

Relational databases are suitable for real-time crud operations such as order capture in e-commerce stores but they are not suitable for certain use cases for which big data is used. The data that is stored in relational databases is structured only but in big data stack (read Hadoop) both structured and unstructured data can be stored. Apart from this, the quantity of data that can be stored and parallelly processed in big data is massive. Facebook stores close to a tera byte of data in its big data stack on a daily basis. Thus, mostly in places where we need real-time crud operations on data, we can still continue to use relational databases, but in other places where we need to store and analyze almost any kind of data (whether log files, video files, web access logs, images, and so on.), we should use Hadoop (that is, big data).
Since analytics run on Hadoop, it runs on top of massive amounts of data; it is thereby a no brainer that deductions made from this are way more different than can be made from small amounts of data. As we all know, analytic results from large data amounts beat any fancy algorithm results. Also you can run all kinds of analytics on this data whether it be stream processing, predictive analytics, or real-time analytics.
The data on top of Hadoop is parallelly processed on multiple nodes. Hence the processing is very fast and the results are parallelly computed and combined.
Let's take a look at the following diagram to see what kinds of data can be stored in big data:
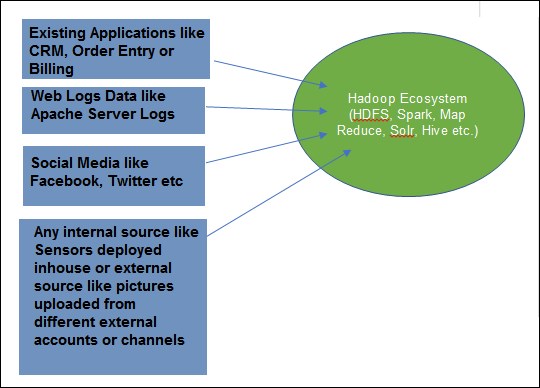
As you can see, the data from varied sources and of varied kinds can be dumped into Hadoop and later analyzed. As seen in the preceding image there could be many existing applications that could serve as sources of data whether providing CRM data, log data, or any other kind of data (for example, orders generated online or audit history of purchase orders from existing web order entry applications). Also as seen in the image, data can also be collected from social media or web logs of HTTP servers like Apache or any internal source like sensors deployed in a house or in the office, or external source like customers' mobile devices, messaging applications such as messengers and so on.
Java is a natural fit for big data. All the big data tools support Java. In fact, some of the core modules are written in Java only, for example, Hadoop is written in Java. Learning some of the big data tools is no different than learning a new API for Java developers. So, putting big data skills in their skillset is a healthy addition for all the Java developers.
Mostly, Python and R language are hot in the field of data science mainly because of the ease of use and the availability of great libraries such as scikit-learn. But, Java, on the other hand has picked up greatly due to big data. On the big data side, there is availability of good software on the Java stack that can be readily used for applying regular analytics or predictive analytics using machine learning libraries.
Learning a combination of big data and analytics on big data would get you closer to apps that make a real impact on business and hence they command a good pay too.
Hadoop is a free, Java-based programming framework that supports the processing of these large datasets in a distributed computing environment. It is part of the Apache Software Foundation and was donated by Yahoo! It can be easily installed on a cluster of standard machines. Different computing jobs can then be parallelly run on these machines for faster performance. Hadoop has become very successful in companies to store all of their massive data in one system and perform analysis on this data. Hadoop runs in a master/slave architecture. The master controls the running of the entire distributed computing stack.
