

To understand the journey of deep learning in this book, one must know all the terminologies and basic concepts of machine learning. However, if you already have enough insight into machine learning and related terms, you should feel free to ignore this section and jump to the next topic of this chapter. Readers who are enthusiastic about data science, and want to learn machine learning thoroughly, can follow Machine Learning by Tom M. Mitchell (1997) [5] and Machine Learning: a Probabilistic Perspective (2012) [6].
Note
Neural networks do not perform miracles. But, used sensibly, they can produce some amazing results.
Neural networks can be recurrent as well as feed-forward. Feed-forward networks do not have any loop associated in their graph, and are arranged in a set of layers. A network with many layers is said to be a deep network. In simple words, any neural network with two or more layers (hidden) is defined as a deep feed-forward network or feed-forward neural network. Figure 1.4 shows a generic representation of a deep feed-forward neural network.
Deep feed-forward networks work on the principle that with an increase in depth, the network can also execute more sequential instructions. Instructions in sequence can offer great power, as these instructions can point to the earlier instruction.
The aim of a feed-forward network is to generalize some function f. For example, classifier y=f(x) maps from input x to category y. A deep feed-forward network modified the mapping, y=f(x; α), and learns the value of the parameter α, which gives the most appropriate value of the function. The following Figure 1.4 shows a simple representation of the deep-forward network, to provide the architectural difference with the traditional neural network.
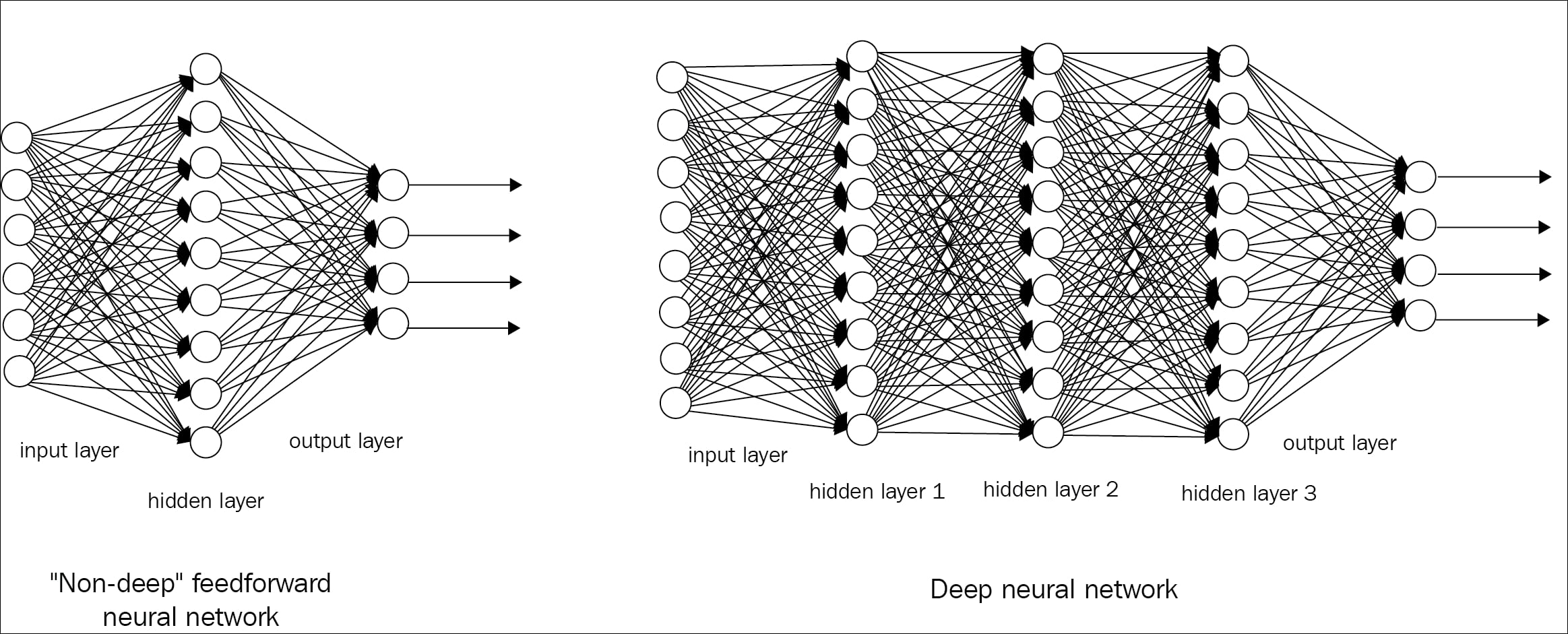
Figure 1.4: Figure shows the representation of a shallow and deep feed-forward network
Datasets are considered to be the building blocks of a learning process. A dataset can be defined as a collection of interrelated sets of data, which is comprised of separate entities, but which can be used as a single entity depending on the use-case. The individual data elements of a dataset are called data points.
The following Figure 1.5 gives the visual representation of the various data points collected from a social network analysis:

Figure 1.5: Image shows the scattered data points of social network analysis. Image sourced from Wikipedia
Unlabeled data: This part of data consists of the human-generated objects, which can be easily obtained from the surroundings. Some of the examples are X-rays, log file data, news articles, speech, videos, tweets, and so on.
Labelled data: Labelled data are normalized data from a set of unlabeled data. These types of data are usually well formatted, classified, tagged, and easily understandable by human beings for further processing.
From the top-level understanding, machine learning techniques can be classified as supervised and unsupervised learning, based on how their learning process is carried out.
