When I first learned about the concept of microservices back in 2014, I realized that I had been developing microservices (well, kind of) for a number of years without knowing it was microservices I was dealing with. I was involved in a project that started in 2009 where we developed a platform based on a set of separated features. The platform was delivered to a number of customers that deployed it on-premise. To make it easy for the customers to pick and choose what features they wanted to use from the platform, each feature was developed as an autonomous software component; that is, it had its own persistent data and only communicated with other components using well-defined APIs.
Since I can't discuss specific features in this project's platform, I have generalized the names of the components, which are labeled from Component A to Component F. The composition of the platform into a set of components is illustrated as follows:
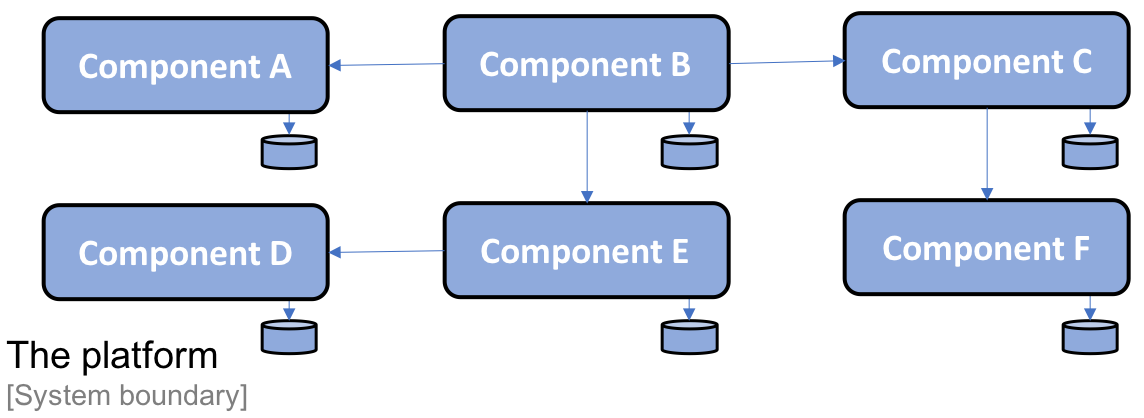
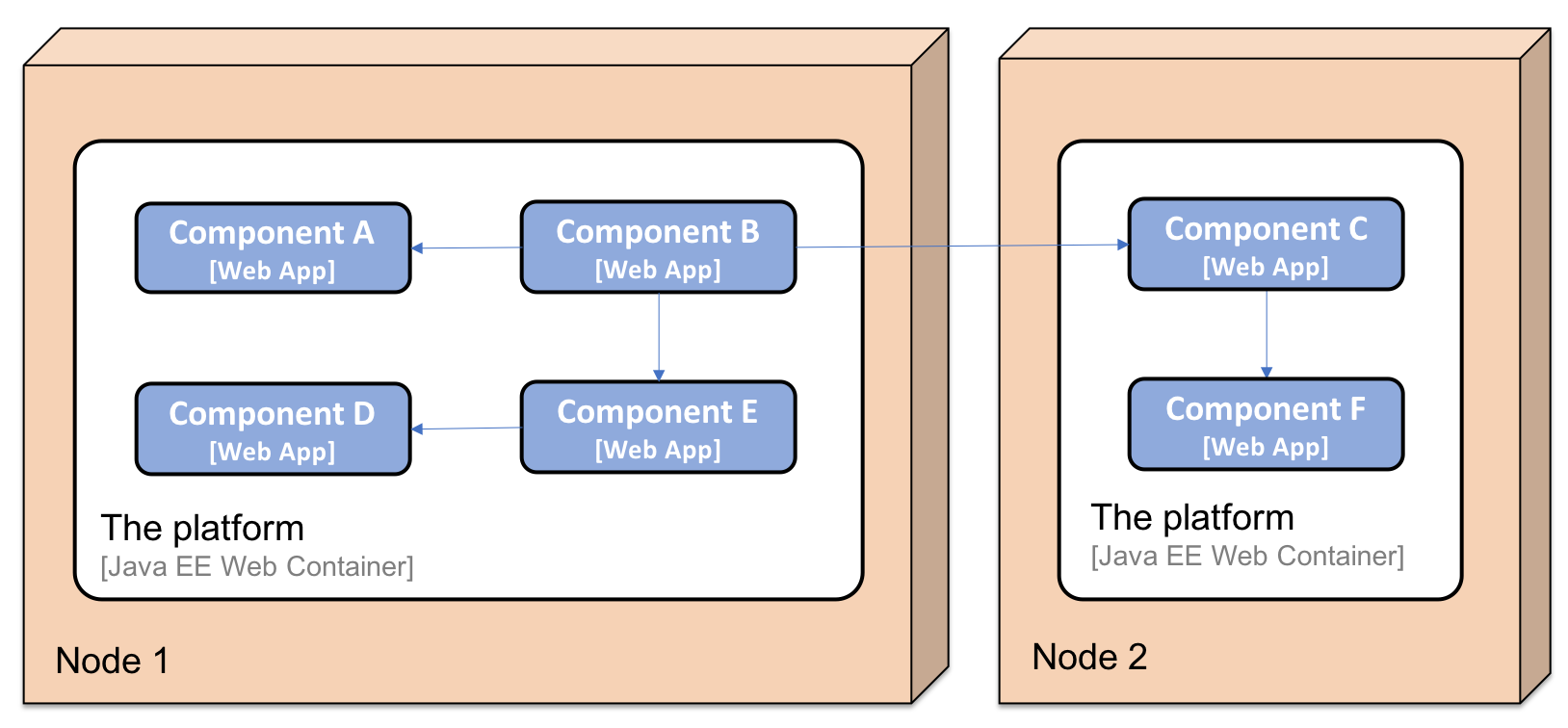