Some of the main features of Hadoop are:
|
Feature name |
Feature description |
|---|---|
|
Failover support |
If one or more slave machines go down, the task is transferred to another workable machine by the master |
|
Horizontal scalability |
Just by adding a new machine, it comes within the network of the Hadoop framework and becomes part of the Hadoop ecosystem |
|
Lower cost |
Hadoop runs on cheap commodity hardware and is much cheaper than the costly large data solutions of other companies. For example some bigger firms have large data warehouse implementations such as Oracle Exadata or Teradata. These also let you store and analyze huge amounts of data but their hardware and software both are expensive and require more maintenance. Hadoop on the other hand installs on commodity hardware and its software is open sourced. |
|
Data locality |
This is one of the most important features of Hadoop and is the reason why Hadoop is so fast. Any processing of large data is done on the same machine on which the data resides. This way, there is no time and bandwidth lost in the transferring of data. |
There is an entire ecosystem of software that is built around Hadoop. Take a look at the following diagram to visualize the Hadoop ecosystem:
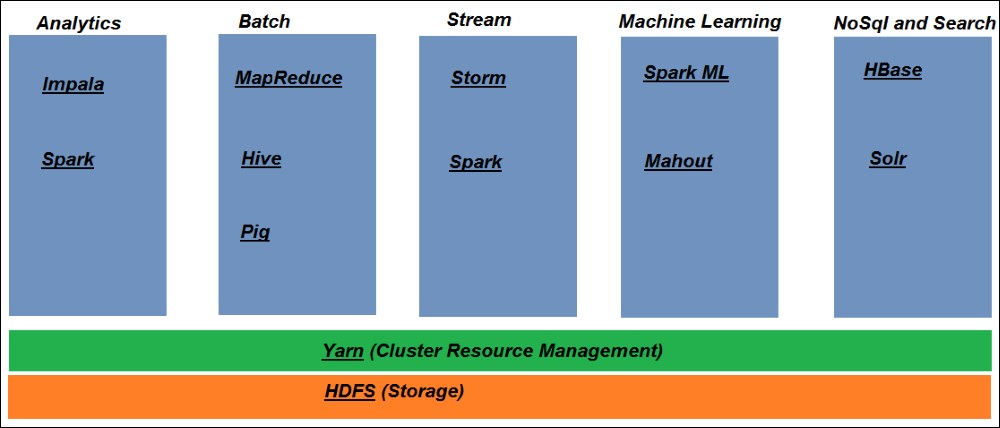
As you can see in the preceding diagram, for different criteria we have a different set of products. The main categories of the products that big data has are shown as follows:
Analytical products: The whole purpose of this big data usage is an ability to analyze and make use of this extensive data. For example, if you have click stream data lying in the HDFS storage of big data and you want to find out the users with maximum hits or users who made the most number of purchases, or based on the transaction history of users you want to figure out the best recommendations for your users, there are some popular products that help us to analyze this data to figure out these details. Some of these popular products are Apache Spark and Impala. These products are sophisticated enough to extract data from the distributed machines of big data storage and to transform and manipulate it to make it useful.
Batch products: in the initial stages when it came into picture, the word "big data" was synonymous with batch processing. So you had jobs that ran on this massive data for hours and hours cleaning and extracting the data to probably build useful reports for the users. As such, the initial set of products that shipped with Hadoop itself included "MapReduce", which is a parallel computing batch framework. Over time, more sophisticated products appeared such as Apache Spark, which also a cluster computing framework but is comparatively faster than MapReduce, but still in actuality they are batch only.
Streamlining: This category helps to fill the void of pulling and manipulating real time data in the Hadoop space. So we have a set of products that can connect to sources of streaming data and act on it in real time. So using these kinds of products you can make things like trending videos on YouTube or trending hashtags on Twitter at this point in time. Some popular products in this space are Apache Spark (using the Spark Streaming module) and Apache Storm. We will be covering the Apache Spark streaming module in our chapter on real time analytics.
Machine learning libraries: In the last few years there has been tremendous work in the predictive analytics space. Predictive analytics involves usage of advanced machine learning libraries and it's no wonder that some of these libraries are now included with the clustering computing frameworks as well. So a popular machine learning library such as Spark ML ships along with Apache Spark and older libraries such as Apache Mahout are also supported on big data. This is a growing space with new libraries frequently entering the market every few days.
NoSQL: There are times when we need frequent reads and updates of data even though big data is involved. Under these situations there are a lot of non-SQL products that can be readily used while analyzing your data and some of the popular ones that can be used are Cassandra and HBase both of which are open source.
Search: Quite often big data is in the form of plain text. There are many use cases where you would like to index certain words in the text to make them easily searchable. For example, if you are putting all the newspapers of a particular branch published for the last few years in HDFS in pdf format, you might want a proper index to be made over these documents so that they are readily searchable. There are products in the market that were previously used extensively for building search engines and they are now integratable with big data as well. One of the popular and open source options is SOLR and it can be easily established on top of big data to make the content easily searchable.
The categories of products we have just depicted previously is not extensive. We have not covered messaging solutions and there are many other products too apart from this. For checking on extensive lists refer to a book that specifically covers Hadoop in detail: for example, the Hadoop Definitive Guide.
We have covered the main categories of products, but let's now cover some of the important products themselves that are built on top of the big data stack:
Suppose you put plenty of data on a disk and read it. Reading this entire data takes, for example, 24 hours. Now, suppose you distribute this data on 24 different machines of the same type and run the read program at the same time on all the machines. You might be able to parallelly read the entire data in an hour (an assumption just for the purpose of this example). This is what parallel computing is all about though. It helps in processing large volumes of data parallelly on multiple machines called nodes and then combining the results to build a cumulated output. Disk input/output is so slow that we cannot rely on a single program running on one machine to do all this for us.
