

Spark is a Java Virtual Machine (JVM) based distributed data processing engine that scales, and it is fast compared to many other data processing frameworks. Spark was originated at the University of California Berkeley and later became one of the top projects in Apache. The research paper, Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center, talks about the philosophy behind the design of Spark. The research paper states:
"To test the hypothesis that simple specialized frameworks provide value, we identified one class of jobs that were found to perform poorly on Hadoop by machine learning researchers at our lab: iterative jobs, where a dataset is reused across a number of iterations. We built a specialized framework called Spark optimized for these workloads."
The biggest claim from Spark regarding speed is that it is able to "Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk". Spark could make this claim because it does the processing in the main memory of the worker nodes and prevents the unnecessary I/O operations with the disks. The other advantage Spark offers is the ability to chain the tasks even at an application programming level without writing onto the disks at all or minimizing the number of writes to the disks.
How did Spark become so efficient in data processing as compared to MapReduce? It comes with a very advanced Directed Acyclic Graph (DAG) data processing engine. What it means is that for every Spark job, a DAG of tasks is created to be executed by the engine. The DAG in mathematical parlance consists of a set of vertices and directed edges connecting them. The tasks are executed as per the DAG layout. In the MapReduce case, the DAG consists of only two vertices, with one vertex for the map task and the other one for the reduce task. The edge is directed from the map vertex to the reduce vertex. The in-memory data processing combined with its DAG-based data processing engine makes Spark very efficient. In Spark's case, the DAG of tasks can be as complicated as it can. Thankfully, Spark comes with utilities that can give excellent visualization of the DAG of any Spark job that is running. In a word count example, Spark's Scala code will look something like the following code snippet . The details of this programming aspects will be covered in the coming chapters:
val textFile = sc.textFile("README.md")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word =>
(word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()
The web application that comes with Spark is capable of monitoring the workers and applications. The DAG of the preceding Spark job generated on the fly will look like Figure 2, as shown here:
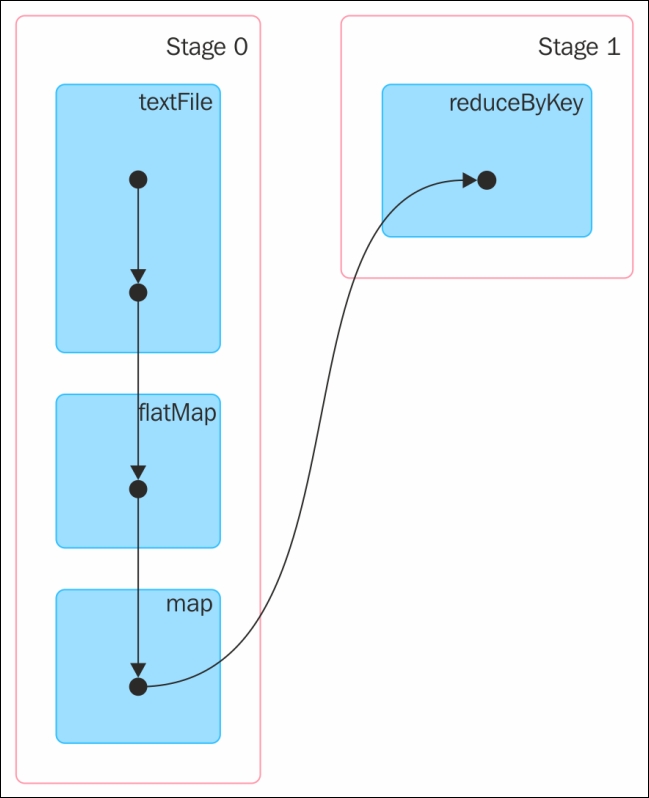
Figure 2
The Spark programming paradigm is very powerful and exposes a uniform programming model supporting the application development in multiple programming languages. Spark supports programming in Scala, Java, Python, and R even though there is no functional parity across all the programming languages supported. Apart from writing Spark applications in these programming languages, Spark has an interactive shell with Read, Evaluate, Print, and Loop (REPL) capabilities for the programming languages Scala, Python, and R. At this moment, there is no REPL support for Java in Spark. The Spark REPL is a very versatile tool that can be used to try and test Spark application code in an interactive fashion. The Spark REPL enables easy prototyping, debugging, and much more.
In addition to the core data processing engine, Spark comes with a powerful stack of domain specific libraries that use the core Spark libraries and provide various functionalities useful for various big data processing needs. The following table lists the supported libraries:
|
Library |
Use |
Supported Languages |
|
Spark SQL |
Enables the use of SQL statements or DataFrame API inside Spark applications |
Scala, Java, Python, and R |
|
Spark Streaming |
Enables processing of live data streams |
Scala, Java, and Python |
|
Spark MLlib |
Enables development of machine learning applications |
Scala, Java, Python, and R |
|
Spark GraphX |
Enables graph processing and supports a growing library of graph algorithms |
Scala |
Spark can be deployed on a variety of platforms. Spark runs on the operating systems (OS) Windows and UNIX (such as Linux and Mac OS). Spark can be deployed in a standalone mode on a single node having a supported OS. Spark can also be deployed in cluster node on Hadoop YARN as well as Apache Mesos. Spark can be deployed in the Amazon EC2 cloud as well. Spark can access data from a wide variety of data stores, and some of the most popular ones include HDFS, Apache Cassandra, Hbase, Hive, and so on. Apart from the previously listed data stores, if there is a driver or connector program available, Spark can access data from pretty much any data source.