Each component is developed using Java and the Spring Framework, and is packaged as a WAR file and deployed as a web app in a Java EE web container, for example, Apache Tomcat. Depending on the customer's specific requirements, the platform can be deployed on single or multiple servers. A two-node deployment may look as follows:
Decomposing the platform's functionality into a set of autonomous software components provides a number of benefits:
- A customer can deploy parts of the platform in its own system landscape, integrating it with its existing systems using its well-defined APIs.
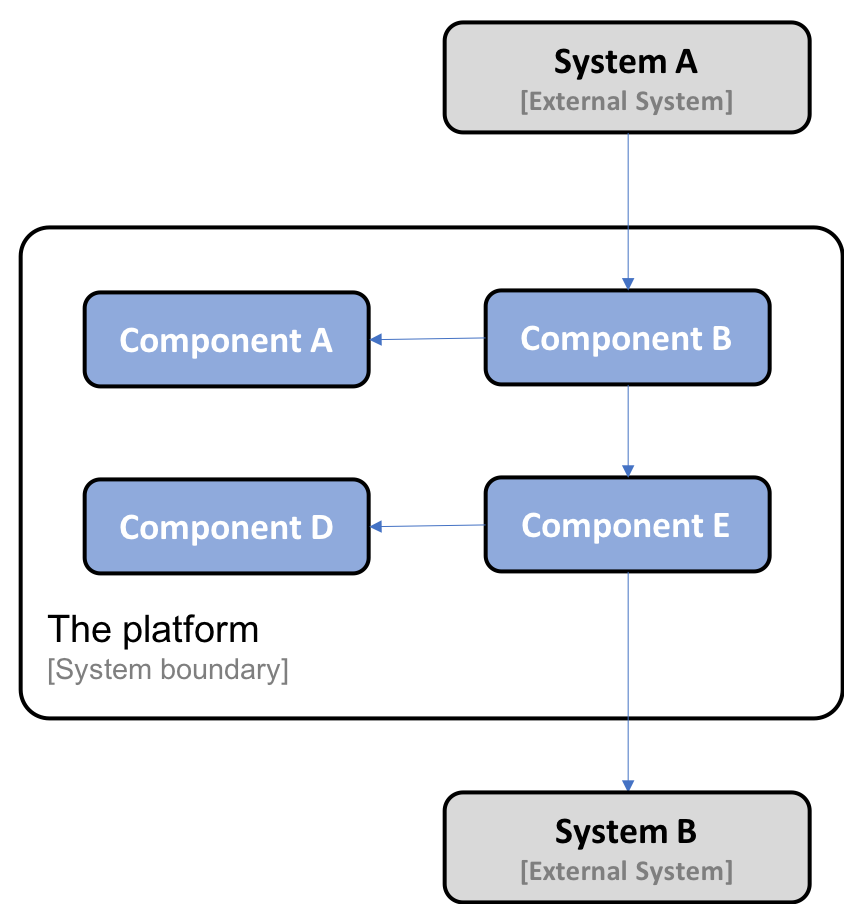
The following is an example where one customer decided to deploy Component A, Component B, Component D, and Component E from the platform and integrate them with two existing systems in the customer's system landscape, System A and System B:
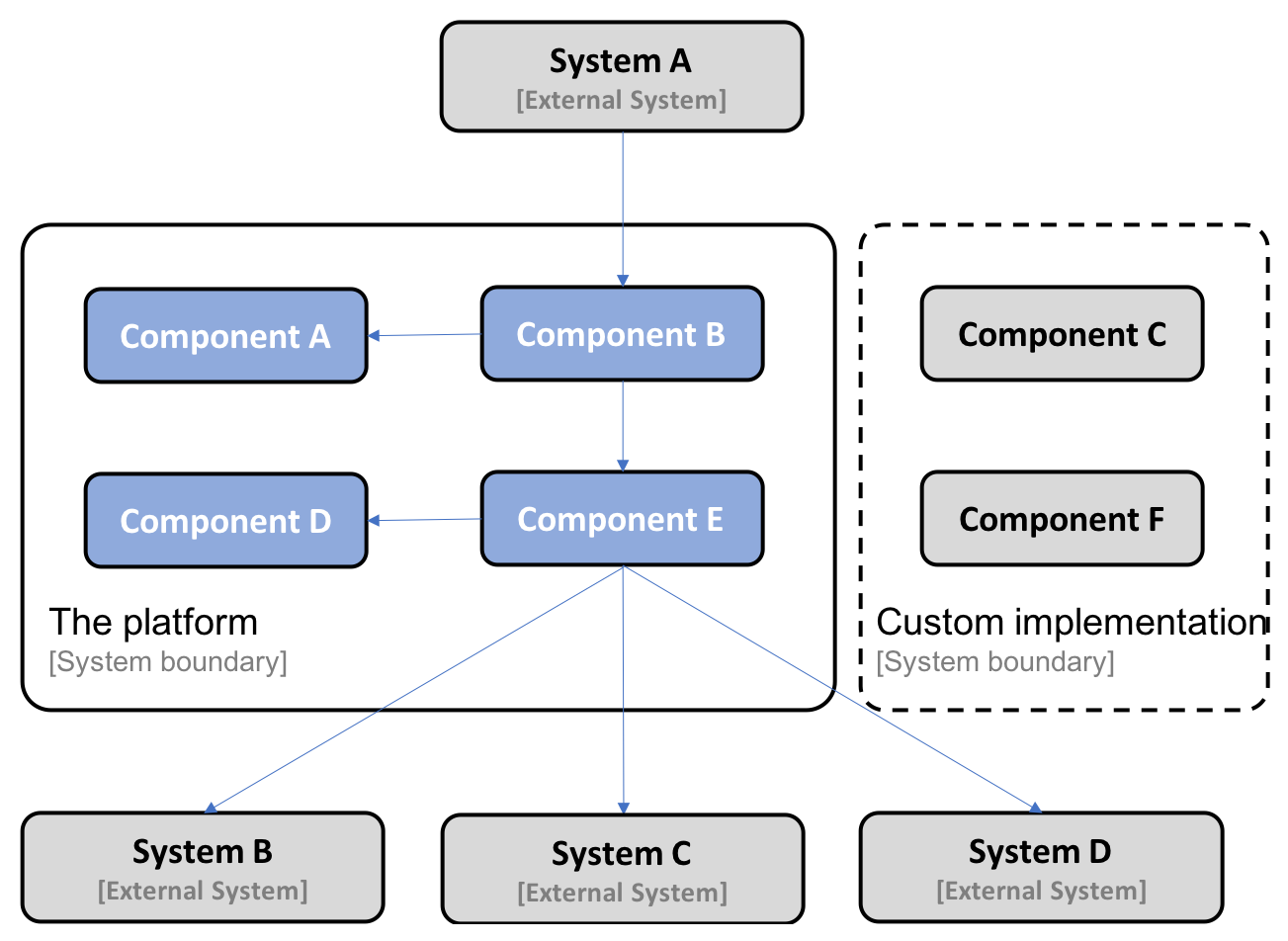
- Another customer can choose to replace parts of the platform's functionality with implementations that already exist in the customer's system landscape, potentially requiring some adoption of the existing functionality in the platform's APIs. The following is an example where a customer has replaced Component C and Component F in the platform with their own implementation:
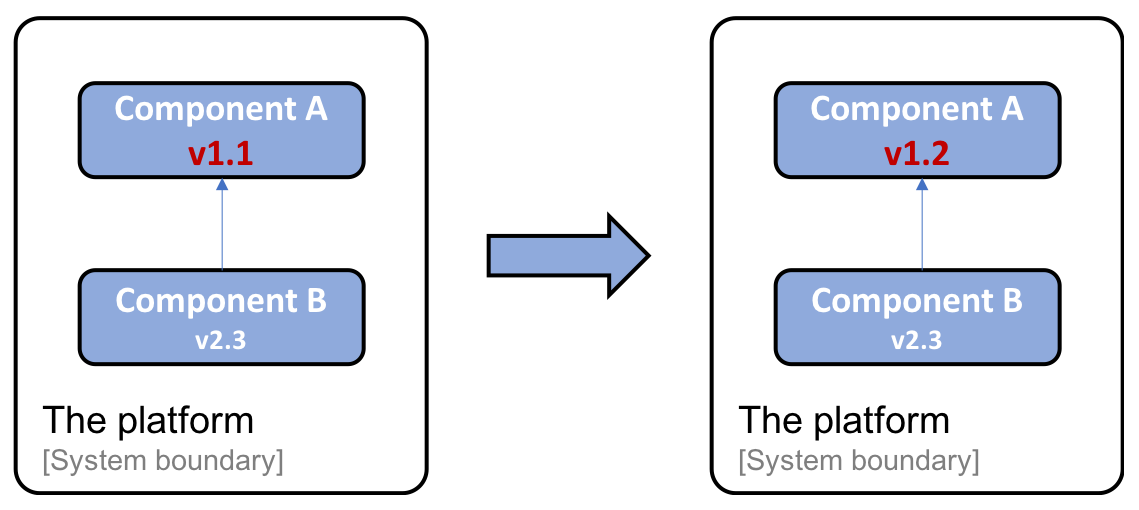