There is an added advantage of data storage across multiple machines, which is failover and replication support of data.
The bare bones of Hadoop are the base modules that are shipped with its default download option. Hadoop consists of three main modules:
Hadoop core: This is the main layer that has the code for the failover, data replication, data storage, and so on.
HDFS: The Hadoop Distributed File System (HDFS) is the primary storage system used by Hadoop applications. HDFS is a distributed filesystem that provides high-performance access to data across Hadoop clusters.
MapReduce: This is the data analysis framework that runs parallely on top of data stored in HDFS.
As you saw in the options above if you install the base Hadoop package you will get the core Hadoop library, the HDFS file system, and the MapReduce framework by default, but this is not extensive and the current use cases demand much more then the bare minimum products provided by the Hadoop default installation. It is due to this reason that a whole set of products have originated on top of this big data stack be, it the streaming products such as Storm or messaging products such as Kafka or search products such as SOLR.
HDFS is Hadoop's implementation of a distributed filesystem. The way it is built, it can handle large amount of data. It can scale to the extent where the other types of distributed filesystems, for example, NFS cannot scale to. It runs on plain commodity servers and any number of servers can be used.
HDFS is a write once, read several times type of filesystem. Also, you can append to a file, but you cannot update a file. So if you need to make an update, you need to create a new file with a different version. If you need frequent updates and the amount of data is small, then you should use other software such as RDBMS or HBASE.
These are some of the features of HDFS:
Open source: HDFS is a completely open source distributed filesystem and is a very active open source project.
Immense scalability for the amount of data: You can store petabytes of data in it without any problem.
Failover support: Any file that is put in HDFS is broken into chunks (called blocks) and these blocks are distributed across different machines of the cluster. Apart from the distribution of this file data, the data is also replicated across the different machines depending upon the replication level. Thereby, in case any machine goes down; the data is not lost and is served from the other machine.
Fault tolerance: This refers to the capability of a system to work in unfavorable conditions. HDFS handles faults by keeping replicated copies of data. So due to a fault, if one set of data in a machine gets corrupted then the data can always be pulled from some other replicated copy. The replica of the data is created on different machines, so even if the entire machine goes down, still is no problem as replicated data can always be pulled from some other machine that has the copy of it.
Data locality: The way HDFS is designed, it allows the main data processing programs to run closer to the data where it resides and hence they are faster as less network transfer is involved.
There are two main daemons that make up HDFS. They are depicted in the following diagram:

As you can see in the preceding diagram, the main components are:
NameNode: This is the main program (master) of HDFS. A file in HDFS is broken in to chunks or blocks and is distributed and replicated across the different machines in the Hadoop cluster. It is the responsibility of the NameNode to figure out which blocks go where and where the replicated blocks land up. It is also responsible for clubbing the data of the file when the full file is asked for by the client. It maintains the full metadata for the file.
DataNodes: These are the slave processes running on the other machines (other than the NameNode machine). They store the data and provide the data when the NameNode asks for it.
The most important advantage of this master/slave architecture of HDFS is failover support. Thereby, if any DataNode or slave machine is down, the NameNode figures this out using a heartbeat signal and it would then refer to another DataNode that has the replicated copy of that data. Before Hadoop 2, the NameNode was the single point of failure but after Hadoop 2, NameNodes have a better failover support. So you can run two NameNodes alongside one another so that if one NameNode fails, the other NameNode can quickly take over the control.
Most of the commands on HDFS are for storing, retrieving, or discarding data on it. If you are used to working on Linux, then using HDFS shell commands is simple, as almost all the commands are a replica of the Linux commands with similar functions. Though the HDFS commands can be executed by the browser as well as using Java programs, for the purpose of this book, we will be only discussing the shell commands of HDFS, as shown in the following table:
|
Command |
What it does |
|---|---|
|
|
This helps you to make a directory in HDFS:
You always start the command with |
|
|
This helps you to copy a file from a local filesystem to
This copies a file |
|
|
This helps you to list out all files inside a directory:
|
|
|
This helps you to remove a file:
(deletes |
|
|
This helps you to check the file size:
|
|
|
This helps you to change the permissions on all:
This only gives the owner of the file complete permissions; rest of the users won't have any permissions on the file. |
|
|
This helps you to read the contents of a file:
|
|
|
This helps you to read the top content (few lines from top) of a file:
Similarly, we have the |
|
|
This helps you to move a file across different directories:
|
Apache Spark is the younger brother to the MapReduce framework. It's a cluster computing framework that is getting much more attraction now in comparison to MapReduce. It can run on a cluster of thousands of machines and distribute computations on the massive datasets across these machines and combine the results.
