

Installing Hadoop is a straightforward job with a default setup, but as we go on customizing the cluster, it gets difficult. Apache Hadoop can be installed in three different setups: namely standalone mode, single node (pseudo-distributed) setup, and fully distributed setup. Local standalone setup is meant for single machine installation. Standalone mode is very useful for debugging purpose. The other two types of setup are shown in the following diagram:
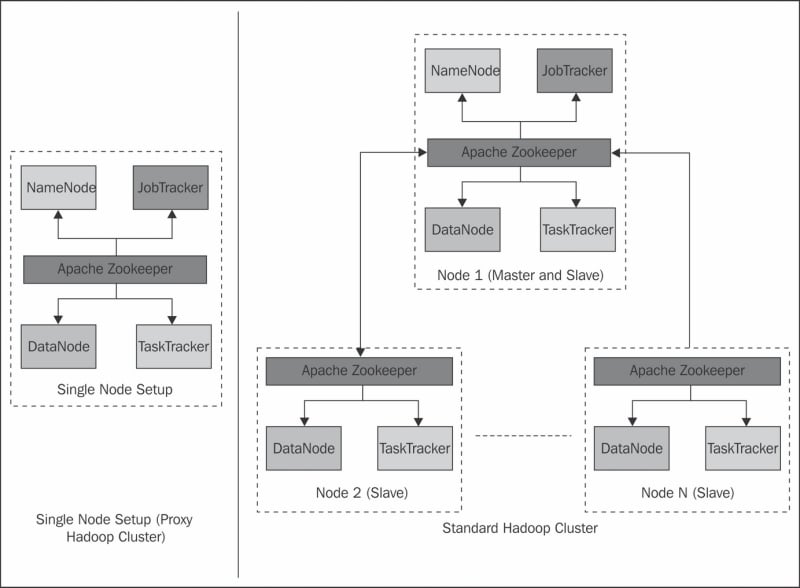
In pseudo-distributed setup of Hadoop, Hadoop is installed on a single machine; this is mainly for development purpose. In this setup, each Hadoop daemon runs as a separate Java process. A real production based installation would be on multiple nodes or full cluster. Let's look at installing Hadoop and running a simple program on it.
Hadoop runs on the following operating systems:
All Linux flavors: It supports development as well as production
Win32: It has limited support (only for development) through Cygwin
Hadoop requires the following software:
Java 1.6 onwards
ssh (Secure shell) to run start/stop/status and other such scripts across cluster
Cygwin, which is applicable only in case of Windows
This software can be installed directly using apt-get for Ubuntu, dpkg for Debian, and rpm for Red Hat/Oracle Linux from respective sites. In case of cluster setup, this software should be installed on all the machines.
Since Hadoop uses SSH to run its scripts on different nodes, it is important to make this SSH login happen without any prompt for password. This can simply be tested by running the ssh command as shown in the following code snippet:
$ssh localhost Welcome to Ubuntu (11.0.4) hduser@node1:~/$
If you get a prompt for password, you should perform the following steps on your machine:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys $ ssh localhost
This step will actually create authorization key with SSH, by passing passphrases check. Once this step is complete, you are good to go.
Hadoop can be first downloaded from the Apache Hadoop website (http://hadoop.apache.org). Make sure that you download and choose the correct release from different releases, which is stable release, latest beta/alpha release, and legacy stable version. You can choose to download the package or download the source, compile it on your OS, and then install it. Using operating system package installer, install the Hadoop package.
To setup a single pseudo node cluster, you can simply run the following script provided by Apache:
$ hadoop-setup-single-node.sh
Say Yes to all the options. This will setup a single node on your machine, you do not need to further change any configuration, and it will run by default. You can test it by running any of the Hadoop command discussed in HDFS section of this chapter.
For a cluster setup, the SSH passphrase should be set on all the nodes, to bypass prompt for password while starting and stopping TaskTracker/DataNodes on all the slaves from masters. You need to install Hadoop on all the machines which are going to participate in the Hadoop cluster. You also need to understand the Hadoop configuration file structure, and make modifications to it.
Major Hadoop configuration is specified in the following configuration files, kept in the $HADOOP_HOME/conf folder of the installation:
The files marked in bold letters are the files that you will definitely modify to set up your basic Hadoop cluster.
You can start your cluster with the following command; once started, you will see the output shown as follows:
hduser@ubuntu:~$ /usr/local/hadoop/bin/start-all.sh Starting namenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-namenode-ubuntu.out localhost: starting datanode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-datanode-ubuntu.out localhost: starting secondarynamenode, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-secondarynamenode-ubuntu.out starting jobtracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-jobtracker-ubuntu.out localhost: starting tasktracker, logging to /usr/local/hadoop/bin/../logs/hadoop-hduser-tasktracker-ubuntu.out hduser@ubuntu:/usr/local/hadoop$
Now we can test the functioning of this cluster by running sample examples shipped with Hadoop installation. First, copy some files from your local directory on HDFS and you can run following command:
hduser@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -copyFromLocal /home/myuser/data /user/myuser/data
Run hadoop dfs –ls on your Hadoop instance to check whether the files are loaded in HDFS. Now, you can run the simple word count program to count the number of words in all these files.
bin/hadoop jar hadoop*examples*.jar wordcount /user/myuser/data /user/myuser/data-output
You will typically find hadoop-example jar in /usr/share/hadoop, or in $HADOOP_HOME. Once it runs, you can run hadoop dfs cat on data-output to list the output.