-
Book Overview & Buying

-
Table Of Contents

Domain-Driven Design with Java - A Practitioner's Guide
By :
Domain-Driven Design with Java - A Practitioner's Guide
By:
Overview of this book
Domain-Driven Design (DDD) makes available a set of techniques and patterns that enable domain experts, architects, and developers to work together to decompose complex business problems into a set of well-factored, collaborating, and loosely coupled subsystems.
This practical guide will help you as a developer and architect to put your knowledge to work in order to create elegant software designs that are enjoyable to work with and easy to reason about. You'll begin with an introduction to the concepts of domain-driven design and discover various ways to apply them in real-world scenarios. You'll also appreciate how DDD is extremely relevant when creating cloud native solutions that employ modern techniques such as event-driven microservices and fine-grained architectures. As you advance through the chapters, you'll get acquainted with core DDD’s strategic design concepts such as the ubiquitous language, context maps, bounded contexts, and tactical design elements like aggregates and domain models and events. You'll understand how to apply modern, lightweight modeling techniques such as business value canvas, Wardley mapping, domain storytelling, and event storming, while also learning how to test-drive the system to create solutions that exhibit high degrees of internal quality.
By the end of this software design book, you'll be able to architect, design, and implement robust, resilient, and performant distributed software solutions.
Table of Contents (17 chapters)
Preface

Part 1: Foundations
 Free Chapter
Free Chapter
Chapter 1: The Rationale for Domain-Driven Design
Chapter 2: Where and How Does DDD Fit?
Part 2: Real-World DDD
Chapter 3: Understanding the Domain
Chapter 4: Domain Analysis and Modeling
Chapter 5: Implementing Domain Logic
Chapter 6: Implementing the User Interface – Task-Based
Chapter 7: Implementing Queries
Chapter 8: Implementing Long-Running Workflows
Chapter 9: Integrating with External Systems
Part 3: Evolution Patterns
Chapter 10: Beginning the Decomposition Journey
Chapter 11: Decomposing into Finer-Grained Components
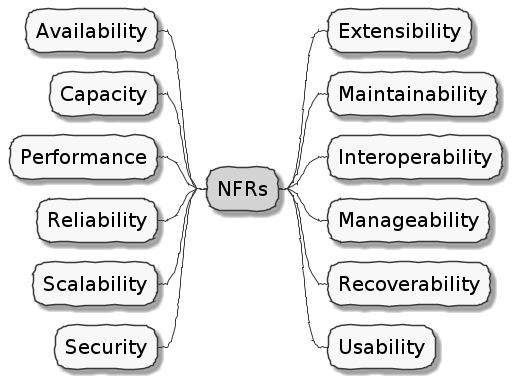
Chapter 12: Beyond Functional Requirements
Other Books You May Enjoy