There are few main reasons why Spark has become more popular than MapReduce:
It is way faster than MapReduce because of its approach of handling a lot of stuff in memory. So on the individual nodes of machines, it is able to do a lot of work in memory, but MapReduce on the other hand has to touch the hard disk many times to get a computation done and the hard disk read/write is slow, so MapReduce is much slower.
Spark has an extremely simple API and hence it can be learned very fast. The best documentation is the Apache page itself, which can be accessed at spark.apache.org. Running algorithms such as machine learning algorithms on MapReduce can be complex but the same can be very simple to implement in Apache Spark.
It has a plethora of sub-projects that can be used for various other operations.
The main concept to understand Spark is the concept of RDDs or Resilient Distributed Dataset.
So what exactly is an RDD?
A resilient distributed dataset (RDD) is an immutable collection of objects. These objects are distributed across the different machines available in a cluster. To a Java developer, an RDD is nothing but just like another variable that they can use in their program, similar to an ArrayList. They can directly use it or call some actions on it, for example, count() to figure out the number of elements in it. Behind the job, it sparks tasks that get propagated to the different machines in the cluster and bring back the computed results in a single object as shown in the following example:
JavaRDD<String> rows = sc.textFile("univ_rankings.csv");
System.out.println("Total no. of rows --->"+ rowRdd.count());The preceding code is simple yet it depicts the two powerful concepts of Apache Spark. The first statement shows a Spark RDD object and the second statement shows a simple action. Both of them are explained as follows:
JavaRDD<String>: This is a simple RDD with the namerows. As shown in thegenericsparameter, it is of typestring. So it shows that this immutable collection is filled with string objects. So, if Spark, in this case, is sitting on 10 machines, then this list of strings or RDD will be distributed across the 10 machines. But to the Java developer, this object is just available as another variable and if they need to find the number of elements or rows in it, they just need to invoke an action on it.rows.count(): This is the action that is performed on the RDD and it computes the total elements in the RDD. Behind the scene, this method would run on the different machines of the cluster parallelly and would club the computed result on each parallel node and bring back the result to the end user.
Next we will cover the types of operations that can be run on RDDs. RDDs support two type of operations and they are transformations and actions. We will be covering both in the next sections.
These are used to transform an RDD into just another RDD. This new RDD can later be used in different operations. Let's try to understand this using an example as shown here:
JavaRDD<String> lines = sc.textFile("error.log");As shown in the preceding code, we are pulling all the lines from a log file called error.log into a JavaRDD of strings.
Now, suppose we need to only filter out and use the data rows with the word error in it. To do that, we would use a transformation and filter out the content from the lines RDD, as shown next:
JavaRDD<String> filtered = rowRdd.filter(s -> s.contains("error"));
System.out.println("Total no. of rows --->"+ filtered.count());As you can see in the preceding code, we filtered the RDD based on whether the word error is present in its element or not and the new RDD filtered only contains the elements or objects that have the word error in it. So, transformation on one RDD produces another RDD only.
The user can take some actions on the RDD. For example, if they want to know the total number of elements in the RDD, they can invoke an action count() on it. It's very important to understand that until transformation, everything that happens on an RDD is in lazy mode only; that is, to say that the underlying data remains untouched until that point. It's only when we invoke an action on an RDD that the underlying data gets touched and an operation is performed on it. This is a design-specific approach followed in Spark and this is what makes it so efficient. We actually need the data only when we execute some action on it. What if the user filtered the error log for errors but never uses it? Then storing this data in memory is a waste, so thereby only when some action such as count() is invoked will the actual data underneath be touched.
Here are few common questions:
When RDD is created, can it be reused again and again?
An RDD on which no action has been performed but only transformations are performed can be directly reused again and again. As until that point no underlying data is touched in actuality. However, if an action has been performed on an RDD, then this RDD object is utilized and discarded as soon as it is used. As soon as an action is invoked on an RDD the underlying transformations are then executed or in other words the actual computation then starts and a result is returned. So an action basically helps in the return of a value.
What if I want to re-use the same RDD even after running some action on it?
If you want to reuse the RDD across actions, then you need to persist it or, in other words, cache it and re-use it across operations. Caching an RDD is simple. Just invoke an API call persist and specify the type of persistence. For example, in memory or on disk, and so on. Thereby, the RDD, if small, can be stored in the memory of the individual parallel machines or it could be written to a disk if it is too big to fit into memory.
An RDD that is stored or cached in this way, as mentioned earlier, is reusable only within that session of Spark Context. That is, to say if your program ends the usage ends and all the temp disk files of the storage of RDD are deleted.
So what would you do if you need an RDD again and again in multiple programs going forward in different
SparkContextsessions?In this case, you need to persist and store the RDD in an external storage (such as a file or database) and reuse it. In the case of big data applications, we can store the RDD in HDFS filesystem or we can store it in a database such as HBase and reuse it later when it is needed again.
In real-world applications, you would almost always persist an RDD in memory and reuse it again and again to expedite the different computations you are working on.
What does a general Spark program look like?
Spark is used in massive ETL (extract, transform, and load), predictive analytics, or reporting applications.
Usually the program would do the following:
Load some data into the RDD.
Do some transformation on it to make the data compatible to handle your operations.
Cache the reusable data across sessions (by using persist).
Do some actions on the data; the action can be ready-made or can be custom operations that you wrote in your programs.
Since Spark is written in Scala, which inherently is written in Java, Java is the big brother on the Apache Spark stack and is fully supported on all its products. It has an extensive API on the Apache Spark, stack. On Apache Spark Scala is a popular language of choice but most enterprise projects within big corporations still heavily rely on Java. Thus, for existing java developers on these projects, using Apache Spark and its modules by their java APIs is relatively easy to pick up. Here are some of the Spark APIs that java developers can easily use while doing their big data work:
Accessing the core RDD frameworks and its functions
Accessing Spark SQL code
Accessing Spark Streaming code
Accessing the Spark GraphX library
Accessing Spark MLlib algorithms
Apart from this, Java is very strong on the other big data products as well. To show how strong Java is on the overall big data scene, let's see some examples of big data products that readily support Java:
Working on HBase using Java: HBase has a very strong java API and data can easily be manipulated on it using Java
Working on Hive using Java: Hive is a batch storage product and working on it using Java is easy as it has a good Java API.
Even HDFS supports a Java API for regular file handling operations on HDFS.
All our samples in the book are written using Java 8 on Apache Spark 2.1. Java 8 is aptly suited for big data work mainly because of its support for lambda's, due to which the code is very concise. In the older versions of Java, the Apache Spark Java code was not concise but Java 8 has changed completely.
We will encourage the readers of this book to actively use the Java 8 API on Apache Spark as it not only produces concise code, but overall improves the readability and maintainability of the code. One of the main reasons why scala is heavily used on Apache Spark was mainly due to the concise and easy to use API. But with the usage of Java 8 on Apache Spark, this advantage of Scala is no longer applicable.
Before we use Spark for data analysis, there is some boilerplate code that we always have to write for creating the SparkConfig and creating the SparkContext. Once these objects are created, we can load data from a directory in HDFS.
Note
For all real-world applications, your data would either reside in HDFS or in databases such as Hive/HBase for big data.
Spark lets you load a file in various formats. Let's see an example to load a simple CSV file and count the number of rows in it.
We will first initialize a few parameters, namely, application name, master (whether Spark is locally running this or on a cluster), and the data filename as shown next:
private static String appName =LOAD_DATA_APPNAME"; private static String master =local"; private static String FILE_NAME =univ_rankings.txt";\
Next, we will create the SparkContext and Spark config object:
SparkConf conf =new SparkConf().setAppName(appName).setMaster(master); JavaSparkContext sc =new JavaSparkContext(conf);
Using the SparkContext, we will now load the data file:
JavaRDD<String> rowRdd = sc.textFile(FILE_NAME);
This is the task on which the data analyst would be spending the maximum amount of time on. Most of the time, the data that you would be using for analytics will come from log files or will be generated from other data sources. The data won't be clean and some data entries might be missing or incorrect completely. Before any data analytic tasks can be run on the data, it has to be cleaned and prepared in good shape for the analytic algorithms to run on. We will be covering cleaning and munging in detail in the next chapter.
I assume that you already have Spark installed. If not, refer to the Spark documentation on the web for installing Spark on your machine. Let's now use some popular transformation and actions on Spark.
For the purpose of the following samples, we have used a small dataset of university rankings from Kaggle.com. It can be download from this link: https://www.kaggle.com/mylesoneill/world-university-rankings. It is a comma-separated dataset of university names followed by the country the university is located at. Some sample data rows are shown next:
Harvard University, United States of America
California Institute of Technology, United States of America
Massachusetts Institute of Technology, United States of America …
Common transformations on Spark RDDs
We will now cover a few common transformation operations that we frequently run on the RDDs of Apache Spark:
Filter: This applies a function to each entry of the RDD, for example:
JavaRDD<String> rowRdd = sc.textFile(FILE_NAME); System.out.println(rowRdd.count());
As shown in the preceding code, we loaded the data file using Spark context. Now, using the
filterfunction we will filter out the rows that contain the wordSanta Barbaraas shown next:JavaRDD<String> filteredRows = rowRdd.filter(s -> s.contains("Santa Barbara")); System.out.println(filteredRows.count());Map: This transformation applies a function to each entry of an RDD.
