

OpenCL standard was first introduced by Apple, and later on became part of the open standards organization "Khronos Group". It is a non-profit industry consortium, creating open standards for the authoring, and acceleration of parallel computing, graphics, dynamic media, computer vision and sensor processing on a wide variety of platforms and devices.
The goal of OpenCL is to make certain types of parallel programming easier, and to provide vendor agnostic hardware-accelerated parallel execution of code. OpenCL (Open Computing Language) is the first open, royalty-free standard for general-purpose parallel programming of heterogeneous systems. It provides a uniform programming environment for software developers to write efficient, portable code for high-performance compute servers, desktop computer systems, and handheld devices using a diverse mix of multi-core CPUs, GPUs, and DSPs.
OpenCL gives developers a common set of easy-to-use tools to take advantage of any device with an OpenCL driver (processors, graphics cards, and so on) for the processing of parallel code. By creating an efficient, close-to-the-metal programming interface, OpenCL will form the foundation layer of a parallel computing ecosystem of platform-independent tools, middleware, and applications.
We mentioned vendor agnostic, yes that is what OpenCL is about. The different vendors here can be AMD, Intel, NVIDIA, ARM, TI, and so on. The following diagram shows the different vendors and hardware architectures which use the OpenCL specification to leverage the hardware capabilities:
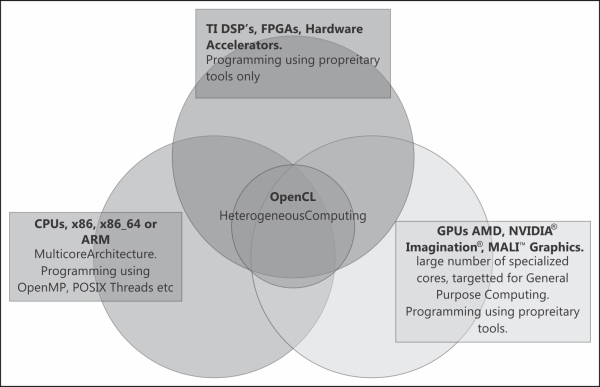
The heterogeneous system
The OpenCL framework defines a language to write "kernels". These kernels are functions which are capable of running on different compute devices. OpenCL defines an extended C language for writing compute kernels, and a set of APIs for creating and managing these kernels. The compute kernels are compiled with a runtime compiler, which compiles them on-the-fly during host application execution for the targeted device. This enables the host application to take advantage of all the compute devices in the system with a single set of portable compute kernels.
Based on your interest and hardware availability, you might want to do OpenCL programming with a "host and device" combination of "CPU and CPU" or "CPU and GPU". Both have their own programming strategy. In CPUs you can run very large kernels as the CPU architecture supports out-of-order instruction level parallelism and have large caches. For the GPU you will be better off writing small kernels for better performance. Performance optimization is a huge topic in itself. We will try to discuss this with a case study in Chapter 8, Basic Optimization Techniques with Case Study
There are various hardware vendors who support OpenCL. Every OpenCL vendor provides OpenCL runtime libraries. These runtimes are capable of running only on their specific hardware architectures. Not only across different vendors, but within a vendor there may be different types of architectures which might need a different approach towards OpenCL programming. Now let's discuss the various hardware vendors who provide an implementation of OpenCL, to exploit their underlying hardware.
With the launch of AMD A Series APU, one of industry's first Accelerated Processing Unit (APU), AMD is leading the efforts of integrating both the x86_64 CPU and GPU dies in one chip. It has four cores of CPU processing power, and also a four or five graphics SIMD engine, depending on the silicon part which you wish to buy. The following figure shows the block diagram of AMD APU architecture:
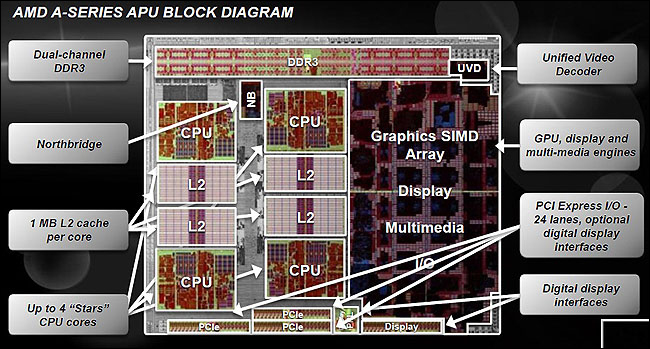
AMD architecture diagram—© 2011, Advanced Micro Devices, Inc.
An AMD GPU consist of a number of Compute Engines (CU) and each CU has 16 ALUs. Further, each ALU is a VLIW4 SIMD processor and it could execute a bundle of four or five independent instructions. Each CU could be issued a group of 64 work items which form the work group (wavefront). AMD Radeon ™ HD 6XXX graphics processors uses this design. The following figure shows the HD 6XXX series Compute unit, which has 16 SIMD engines, each of which has four processing elements:

AMD Radeon HD 6xxx Series SIMD Engine—© 2011, Advanced Micro Devices, Inc.
Starting with the AMD Radeon HD 7XXX series of graphics processors from AMD, there were significant architectural changes. AMD introduced the new Graphics Core Next (GCN) architecture. The following figure shows an GCN compute unit which has 4 SIMD engines and each engine is 16 lanes wide:

GCN Compute Unit—© 2011, Advanced Micro Devices, Inc.
A group of these Compute Units forms an AMD HD 7xxx Graphics Processor. In GCN, each CU includes four separate SIMD units for vector processing. Each of these SIMD units simultaneously execute a single operation across 16 work items, but each can be working on a separate wavefront.
Apart from the APUs, AMD also provides discrete graphics cards. The latest family of graphics card, HD 7XXX, and beyond uses the GCN architecture. We will discuss one of the discrete GPU architectures in the following chapter, where we will discuss the OpenCL Platform model. AMD also provides the OpenCL runtimes for their CPU devices.
One of NVIDIA GPU architectures is codenamed "Kepler". GeForce® GTX 680 is one Kepler architectural silicon part. Each Kepler GPU consists of different configurations of Graphics Processing Clusters (GPC) and streaming multiprocessors. The GTX 680 consists of four GPCs and eight SMXs as shown in the following figure:
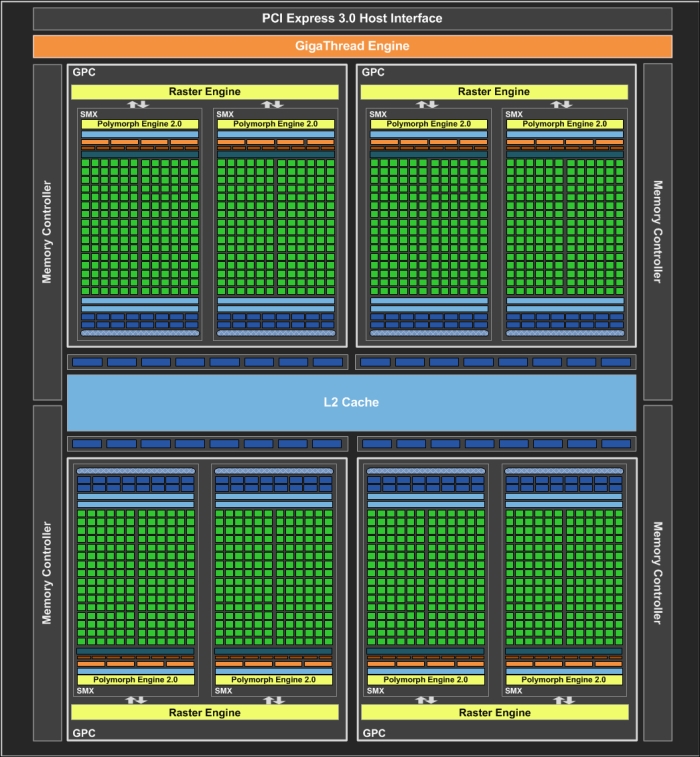
NVIDIA Kepler architecture—GTX 680, © NVIDIA®
Kepler architecture is part of the GTX 6XX and GTX 7XX family of NVIDIA discrete cards. Prior to Kepler, NVIDIA had Fermi architecture which was part of the GTX 5XX family of discrete and mobile graphic processing units.
Intel's OpenCL implementation is supported in the Sandy Bridge and Ivy Bridge processor families. Sandy Bridge family architecture is also synonymous with the AMD's APU. These processor architectures also integrated a GPU into the same silicon as the CPU by Intel. Intel changed the design of the L3 cache, and allowed the graphic cores to get access to the L3, which is also called as the last level cache. It is because of this L3 sharing that the graphics performance is good in Intel. Each of the CPUs including the graphics execution unit is connected via Ring Bus. Also each execution unit is a true parallel scalar processor. Sandy Bridge provides the graphics engine HD 2000, with six Execution Units (EU), and HD 3000 (12 EU), and Ivy Bridge provides HD 2500(six EU) and HD 4000 (16 EU). The following figure shows the Sandy bridge architecture with a ring bus, which acts as an interconnect between the cores and the HD graphics:
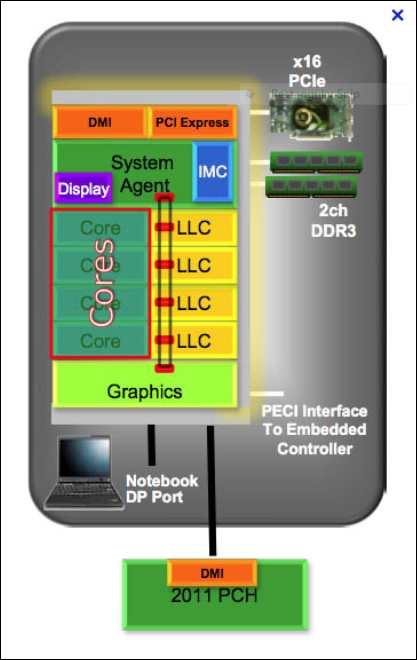
Intel Sandy Bridge architecture—© Intel®
ARM also provides GPUs by the name of Mali Graphics processors. The Mali T6XX series of processors come with two, four, or eight graphics cores. These graphic engines deliver graphics compute capability to entry level smartphones, tablets, and Smart TVs. The below diagram shows the Mali T628 graphics processor.
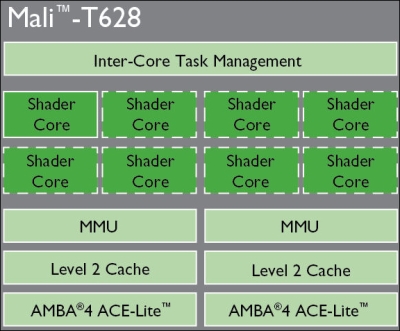
ARM Mali—T628 graphics processor, © ARM
Mali T628 has eight shader cores or graphic cores. These cores also support Renderscripts APIs besides supporting OpenCL.
Besides the four key competitors, companies such as TI (DSP), Altera (FPGA), and Oracle are providing OpenCL implementations for their respective hardware. We suggest you to get hold of the benchmark performance numbers of the different processor architectures we discussed, and try to compare the performance numbers of each of them. This is an important first step towards comparing different architectures, and in the future you might want to select a particular OpenCL platform based on your application workload.