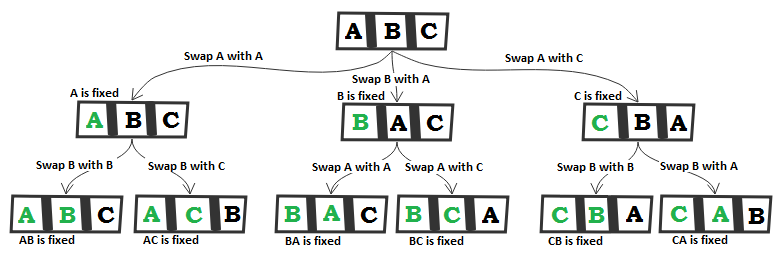
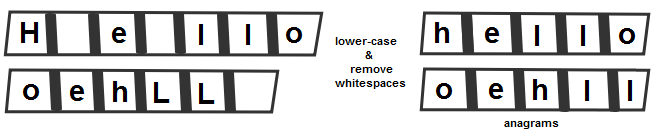
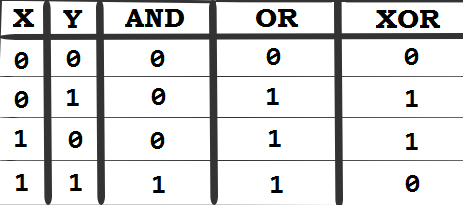
The following sections describe solutions to the preceding problems. Remember that there usually isn't a single correct way to solve a particular problem. Also, remember that the explanations shown here only include the most interesting and important details needed to solve the problems. You can download the example solutions to see additional details and experiment with the programs from https://github.com/PacktPublishing/Java-Coding-Problems.
-
Book Overview & Buying

-
Table Of Contents

Java Coding Problems
By :
Java Coding Problems
By:
Overview of this book
The super-fast evolution of the JDK between versions 8 and 12 has increased the learning curve of modern Java, therefore has increased the time needed for placing developers in the Plateau of Productivity. Its new features and concepts can be adopted to solve a variety of modern-day problems. This book enables you to adopt an objective approach to common problems by explaining the correct practices and decisions with respect to complexity, performance, readability, and more.
Java Coding Problems will help you complete your daily tasks and meet deadlines. You can count on the 300+ applications containing 1,000+ examples in this book to cover the common and fundamental areas of interest: strings, numbers, arrays, collections, data structures, date and time, immutability, type inference, Optional, Java I/O, Java Reflection, functional programming, concurrency and the HTTP Client API. Put your skills on steroids with problems that have been carefully crafted to highlight and cover the core knowledge that is accessed in daily work. In other words (no matter if your task is easy, medium or complex) having this knowledge under your tool belt is a must, not an option.
By the end of this book, you will have gained a strong understanding of Java concepts and have the confidence to develop and choose the right solutions to your problems.
Table of Contents (15 chapters)
Preface
Objects, Immutability, and Switch Expressions
Working with Date and Time
Type Inference
Arrays, Collections, and Data Structures
Java I/O Paths, Files, Buffers, Scanning, and Formatting
Java Reflection Classes, Interfaces, Constructors, Methods, and Fields
Functional Style Programming - Fundamentals and Design Patterns
Functional Style Programming - a Deep Dive
Concurrency - Thread Pools, Callables, and Synchronizers
Concurrency - Deep Dive
The HTTP Client and WebSocket APIs
Other Books You May Enjoy