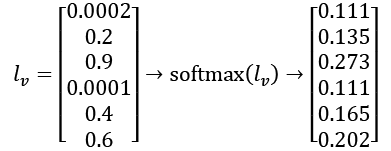-
Book Overview & Buying

-
Table Of Contents

Artificial Intelligence By Example - Second Edition
By :
Artificial Intelligence By Example
By:
Overview of this book
AI has the potential to replicate humans in every field. Artificial Intelligence By Example, Second Edition serves as a starting point for you to understand how AI is built, with the help of intriguing and exciting examples.
This book will make you an adaptive thinker and help you apply concepts to real-world scenarios. Using some of the most interesting AI examples, right from computer programs such as a simple chess engine to cognitive chatbots, you will learn how to tackle the machine you are competing with. You will study some of the most advanced machine learning models, understand how to apply AI to blockchain and Internet of Things (IoT), and develop emotional quotient in chatbots using neural networks such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs).
This edition also has new examples for hybrid neural networks, combining reinforcement learning (RL) and deep learning (DL), chained algorithms, combining unsupervised learning with decision trees, random forests, combining DL and genetic algorithms, conversational user interfaces (CUI) for chatbots, neuromorphic computing, and quantum computing.
By the end of this book, you will understand the fundamentals of AI and have worked through a number of examples that will help you develop your AI solutions.
Table of Contents (23 chapters)
Preface

Getting Started with Next-Generation Artificial Intelligence through Reinforcement Learning
 Free Chapter
Free Chapter
Building a Reward Matrix – Designing Your Datasets
Machine Intelligence – Evaluation Functions and Numerical Convergence
Optimizing Your Solutions with K-Means Clustering
How to Use Decision Trees to Enhance K-Means Clustering
Innovating AI with Google Translate
Optimizing Blockchains with Naive Bayes
Solving the XOR Problem with a Feedforward Neural Network
Abstract Image Classification with Convolutional Neural Networks (CNNs)
Conceptual Representation Learning
Combining Reinforcement Learning and Deep Learning
AI and the Internet of Things (IoT)
Visualizing Networks with TensorFlow 2.x and TensorBoard
Preparing the Input of Chatbots with Restricted Boltzmann Machines (RBMs) and Principal Component Analysis (PCA)
Setting Up a Cognitive NLP UI/CUI Chatbot
Improving the Emotional Intelligence Deficiencies of Chatbots
Genetic Algorithms in Hybrid Neural Networks
Neuromorphic Computing
Quantum Computing
Answers to the Questions
Other Books You May Enjoy
Index
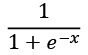
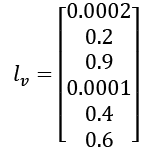
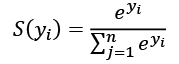
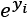 is the exp(i) result of each value in
is the exp(i) result of each value in 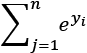 is the sum of
is the sum of 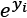 as shown in the following code:
as shown in the following code: