

Now we have backend developers, database architects, frontend developers, and architects all working on the same project.
Development issues
Configuration and maintenance hazards
Now, some of the developers in the team realize that there is a need for each type of service to use its own persistence mechanism. The data received by querying Stack Overflow is by itself very complete (suppose there is a developer who has 10 k points only under the Scala tag; now, this by itself provides a summary of the user). So, this information can be easily stored using any standard relational database.
However, the same might not apply for GitHub, where it could get complex, as a project can have multiple developers and each developer can contribute to multiple projects with varying contributions. Developers decide that Neo4J (https://neo4j.com/), a graph database, best fits the schema to persist data associated with GitHub.
The LinkedIn based implementation might settle with a relational database again, but might use MongoDB to store the preprocessed response so that it is faster to respond with JSON rather than building it again and again.
Worse, all three of them might use a different caching mechanism to store their results. So, the reliance of different technologies has increased in the application. This means the configuration setup, such as URL and port, the authentication mechanism with the database, the database connection pool size, the default time zone to be used by the database, and other configurations have significantly increased.
This is only the backend part of our application. In the frontend, we might use CoffeeScript or Scala.js, coupled with some JavaScript framework, such as Angular, to develop responsive user interfaces.
Because it is one large application that is doing everything, the developers working on one thing cannot turn their backs on other modules. If some configuration is set incorrectly, and throws an exception when a module is started or, worse, does not let the whole application start or causes a build failure, it results in a waste in productivity and can seriously impact the morale of the developers at large.
By the end, the number of configurations have increased.
Modularity is lost.
We have defined service objects that provide us top developers for respective locations and technologies for each of Stack Overflow, LinkedIn, and GitHub. These service objects rely on the following:
- Data Access Objects to obtain information from the persistence storage.
- Cache objects to cache content. Multiple services might refer to the same cache objects for caching. For example, the same in-memory cache may be used to cache data associated with LinkedIn and Stack Overflow.
These service objects may then be used by different parts of our application, such as controllers that receive HTTP requests from the users.
The user information is also stored in relational database. The SQL Database was used to store Stack Overflow data, so we decide to use the same SQL instance to persist user information, as well as reuse the same database drivers, database authentication, connection pooling, transaction managers, and so on. Worse, we could use a common class, as nothing stops us from not preventing it.
With increasing functionality, the intended boundary designed initially gets lost. The same class may be used by multiple modules to avoid code duplication. Everything in the application starts using everything else.
All this makes refactoring the code harder, as any changes in behavior of a class may knowingly or unknowingly impact on so many different modules. Also, as the code base grows bigger, the probability of code duplication increases as it is difficult to keep track of a replicated effort.
Difficult to get started
People leaving teams and new people joining happens all the time. Ideally, for a new person joining the team, it should be straightforward to get started with development. As the configuration and maintenance gets messier, and the modularity is lost, it becomes difficult to get started.
A lack of modularity makes it necessary for developers to become well accustomed with the complete code base, even if one intends to work on a single module in the project. Due to this, the time needed for a new recruit in the team to contribute to a project increases by months.
New functionality
Our current system ranks developers based only on Stack Overflow, LinkedIn, and GitHub. We now decide to also include Topcoder, Kaggle, and developer blogs in our ranking criteria. This means that we will increase our code base size by incorporating newer classes, with reliance on newer/existing databases, caching infrastructure, additions to the list of periodic background cron jobs, and data maintenance. The list is unending.
In an ideal setup, given a set of modules, m1, m2, m3 .... mn, we would want the net developmental complexity to be Max(m1, m2, m3 ,,,,, mn). Or m1 + m2 + m3 + ... mn. However, in case of our application, it tends to be m1 * m2 * m3 * mn. That is, the complexity is dramatically increasing with the addition of new functionalities.
A single module can affect every other module; two developers working on different modules might knowingly or unknowingly affect each other in so many possible ways. A single incorrect commit by a developer (and a mistake missed by the reviewer), might not only impact his module but everything else (for example, an application startup failure due to a module affects every other module in the application).
All of this makes it very difficult to start working on a new functionality in code base as the complexity keeps increasing.
With time, if a decision gets taken to expand the application search engine to not only include developers but also creative artists and photographers, it will become a daunting task to quickly come up with newer functionalities. This will lead to increasing costs, and worse, losing business due to delays in development time.
Restart and update
A user reports a bug with the application and you realize that the bug is associated specifically with the Stack Overflow engine we have created. The developers in your team quickly find the fix in the Stack Overflow engine and are ready to deploy it in production. However, in disarray, we will need to restart the complete application. Restarting the application is overkill, as the change only affects one particular module.
These are very common scenarios in software development. The bigger the application, the greater the number of reasons for bugs and their fixes, and of course, the application restarts (unless the language provides hot swapping as a first class functionality).