- Each component in the platform can be delivered and upgraded separately. Thanks to using well-defined APIs, one component can be upgraded to a new version without being dependent on the life cycle of the other components.
The following is an example where Component A has been upgraded from version v1.1 to v1.2. Component B, which calls Component A, does not need to be upgraded since it uses a well-defined API; that is, it's still the same after the upgrade (or it's at least backward-compatible):
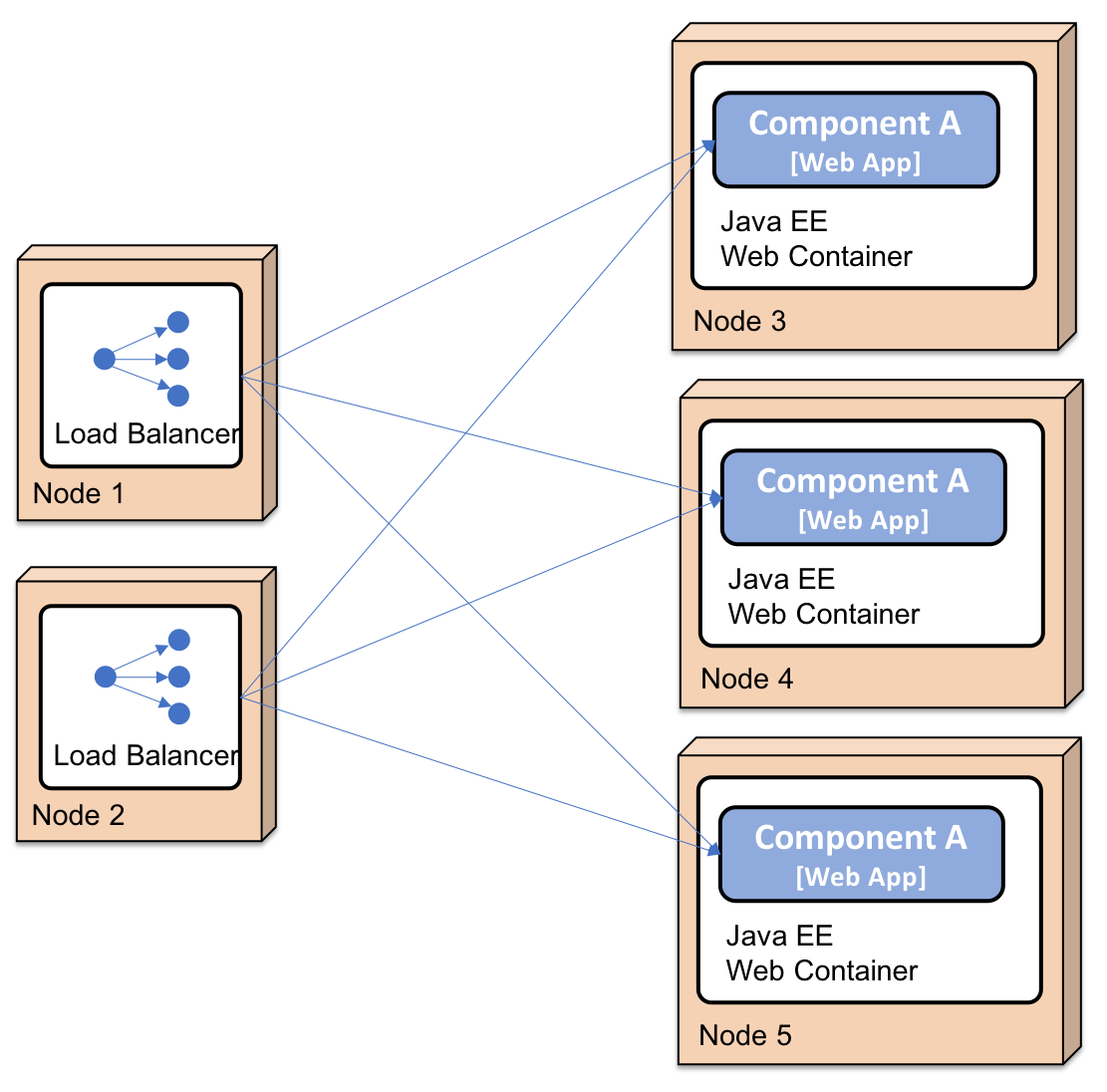
- Thanks to the use of well-defined APIs, each component in the platform can also be scaled out to multiple servers independently of the other components. Scaling can be done either to meet high availability requirements or to handle higher volumes of requests. Technically, this is achieved by manually setting up load balancers in front of a number of servers, each running a Java EE web container. An example where Component A has been scaled out to three instances looks as follows:
We also learned that decomposing the platform introduced a number of new challenges that we were not exposed (at least not to the same degree) when developing more traditional, monolithic applications:
