

A Histogram is a special kind of bar chart. A histogram depicts some quantitative value on the x axis and frequency of that value on the y axis. The main feature of a histogram is that in a histogram, the x axes are grouped into bins and we treat each bin as a category. Thus, for a particular value, we take both the x axis bin and the frequency on the y axis into account.
Let's try to understand a histogram using the same cars.json dataset, which we used earlier. For the quantitative variable on the x axis, we will be using the number of cars grouped by each country and depict that on the x axis. The Y axis will denote the frequency of the number of counts, that is, the percentage or probability of countries with that amount of cars in the dataset. The diagram is as shown next:
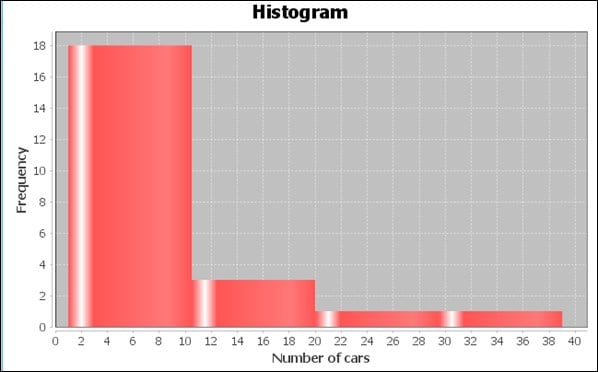
As you can see in the preceding chart, the maximum number of countries have a number of cars between 0 and 10 count. Next is the countries with cars between 10 and 20 count, and the remaining few between...