Hot swapping is the ability to alter the running code of a program without needing to interrupt its execution. Erlang is a well-known example that provides the ability to hot swap. In Erlang, one can simply recompile and load the new version at runtime. This feature makes Erlang very attractive for applications that need near 100% availability in telecom and banking. Common Lisp is another such example.
For JVM, Zeroturnaround's proprietary JRebel offers the functionality to hot swap Java code (method bodies, instance variables, and others) at runtime. Because JVM by itself does not provide an interface inbuilt to exhibit it, JRebel applies multiple levels of smartness by the dynamic class rewriting at runtime and JVM integration to version individual classes. In short, it uses very complex yet impressive strategies to exhibit hot swapping, which is not a first class feature in JVM. Although, as a side effect, JRebel is mostly used for faster development to avoid restarts and not normally in production.
Testing and deployment
We now have one giant application that does everything. It relies on a number of frontend modules, frameworks, databases, build scripts, and other infrastructure with ton of configurations.
All this not only makes integration testing difficult, but also makes the deployment process frustrating and error prone. The startup time would significantly increase as the number of operations increase. This, in most cases, would also apply for test cases where the application context loading time would impact the time it takes to start running test cases, thus leading to a loss of developer productivity.
Moreover, there can always be a range of hiccups. In between version upgrades, there might be a range of database operations that need to be performed. There might be single or multiple SQL files that contain the set of SQLs to be run for version upgrades. Multiple modules might have a different set of SQL files. Although, sometimes, due to eventual tight integration, a few of the modules might rely on common tables. Any schema/DML upgrades on the table by one module might unintentionally impact other modules. In such cases, the change has to be appropriately communicated to other teams. Worse, we might not know all the affected teams and this would lead to a production failure.
Scalability
The famous Pokemon Go mobile app had 15 million global downloads within a week of its launch. On August 3, in Japan, people watched an airing of Castle in the Sky. At one point, they took to Twitter so much that it hit a one-second peak of 143,199 tweets per second. The average then was 5,700 tweets per second; thus, there was a 25 times increase in traffic all of a sudden (https://blog.twitter.com/2013/new-tweets-per-second-record-and-how).
In technology businesses, such events are not rare. Although the surge might not be as dramatic as Twitter's, it can nonetheless be significantly higher than anticipated. Our application design is not designed to be scalable. As the load increases, we might vertically scale by adding more memory and CPU, but this cannot be done forever. What if the application goes down or a database starts misbehaving, taking eternally long to respond?
Apart from adding memory and CPU, we could scale it horizontally by having multiple instances of the same application running and a load balancer could route requests to different servers based on the load on individual servers (the application server with the lower load could be routed to more traffic). However, this leaves a lot of unanswered questions:
- What do we do with our databases? Will we have a single database that multiple application servers access? If we go with this setup, then a higher load on this database server would affect all the cloned servers, ultimately increasing the response time of all the servers as they all access the same database.
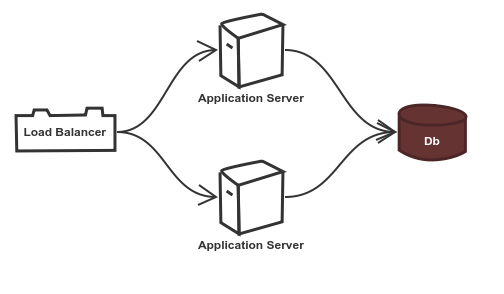
- Do we have a separate database for each application server? Then how do we deal with the consistency issues across databases? The data written on one database would have to be copied to the other database server for consistency. What happens if the data was not timely copied and the user requested the data?
- To solve this problem, a solution could be to ensure that the application servers interact timely with each other to sync up. What if there is a network partition and the application servers cannot access each other? What happens to the consistency issues in such scenarios?
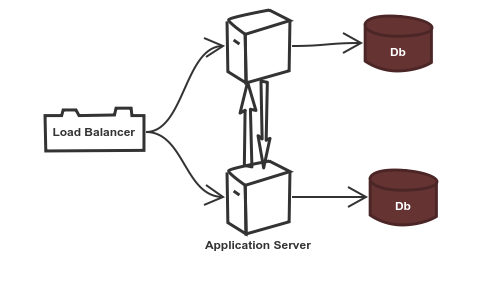
- How many servers do we have installed? If we install more, but the traffic load is low, then it results in wastage of resources and money (at the time of writing, a standard 8 core 32 GB RAM instance would cost 4,200 USD per annum on Amazon Web Services (AWS)).
In short, our current setup is ill-equipped to scale. It needs to be redesigned from the ground up to handle different ranges of issues, and not an ad hoc mechanism to fix it. What if you scale from 10 to 100,000 requests per minute without a complete revamp effort, but just a configuration change? This ability has to be incorporated as an abstraction and designed to scale from ground zero.
Sudden higher load are opportunities to excel as business. You would not want the application to fail when many users try accessing it for the first time. It would be an opportunity lost.