In the RDD we read earlier we will find the length of each row of data using the
mapfunction as shown next:JavaRDD<Integer> rowlengths = rowRdd.map(s -> s.length());
After reading the length of each row in the RDD, we can now collect the data of the RDD and print its content:
List<Integer> rows = rowlengths.collect(); for(Integer row : rows){ System.out.println(row); }FlatMap: This is similar to map, except, in this case, the function applied to each row of RDDs will return a list or sequence of values instead of just one, as in case of the preceding
map. As an example, let's create a sample RDD of strings using theparallelizefunction (this is a handy function for quick testing by creating dummy RDDs):JavaRDD<String> rddX = sc.parallelize( Arrays.asList("big data","analytics","using java"));On this RDD, let's split the strings by the spaces between them:
JavaRDD<String[]> rddY = rddX.map(e -> e.split(" "));Finally,
flatMapwill connect all these words together into a Single List of object as follows:{"big","data","analytics","using","java"} JavaRDD<String> rddY2 = rddX.flatMap(e -> Arrays.asList(e.split(" ")).iterator());We can now collect and print this
rddY2in a similar way as shown here for other RDDs.Other common transformations on RDDs are as follows:
Other transformation
Description
Union
This is a union of two RDDs to create a single one. The new RDD is a union set of both the other RDDs that are combined.
Distinct
This creates an RDD of only distinct elements.
Map paritions
This is similar to a map as shown earlier, but runs separately on each partition block of the RDD.
As mentioned earlier, the actual work on the data starts when an action is invoked. Until that time, all the transformations are tracked on the driver program and sent to the data nodes as a set of tasks.
We will now cover a few common actions that we frequently run on the RDDs of Apache Spark:
count: This is used to count the number of elements of an RDD.For example, the
rowRdd.count()methodwould count the rows in row RDD.collect: This brings back all the data from different nodes into an array on the driver program (It can cause memory leaks on the driver if the driver is low on memory.). This is good for quick testing on small RDDs:JavaRDD<String> rddX = sc.parallelize( Arrays.asList("big data","analytics","using java")); List<String> strs = rddX.collect();This would print the following three strings:
'Big data Analytics Using java'
reduce: This action takes in two parameters and returns one. It is used in aggregating the data elements of an RDD. As an example, let's create a sample RDD using theparallelizefunction:JavaRDD<String> rddX2 = sc.parallelize(Arrays.asList("1","2","3"));After creating the RDD
rddX2, we can sum up all its integer elements by invoking thereducefunction on this RDD:String sumResult = rddX2.reduce((String x, String y)-> { return»»+(Integer.parseInt(x)+ Integer.parseInt(y)); });Finally, we can print the sum of RDD elements:
System.out.println("sumResult ==>"+sumResult);foreach: Just as theforeachloop of Java works in a collection, similarly this action causes each element of the RDD to be accessed:JavaRDD<String> rddX3 = sc.parallelize( Arrays.asList("element-1","element-2","element-3")); rddX3.foreach(f -> System.out.println(f));This will print the output as follows:
element-1 element-2 element-3
As HashMap is a key-value pair collection, similarly, paired RDDs are key-value pair collections except that the collection is a distributed collection. Spark treats these paired RDDs specially and provides special operations on them as shown next.
An example of a paired RDD:
Let's create a sample key-value paired RDD using the parallelize function:
JavaRDD<String> rddX = sc.parallelize(
Arrays.asList("videoName1,5","videoName2,6",
"videoName3,2","videoName1,6"));Now, using the mapToPair function, extract the keys and values from the data rows and return them as an object of a key-value pair or simple a Tuple2:
JavaPairRDD<String, Integer> videoCountPairRdd = rddX.mapToPair((String s)->{
String[] arr = s.split(",");
return new Tuple2<String, Integer>(arr[0],
Integer.parseInt(arr[1]));
});Now, collect and print these rules:
List<Tuple2<String,Integer>> testResults =
videoCountPairRdd.collect();
for(Tuple2<String, Integer> tuple2 : testResults){
System.out.println(tuple2._1);
}This will print the output as follows:
videoName2videoName3videoName1
Just as we can run transformations on plain RDDs we can also run transformations on top of paired RDDs too. Some of the transformations that we can run on paired RDDs are explained as follows:
reduceByKey: This is a transformation operation on a key-value paired RDD. This operation involves shuffling across different data partitions and creates a new RDD. The parameter to this operation is a cumulative function, which is applied on the elements and an aggregation is done on those elements to produce a cumulative result.In the preceding RDD, we have data elements for video name and hit counts of the videos as shown in the following table:
Video name
Hit counts.