Tip
All the examples used in this book are developed, tested, and run on a Mac OS X Version 10.9.5 computer. The same instructions are applicable for all the other platforms except Windows. In Windows, corresponding to all the UNIX commands, there is a file with a .cmd extension and it has to be used. For example, for spark-shell in UNIX, there is a spark-shell.cmd in Windows. The program behavior and results should be the same across all the supported OS.
In any distributed application, it is common to have a driver program that controls the execution and there will be one or more worker nodes. The driver program allocates the tasks to the appropriate workers. This is the same even if Spark is running in standalone mode. In the case of a Spark application, its SparkContext object is the driver program and it communicates with the appropriate cluster manager to run the tasks. The Spark master, which is part of the Spark core library, the Mesos master, and the Hadoop YARN Resource Manager, are some of the cluster managers that Spark supports. In the case of a Hadoop YARN deployment of Spark, the Spark driver program runs inside the Hadoop YARN application master process or the Spark driver program runs as a client to the Hadoop YARN. Figure 3 describes the standalone deployment of Spark:
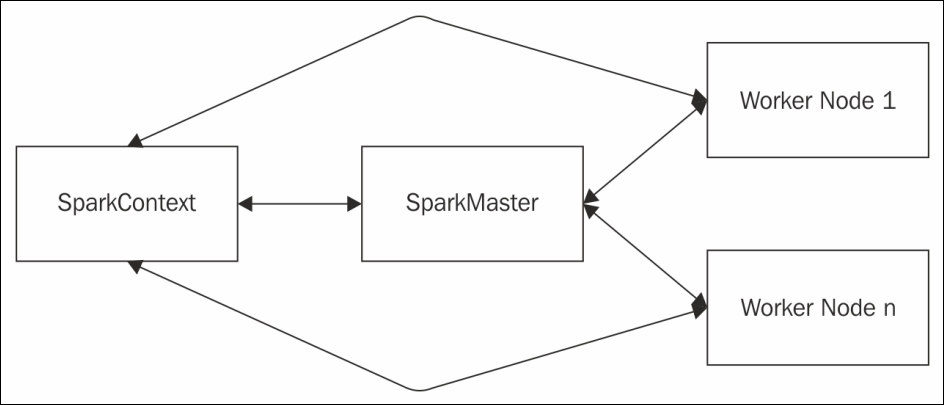
Figure 3
In the Mesos deployment mode of Spark, the cluster manager will be the Mesos Master. Figure 4 describes the Mesos deployment of Spark:
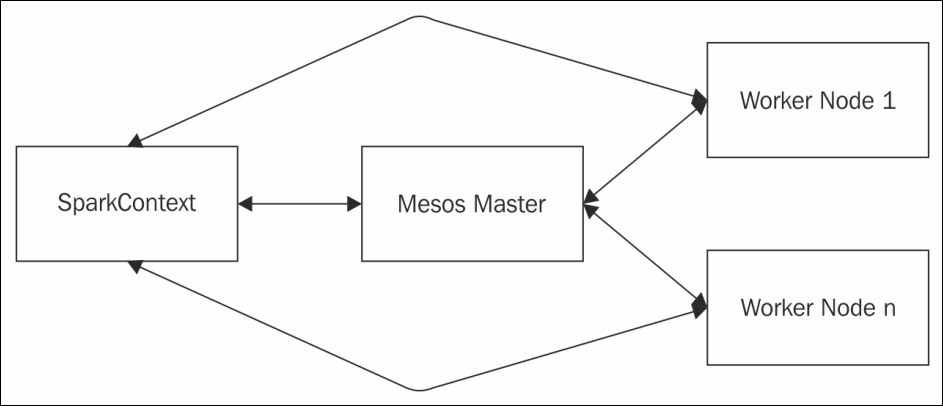
Figure 4
In the Hadoop YARN deployment mode of Spark, the cluster manager will be the Hadoop Resource Manager and its address will be picked up from the Hadoop configuration. In other words, when submitting the Spark jobs, there is no need to give an explicit master URL and it will pick up the details of the cluster manager from the Hadoop configuration. Figure 5 describes the Hadoop YARN deployment of Spark:
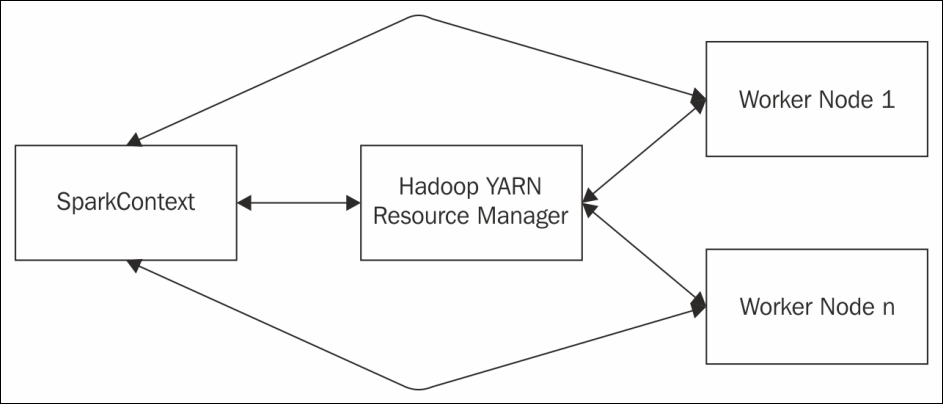
Figure 5
Spark runs in the cloud too. In the case of the deployment of Spark on Amazon EC2, apart from accessing the data from the regular supported data sources, Spark can also access data from Amazon S3, which is the online data storage service from Amazon.