

In the previous sections, we saw various ways of evaluating our models and also defining the loss functions that we want to minimize. This suggests that a learning task can be viewed as an optimizations problem. In an optimization problem, we are provided with a hypothesis space, which in this case, is the set of all possible models along with an objective function, on the basis of which we will select the best-representing model from the hypothesis space. In this section, we will discuss the various choices of objective functions and how they affect our learning task.
Let's consider the task of selecting a model, M, which optimizes the expectation of some loss function,  . As we don't know the value of
. As we don't know the value of  , we generally use the dataset, D, which we have to get an empirical estimate of the expectation. Using D, we can define an empirical distribution,
, we generally use the dataset, D, which we have to get an empirical estimate of the expectation. Using D, we can define an empirical distribution, 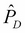 , as follows:
, as follows:
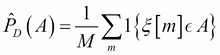
Putting this in simple words, for some event, A, we assign its probability...