in order to process large volumes of jobs. Its primary design goals were low-latency remote function execution, being able to run code remotely and in parallel, load balancing of job distribution, and supporting writing components in multiple languages.
Although originally written in Perl it is comprised of, at its core, a network protocol that is designed to allow the various components to communicate the lifecycle of a unit of work. Because of this design, there are both servers and client libraries written in multiple languages including Ruby, Perl, PHP, Python, C, C++, and Java.
What this translates into is the ability to design and develop the various components of your architecture in whatever language makes the most sense and have those components communicate easily with one another.
Gearman goes one step further than simply defining a message bus; it formalizes its architecture to focus on units of work. This means that everything in a system using Gearman operates in terms of submitting or working on jobs. To follow this paradigm, Gearman has three main actors: clients who request that work be completed by somebody, the managers (servers) that are responsible for accepting jobs from clients, and then handing those jobs out to workers that ultimately complete the tasks.
At its core, Gearman is a network protocol; this means that it is not restricted to being used in any one programming language. In fact, there are clients for nearly every (if not every) modern programming language including Java, C#, Python, Perl, Ruby, C, C++, and PHP. If a library does not exist for your language of choice, the protocol is simple enough to rapidly implement at least the basic components required to submit and process jobs. The protocol is well documented and has a very clear request and response cycle.
One of the less obvious benefits of this is that your client can be written in a completely separate language from your worker. For example, a PHP-based web application can submit a request for a job to be processed that is handled by a highly optimized worker written in C for that specific type of task. This allows you to take advantage of the strengths of different languages, and prevents you from being locked into one language or another when building components of your system.
As mentioned before, processing jobs with Gearman requires three different actors:
Servers to receive and store jobs in a queue (also known as a manager)
Clients that submit jobs to the manager
Workers that process these jobs
These components do not need to be on separate machines, though as your system grows you will likely need to dedicate resources to these components to accommodate the growth. Initially, we will run everything on one system because it is the simplest, but we will discuss some options for architecture later on to grow your system from simple to complex.
A very simple view of the communication between the components of an application that uses Gearman looks something similar to the following diagram:
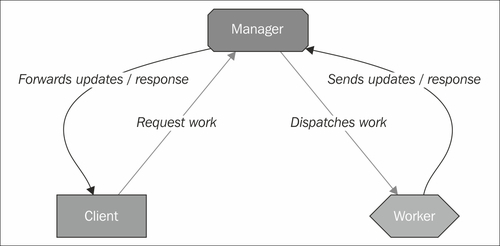
At no point do the worker and the client exchange messages directly; the architecture is designed so that the manager is the middleman and the authoritative source for storing and dispatching jobs.
Behind the scenes, the manager is responsible for storing the jobs in its internal queue. Which, depending on the server and the way it is configured, may or may not be backed by some persistent storage mechanism on disk, in case the server crashes (we will discuss this later on in the book). An example conversation might be as follows:
Client to Manager: I need someone to resize an image; here is the image file I need resized.
Manager to Client: OK, I can do that, I've written down your request.
Manager to Workers who have said they can resize images: Wake up! Someone needs some work done.
Worker to manager: I can do it, give me the next available job!
Manager to worker: Here you go, here is the job and the image to resize.
Worker to manager: All done! Here's the resized image data.
Manager to client: Here you go, your image is resized, here is the resized image.
It is important to note here that the image or some derivative thereof is transferred a total of four times: once from the client to the manager, once from the manager to the worker, and then the resulting resized image is passed back from the worker to the manager, and then from the manager to the client. You may have already noticed that this can quickly become a bottleneck (imagine passing a 1 GB image and a 200 MB resized image back and forth, you've now had to shuffle 2.4 GB of data around).
On top of the data being transferred, the manager may hold this data in memory while it waits for a worker to accept and complete the job. This would mean that you could only queue up a few of these jobs at once without causing the server that is running the manager to start swapping to disk and either significantly degrading performance or running out of memory completely. As you build your systems, try to keep the data that is being passed back and forth as small as possible. One solution to this particular scenario would be to write the image data to a shared data store such as an NFS share or an S3 bucket and pass a path or URL between the client and worker rather than a complete image file.
Image processing is a CPU and IO-bound process. Images need to be loaded from disk into memory and then processed. This often cannot happen in real-time or within the bounds of a normal HTTP request-response cycle. Additionally, some image processing software can benefit from specialized server instances that have access to GPUs for higher throughput image processing. However, these instances can be very cost prohibitive for running as a general-purpose web server. By using Gearman we cannot only achieve a greater level of parallelism, thereby aiding with horizontal scaling, but also be able to use specialized systems to their greatest advantage and optimize the use of resources.
In this case, imagine a web application that provides a web-based photo gallery that needs to accept and resize numerous images from clients. If each image takes 30 seconds to resize, even if the web server were capable of processing 50 requests simultaneously at that rate by performing inline resizing, then the application would only be able to serve just short of two requests per second. In order to be usable, the application must be able to accept and process images as quickly as possible.
In a more advanced architecture, the web server could accept an image from the client, persist the image to a shared data store, and then submit an asynchronous request to the job manager to have the image resized by an available worker. By offloading the image processing as a background task, the web application can respond to client requests much more quickly, thereby allowing the client to store more images while the previously uploaded images are being processed in parallel.
The full sequence diagram for uploading an image using this type of system would resemble the following:
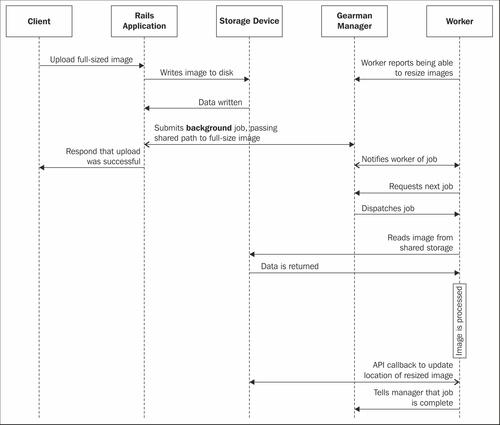
You will notice that the conversation between the end user's client (a web browser in this case) and the web server is very brief, much shorter than it would be if the image processing were to happen in-line with the client's request. For web developers, learning to leverage this type of solution can help to make their application much more responsive by offloading anything that may require significant time, and does not need to be completed synchronously, to the background such as post-sign up API calls, data analysis, image processing, web crawling, and so on are examples of processes that could be performed asynchronously.
Though this usecase examines using Gearman from the context of a web application, it is by no means restricted to being used only by web applications. There are many situations where an application could benefit from using Gearman. Those situations include systems that:
Have deadlines within which they have to deliver a response to the user or suffer from a lack of usability. Examples of this are web applications and mobile applications.
Operate with limited resources, such as cloud servers, mobile devices, or other systems that may have limited storage or processing power.
Work on vast amounts of data and require the ability to process data in parallel, such as geospatial data, large quantities of log or transaction data, and so on.
Require, for security purposes, that business logic or other sensitive data and software is to be kept on different servers or networks and so the customer-facing systems cannot complete the request fully by themselves.
Process large quantities of small jobs, possibly upwards of millions of jobs per day.
Are written using a variety of languages, each suited to a particular task, to solve the problem as a whole and needs a way to pass data between the various components.
Throughout this book we will look at how you can leverage Gearman as a critical part of your infrastructure to build services that are more flexible and can scale horizontally as the demand on the system increases.