In unsupervised learning algorithms, there is no desired output from the given input datasets. The system learns meaningful properties and features from its experience during the analysis of the dataset. In deep learning, the system generally tries to learn from the whole probability distribution of the data points. There are various types of unsupervised learning algorithms, which perform clustering. To explain in simple words, clustering means separating the data points among clusters of similar types of data. However, with this type of learning, there is no feedback based on the final output, that is, there won't be any teacher to correct you! Figure 1.6 shows a basic overview of unsupervised clustering:
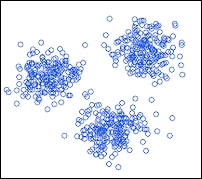
Figure 1.6: Figures shows a simple representation of unsupervised clustering
A real life example of an unsupervised clustering algorithm is Google News. When we open a topic under Google News, it shows us a number of hyper-links redirecting to several pages. Each of these topics can be considered as a cluster of hyper-links that point to independent links.
In supervised learning, unlike unsupervised learning, there is an expected output associated with every step of the experience. The system is given a dataset, and it already knows how the desired output will look, along with the correct relationship between the input and output of every associated layer. This type of learning is often used for classification problems.
The following visual representation is given in Figure 1.7:
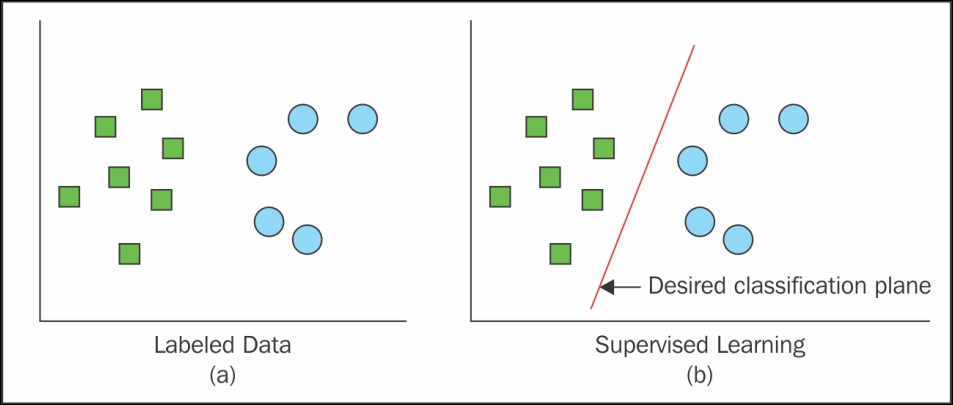
Figure 1.7: Figure shows the classification of data based on supervised learning
Real-life examples of supervised learning include face detection, face recognition, and so on.
Although supervised and unsupervised learning look like different identities, they are often connected to each other by various means. Hence, the fine line between these two learnings is often hazy to the student fraternity.
The preceding statement can be formulated with the following mathematical expression:
The general product rule of probability states that for an n number of datasets n ε ℝt,the joint distribution can be fragmented as follows:
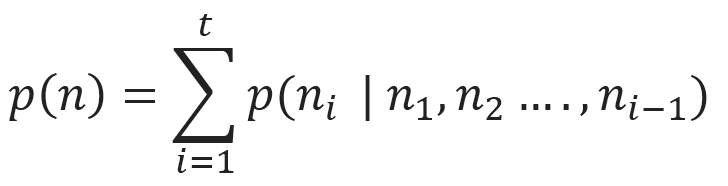
The distribution signifies that the appeared unsupervised problem can be resolved by t number of supervised problems. Apart from this, the conditional probability of p (k | n), which is a supervised problem, can be solved using unsupervised learning algorithms to experience the joint distribution of p (n, k).
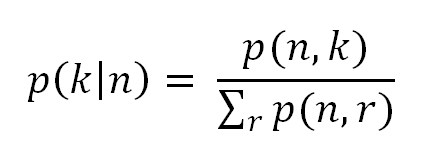
Although these two types are not completely separate identities, they often help to classify the machine learning and deep learning algorithms based on the operations performed. In generic terms, cluster formation, identifying the density of a population based on similarity, and so on are termed as unsupervised learning, whereas structured formatted output, regression, classification, and so on are recognized as supervised learning.
As the name suggests, in this type of learning both labelled and unlabeled data are used during the training. It's a class of supervised learning which uses a vast amount of unlabeled data during training.
For example, semi-supervised learning is used in a Deep belief network (explained later), a type of deep network where some layers learn the structure of the data (unsupervised), whereas one layer learns how to classify the data (supervised learning).
In semi-supervised learning, unlabeled data from p (n) and labelled data from p (n, k) are used to predict the probability of k, given the probability of n, or p (k | n).
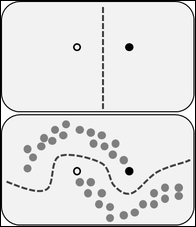
Figure 1.8: Figure shows the impact of a large amount of unlabelled data during the semi-supervised learning technique. Figure obtained from Wikipedia
In the preceding Figure 1.8, at the top it shows the decision boundary that the model uses after distinguishing the white and black circles. The figure at the bottom displays another decision boundary, which the model embraces. In that dataset, in addition to two different categories of circles, a collection of unlabeled data (grey circle) is also annexed. This type of training can be viewed as creating the cluster, and then marking those with the labelled data, which moves the decision boundary away from the high-density data region.
The preceding Figure 1.8 depicts the illustration of semi-supervised learning. You can refer to Chapelle et al.'s book [7] to know more about semi-supervised learning methods.
So, as you have already got a foundation in what Artificial Intelligence, machine learning, and representation learning are, we can now move our entire focus to elaborate on deep learning with further description.
From the previously mentioned definitions of deep learning, two major characteristics of deep learning can be pointed out, as follows:
A way of experiencing unsupervised and supervised learning of the feature representation through successive knowledge from subsequent abstract layers
A model comprising of multiple abstract stages of non-linear information processing