videoName15
videoName26
videoName32
videoName16
We will now try to run
reduceByKeyon the paired RDD to find the net hit counts of all the videos as shown earlier.We will be loading the data into an RDD in the same way as shown earlier. Once the data is loaded, we can do a
reduceByKeyto sum up the hit counts on the different videos:JavaPairRDD<String, Integer> sumPairRdd = videoCountPairRdd.reduceByKey((x,y)-> x + y);
After the transformation, we can collect the results and print them as shown next:
List<Tuple2<String,Integer>> testResults = sumPairRdd.collect(); for(Tuple2<String, Integer> tuple2 : testResults){ System.out.println("Title : "+ tuple2._1 + ", Hit Count : "+ tuple2._2); }The results should be printed as follows:
Title : videoName2, Hit Count : 6 Title : videoName3, Hit Count : 2 Title : videoName1, Hit Count : 11
groupByKey: This is another important transformation on a paired RDD. Sometimes, you want to club all the data for a particular key into one iterable unit so that you can later go through it for some specific work.groupByKeydoes this for you, as shown next:JavaPairRDD<String, Iterable<Integer>> grpPairRdd = videoCountPairRdd.groupByKey();
After invoking
groupByKeyonvideoCountPairRdd,we can collect and print the result of this RDD:List<Tuple2<String,Iterable<Integer>>> testResults = grpPairRdd.collect(); for(Tuple2<String, Iterable<Integer>> tuple2 : testResults){ System.out.println("Title : "+ tuple2._1 ); Iterator<Integer> it = tuple2._2.iterator(); int i =1; while(it.hasNext()){ System.out.println("value "+ i +" : "+ it.next()); i++; } }And the results should be printed as follows:
Title : videoName2 value 1 : 6 Title : videoName3 value 1 : 2 Title : videoName1 value 1 : 5 value 2 : 6
As you can see, the contents of the
videoName1key were grouped together and both the counts5and6were printed together.
The contents of an RDD can be stored in external storage. The RDD can later be rebuilt from this external storage too. There are a few handy methods for pushing the contents of an RDD into external storage, which are:
saveAsTextFile(path): This writes the elements of the dataset as atextfile to an external directory in HDFSsaveAsSequenceFile(path): This writes the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem—HDFS or any other Hadoop-supported filesystem
We have already seen in multiple examples earlier that by invoking collect() on an RDD, we can cause the RDD to collect data from different machines on the cluster and bring the data to the driver. Later on, we can print this data too.
When you fire a collect on an RDD at that instant the data from the distributed nodes is pulled and brought into the main node or driver nodes memory. Once the data is available, you can iterate over it and print it on the screen. As the entire data is brought in memory this method is not suitable for pulling a heavy amount of data as that data might not fit in the driver memory and an out of memory error might be thrown. If the amount of data is large and you want to peek into the elements of that data then you can save your RDD in external storage in Parquet or text format and later analyze it using analytic tools like Impala or Spark SQL. There is also another method called take that you can invoke on the Spark RDD. This method allows you to pull a subset of elements from the first element of the arrays. Thereby take method can be used when you need to view just a few lines from the RDD to check if your computations are good or not.
Apache Spark comes with a script spark-submit in its bin directory. Using this script, you can submit your program as a job to the cluster manager (such as Yarn) of Spark and it would run this program. These are the typical steps in running a Spark program:
Create a
jarfile of your Spark Java code.Next, run the
spark-submitjob by giving the location of thejarfile and the main class in it. An example of the command is shown next:./bin/spark-submit --class <main-class> --master <master-url><application-jar>
Some of the commonly used options of spark-submit are shown in the following table:
|
spark-submit options |
What it does |
|---|---|
|
|
Your Java class that is the main entry point for the spark code execution. |
|
|
Master URL for the cluster |
|
|
Jar file containing your Apache spark code |
Apache Spark has now become a complete ecosystem of many sub-projects. For different operations on it, we have different products as shown next:
|
Spark sub-module |
What it does |
|---|---|
|
Core Spark |
This is the foundation framework for all the other modules. It has the implementation for Spark computing engine, that is, RDD, executors, storage, and so on. |
|
Spark SQL |
Spark SQL is a Spark module for structured data processing. Using this you can fire SQL queries on your distributed datasets. It's very easy to use. |
|
Spark Streaming |
This module helps in processing live data streams, whether they are coming from products such as Kafka, Flume, or Twitter. |
|
GraphX |
Helps in building components for Spark parallel graph computations. |
|
MLlib |
This is a machine learning library that is built on the top of the Spark core and hence the algorithms are parallelly distributable across the massive datasets. |
Spark MLlib is Spark's implementation of the machine learning algorithms based on the RDD format. It consists of the algorithms that can be easily run across a cluster of computer machines parallelly. Hence, it is much faster and scalable than single node machine learning libraries such as scikit-learn. This module allows you to run machine learning algorithms on top of RDDs. The API is not very user friendly and sometimes it is difficult to use.
