

These scientific computational solutions generally produce approximate solutions. By approximate solution, we mean that instead of the exact desired solution, the obtained solution will be nearly similar to it. By nearly similar, we mean that it will be a sufficiently close solution to consider the practical or simulation successful, as they fulfill the purpose. This approximate, or similar, solution is caused by a number of sources. These sources can be divided into two categories: sources that arise before the computations begin, and those that occur during the computations.
The approximations that occur before the beginning of computations may be caused by one or more of the following:
Assumption or ignorance during modeling: There might be an assumption during the modeling process, and similarly ignorance or omission of the impact of a concept or phenomenon during modeling, that may result in the approximation or tolerable inaccuracy.
Data derived from observations or experiments: The inaccuracy may be in the data obtained from some devices that have low precision. During the computations, there are some constants, such as pi, whose values have to be approximated, and this is also an important cause of deviation from the correct result.
Prerequisite computations: The data may have been obtained from the results of previous experiments, or simulations may have had minor, acceptable inaccuracies that finally led to further approximations. Such prior processing may be a prerequisite of the subsequent experiments.
Approximation during computations occurs because of one or more of the following sources:
Simplification of the problem: As we have already suggested in this chapter, to solve large and complex problems, we should use a combination of "divide and conquer" and replacing a small, complex problem with a simpler one. This may result in approximations. Considering that we replaced an infinite series with a finite series will possibly cause approximations.
Truncation and rounding: A number of situations ask for rounding and truncation of the intermediate results. Similarly, the internal representation of floating-point numbers in computers and their arithmetic also leads to minor inaccuracies.
The approximate value of the final result of a computation problem may be the outcome of any combination of the various sources discussed previously. The accuracy of the final output may be reduced or increased depending on the problem being solved and the approach used to solve it.
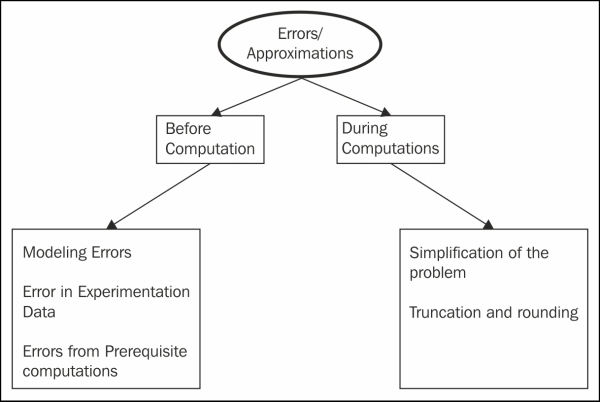
Taxonomy of errors and approximation in computations
Error analysis is a process used to observe the impact of such approximations on the accuracy of an algorithm or computational process. In the subsequent text, we are going to discuss the basic concepts associated with error analysis.
An observation may be made from the previous discussion on approximations that the errors can be considered as errors in the input data and they arose during the computations on this input data.
On a similar path, computation errors may again be divided into two categories: truncation errors and rounding errors. A truncation error is the result of reducing a complex problem to a simpler problem, for example, immature termination of iterations before the desired accuracy is achieved. A rounding error is the result of the precision used to represent numbers in the number system used for the computerized computation, and also the result of performing arithmetic on these numbers.
Ultimately, the amount of error that is significant or ignorable depends on the scale of the values. For example, an error of 10 in a final value of 15 is highly significant, while an error of 10 in a final value of 785 is not that significant. Moreover, the same error of 10 in obtaining the final value of 17,685 is ignorable. Generally, the impact of an error value is relative to the value of the result. If we know the magnitude of the final value to be obtained, then after looking at the value of the error, we can decide whether to ignore it or consider it as significant. If the error is significant, then we should start taking the corrective measures.
Let's discuss some important properties of problems and algorithms. Sensitivity or conditioning is a property of a problem. The problem under consideration can be called sensitive or insensitive, or it may be called well-conditioned or ill-conditioned. A problem is said to be insensitive or well-conditioned if, for a given relative change in input, the data will have a proportional relative final impact on the result. On the other hand, if the relative impact of the final result is considerably larger than the relative change in input data, then the problem will be considered a sensitive or ill-conditioned problem.
Assume that we have obtained the approximation y* by f mapping the data x, for example, y*=f(x). Now, if the actual result is y, then the small quantity y' =y*-y is called a forward error, and its estimation is called forward error analysis. Generally, it is very difficult to obtain this estimate. An alternative approach to this is to consider y* as the exact solution to the same problem with modified data, that is, y*=f(x'). Now, the quantity x*=x'-x is called a backward error in y*. Backward error analysis is the process of estimation of x*.
The answer to this question depends on the domain and application where you are going to apply the scientific computations. For example, if it is the calculation of the time to launch a missile, an error of 0.1 seconds will result in severe damage. On the other hand, if it is the calculation of the arrival time of a train, an error of 40 seconds will not lead to a big problem. Similarly, a small change in a medicine dosage can have a disastrous effect on the patient. Generally, if a computation error in an application is not related to loss of human lives or doesn't involve big costs, then it can be ignored. Otherwise, we need to take proper efforts to resolve the issue.