- Adding new instances to a component required manually configuring load balancers and manually setting up new nodes. This work was both time-consuming and error-prone.
- The platform was initially prone to errors in the other systems it was communicating with. If a system stopped responding to requests that were sent from the platform in a timely fashion, the platform quickly ran out of crucial resources, for example, OS threads, specifically when exposed to a large number of concurrent requests. This caused components in the platform to hang or even crash. Since most of the communication in the platform is based on synchronous communication, one component crashing can lead to cascading failures; that is, clients of the crashing components could also crash after a while. This is known as a chain of failures.
- Keeping the configuration consistent and up to date in all the instances of the components quickly became a problem, causing a lot of manual and repetitive work. This led to quality problems from time to time.
- Monitoring the state of the platform in terms of latency issues and hardware usage (for example, usage of CPU, memory, disks, and the network) was more complicated compared to monitoring a single instance of a monolithic application.
- Collecting log files from a number of distributed components and correlating related log events from the components was also difficult but feasible since the number of components was fixed and known in advance.
Over time, we addressed most of the challenges that were mentioned in the preceding list with a mix of in-house-developed tools and well-documented instructions for handling these challenges manually. The scale of the operation was, in general, at a level where manual procedures for releasing new versions of the components and handling runtime issues were acceptable, even though they were not desirable.
Learning about microservice-based architectures in 2014 made me realize that other projects had also been struggling with similar challenges (partly for other reasons than the ones I described earlier, for example, the large cloud service providers meeting web-scale requirements). Many microservice pioneers had published details of lessons they'd learned. It was very interesting to learn from these lessons.
