

As in the case of Bayesian networks, we can also estimate the parameters in the case of Markov networks using maximum likelihood. Let's see in detail how maximum likelihood works in the case of Markov networks.
Let's take a very simple example of the network, X — Y — Z. We have two potentials,  and
and 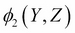 . We can now define the joint distribution over this network as follows:
. We can now define the joint distribution over this network as follows:
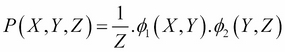
Here, Z is the partition function and is defined as follows:
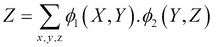
Therefore, the log-likelihood equation for a single instance <x, y, z> would be as follows:
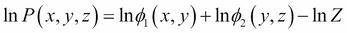
Suppose we have a dataset D containing M samples, we can write the likelihood in the following way:

Thus, the log-likelihood equation translates to the following formula:

As we have seen in the case of Bayesian networks, once we have sufficient statistics that summarize the data (the joint count of the variables), we can learn the parameter,  . However, with Markov models, the problem is the third term appearing in...
. However, with Markov models, the problem is the third term appearing in...