

Until now, we have been trying to learn the model to predict all the variables. This kind of learning is known as generative learning, as we are trying to generate all the variables, the ones we are trying to predict as well as the ones that we want to use as features. However, as we discussed earlier, in many cases, we already know the conditional distribution that we want to predict. So, in such cases, we try to predict a model so that 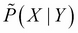 is as close as possible to
is as close as possible to  . This is known as discriminative learning.
. This is known as discriminative learning.
As discussed in the previous sections, we must formalize our learning task. The inputs for our learning task are as follows:
-
Constraints for our model,
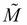 , which will be used to define our hypothesis space
, which will be used to define our hypothesis space
- A set of independent and identically distributed samples,
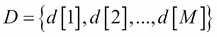 , from the original distribution
, from the original distribution
The output of our learning will either be the network structure, the parameters, or both. Let's discuss all these in a bit more detail.