Recently Spark has come up with the new Spark ML package, which essentially builds on top of the Spark dataset API. As such, it inherits all the good features of the datasets that are massive scalability and extreme ease of usage. If anybody has used the very popular Python scikit library for machine learning, they would realize that the API of the new Spark ML is quite similar to Python scikit. From the Spark documentation, Spark ML is the recommended way for doing machine learning tasks now and the old Spark MLlib RDD based API would get deprecated in some time.
Spark ML being based on datasets allows us to use Spark SQL along with it. Feature extraction and feature manipulation tasks become very easy as a lot can now be handled using Spark SQL only, especially the data manipulation work using plain SQL queries. Apart from this, Spark ML ships with an advanced feature called Pipeline. Plain data is usually in an extremely raw format and this data usually goes through a cycle or workflow where it gets cleaned, mutated, and transformed before it is used for consumption and training of machine learning models. This entire workflow of data and its stages is very well encapsulated in the new feature called as Pipeline in the Spark ML library. So you can work on the different workflows whether for feature extraction, feature transformation or converting features to mathematical vector format and gel together all this code using the pipeline API of Spark ML. This helps us in maintaining large code bases of machine learning stacks, so if later on you want to switch some piece of code (for example, for feature extraction), you can separately change it and then hook it into the pipeline and this would work cleanly without changing or impacting any other area of code.
There are many machine learning libraries currently out there. Some of the popular ones are scikit-learn, pybrain, and so on. But as I mentioned earlier, these are single node libraries that are built to run on one machine but the algorithms are not optimized to run parallelly across a stack of machines and then club the results.
Note
How do you use these libraries on big data in case there is a particular algorithm implementation that you want to use from these libraries?
On all the parallel nodes that are running your Spark tasks, make sure the particular installation of the specific library is present. Also any jars or executables that are required to run the algorithm must be available in the path of the spark-submit job to run this.
Apache Mahout is also a popular library and is open source from the Apache stack. It contains scalable machine learning algorithms. Some of the algorithms can be used for tasks such as:
Recommendations
Classfications
Clustering
Some important features of Mahout are as follows:
Its algorithms run on Hadoop so they work well in a distributed environment
It has MapReduce implementations of several algorithms
This library is fully built on Java and is a deep learning library. We will cover this library in our chapter on deep learning.
Big data is distributed data that is spread across many different machines. For various operations running on data, data transfer across machines is a given. These are the formats supported on Hadoop for input compression: gzip, bzip, snappy, and so on. While we won't go into detail for the compression piece, it must be understood that when you actually work on big data analytics tasks, compressing your data will be always beneficial, providing few main advantages as follows:
If the data is compressed, the data transfer bandwidth needed is less and as such the data would transfer fast.
Also, the amount of storage needed for compressed data is much less.
Hadoop ships with a set of compression formats that support easy distributability across a cluster of machines. So even if the compressed files are chuncked and distributed across a cluster of machines, you would be able to run your programs on them without loosing any information or important data points.
Spark helps in writing the data to Hadoop and in Hadoop input/output formats. Avro and Parquet are two popular Hadoop file formats that have specific advantages. For the purpose of our examples, other than the usual file formats of data, such as log and text format, the files can also be present in Avro or Parquet format.
So what is Avro and Parquet and what is special about them?
Avro is a row-based format and is also schema based. The schema for the structure of the data row is stored within the file; due to this, the schema can independently change and there won't be any impact on reading old files. Also, since it is in row-based format, the files can easily be split, based on rows and put on multiple machines and processed parallely. It has good failover support too.
Parquet is a columnar file format. Parquet is specifically suited for applications where for analytics you only need a subset of your columnar data and not all the columns. So for things such as summing up/aggregating specific column Parquet is best suited for such operations. Since Parquet helps in choosing only the columns that are needed, it reduces disk I/O tremendously and hence it reduces the time for running analytics on the data.