Many of the pioneers initially developed monolithic applications that made them very successful from a business perspective. But over time, these monolithic applications became more and more difficult to maintain and evolve. They also became challenging to scale beyond the capabilities of the largest machines available (also known as vertical scaling). Eventually, the pioneers started to find ways to split monolithic applications into smaller components that could be released and scaled independently of each other. Scaling small components can be done horizontally, that is, deploying a component on a number of smaller servers and placing a load balancer in front of it. If done in the cloud, the scaling capability is potentially endless – it is just a matter of how many virtual servers you bring in (given that your component can scale out on a huge number of instances, but more on that later on).
In 2014, I also learned about a number of new open source projects that delivered tools and frameworks that simplified the development of microservices and could be used to handle the challenges that come with a microservice-based architecture. Some of these are as follows:
- Pivotal released Spring Cloud, which wraps parts of the Netflix OSS in order to provide capabilities such as dynamic service discovery, configuration management, distributed tracing, circuit breaking, and more.
- I also learned about Docker and the container revolution, which is great for minimizing the gap between development and production. Being able to package a component not only as a deployable runtime artifact (for example, a Java, war or, jar file) but as a complete image ready to be launched as a container (for example, an isolated process) on a server running Docker was a great step forward for development and testing.
- A container engine, such as Docker, is not enough to be able to use containers in a production environment. Something is needed that, for example, can ensure that all the containers are up and running and that they can scale out containers on a number of servers, thereby providing high availability and/or increased compute resources. These types of product became known as container orchestrators. A number of products have evolved over the last few years, such as Apache Mesos, Docker in Swarm mode, Amazon ECS, HashiCorp Nomad, and Kubernetes. Kubernetes was initially developed by Google. When Google released v1.0, they also donated Kubernetes to CNCF (https://www.cncf.io/). During 2018, Kubernetes became kind of a de facto standard, available both pre-packaged for on-premise use and available as a service from most major cloud providers.
- I have recently started to learn about the concept of a service mesh and how a service mesh can complement a container orchestrator to further offload microservices from responsibilities to make them manageable and resilient.
Since this book can't cover all aspects of the technologies I just mentioned, I will focus on the parts that have proven to be useful in customer projects I have been involved in since 2014. I will describe how they can be used together to create cooperating microservices that are manageable, scalable, and resilient.
Each chapter in this book will address a specific concern. To demonstrate how things fit together, I will use a small set of cooperating microservices that we will evolve throughout this book:
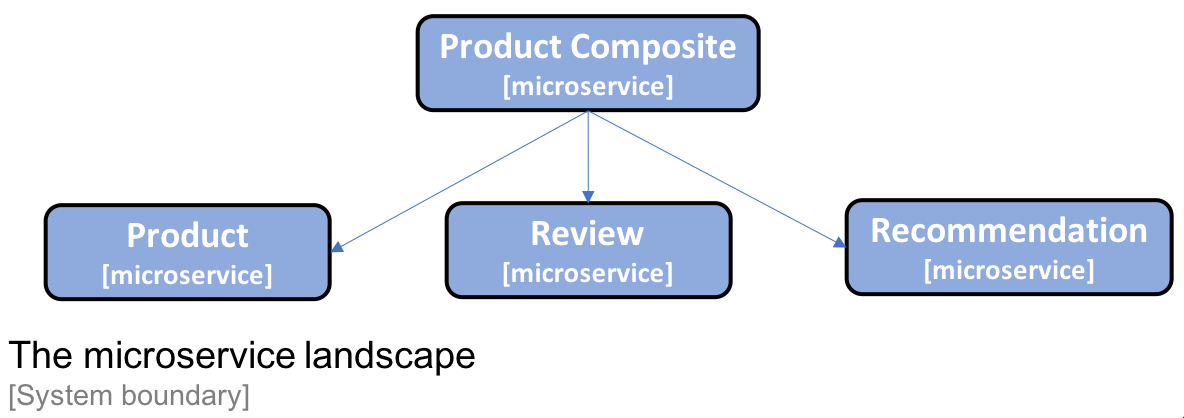
Now that we know the how and what of microservices, let's start to look into how a microservice can be defined.

