

In this recipe, we are going to learn how to install a single-node Hadoop cluster, which can be used for development and testing.
To install Hadoop, you need to have a machine with the UNIX operating system installed on it. You can choose from any well known UNIX OS such as Red Hat, CentOS, Ubuntu, Fedora, and Amazon Linux (this is in case you are using Amazon Web Service instances).
Here, we will be using the Ubuntu distribution for demonstration purposes.
Let's start installing Hadoop:
First of all, you need to download the required installers from the Internet. Here, we need to download Java and Hadoop installers. The following are the links to do this:
For the Java download, choose the latest version of the available JDK from http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html.
You can also use Open JDK instead of Oracle.
For the Hadoop 2.7 Download, go to
http://www.eu.apache.org/dist/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz.
We will first install Java. Here, I am using
/usr/localas the installation directory and therootuser for all installations. You can choose a directory of your choice.Extract
tar.gzlike this:tar -xzf java-7-oracle.tar.gzRename the extracted folder to give the shorter name Java instead of java-7-oracle. Doing this will help you remember the folder name easily.
Alternately, you can install Java using the
apt-getpackage manager if your machine is connected to the Internet:sudo apt-get update sudo apt-get install openjdk-7-jdk
Similarly, we will extract and configure Hadoop. We will also rename the extracted folder for easier accessibility. Here, we will extract Hadoop to
path /usr/local:tar –xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Next, in order to use Java and Hadoop from any folder, we would need to add these paths to the
~/.bashrcfile. The contents of the file get executed every time a user logs in:cd ~ vi .bashrc
Once the file is open, append the following environment variable settings to it. These variables are used by Java and Hadoop at runtime:
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
In order to verify whether our installation is perfect, close the terminal and restart it again. Also, check whether the Java and Hadoop versions can be seen:
$java -version java version "1.7.0_45" Java(TM) SE Runtime Environment (build 1.7.0_45-b18) Java HotSpot(TM) Server VM (build 24.45-b08, mixed mode) $ hadoop version Hadoop 2.7.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r d4c8d4d4d203c934e8074b31289a28724c0842cf Compiled by jenkins on 2015-04-10T18:40Z Compiled with protoc 2.5.0 From source with checksum a9e90912c37a35c3195d23951fd18f
This command was run using
/usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.0.jar.Now that Hadoop and Java are installed and verified, we need to install
ssh(Secure Shell) if it's not already available by default. If you are connected to the Internet, execute the following commands.SSHis used to secure data transfers between nodes:sudo apt-get install openssh-client sudo apt-get install openssh-server
Once the
sshinstallation is done, we need to execute thesshconfiguration in order to avail a passwordless access to remote hosts. Note that even though we are installing Hadoop on a single node, we need to perform ansshconfiguration in order to securely access the localhost.First of all, we need to generate public and private keys by executing the following command:
ssh-keygen -t rsa -P ""This will generate the private and public keys by default in the
$HOME/.sshfolder. In order to provide passwordless access, we need to append the public key toauthorized_keysfile:cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keysLet's check whether the
sshconfiguration is okay or not. To test it, execute and connect to the localhost like this:ssh localhostThis will prompt you to confirm whether to add this connection to the
known_hostsfile. Typeyes, and you should be connected tosshwithout prompting for the password.Once the
sshconfiguration is done and verified, we need to configure Hadoop. The Hadoop configuration begins with adding various configuration parameters to the following default files:hadoop-env.sh: This is where we need to perform the Java environment variable configuration.core-site.xml: This is where we need to performNameNode-related configurations.yarn-site.xml: This is where we need to perform configurations related to Yet Another Resource Negotiator (YARN).mapred-site.xml: This is where we need to the map reduce engine as YARN.hdfs-site.xml: This is where we need to perform configurations related to Hadoop Distributed File System (HDFS).
These configuration files can be found in the
/usr/local/hadoop/etc/hadoopfolder. If you install Hadoop as the root user, you will have access to edit these files, but if not, you will first need to get access to this folder before editing.
So, let's take a look at the configurations one by one.
Configure hadoop-env.sh and update the Java path like this:
Export
JAVA_HOME=/usr/local/java.Edit
core-site.xml, and add the host and port on which you wish to installNameNode. Here is the single node installation that we would need in order to add the localhost:<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000/</value> </property> </configuration>Edit
yarn-site.xml, add the following properties to it:<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>The
yarn.nodemanager.aux-servicesproperty tellsNodeManagerthat an auxiliary service namedmapreduce.shuffleis present and needs to be implemented. The second property tellsNodeManagerabout the class by which means it needs to implement the shuffle auxiliary service. This specific configuration is needed as theMapReducejob involves shuffling of key value pairs.Next, edit
mapred-site.xmlto set the map reduce processing engine as YARN:<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>Edit
hdfs-site.xmlto set the folder paths that can be used byNameNodeanddatanode:<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>I am also setting the HDFS block replication factor to
1as this is a single node cluster installation.We also need to make sure that we create the previously mentioned folders and change their ownership to suit the current user. To do this, you can choose a folder path of your own choice:
sudo mkdir –p /usr/local/store/hdfs/namenode sudo mkdir –p /usr/local/store/hdfs/datanode sudo chown root:root –R /usr/local/store
Now, it's time to format
namenodeso that it creates the required folder structure by default:hadoop namenode -formatThe final step involves starting Hadoop daemons; here, we will first execute two scripts to start HDFS daemons and then start YARN daemons:
/usr/local/hadoop/sbin/start-dfs.sh
This will start NameNode, the secondary NameNode, and then DataNode daemons:
/usr/local/hadoop/sbin/start-yarn.sh
This will start NodeManager and ResourceManager. You can execute the jps command to take a look at the running daemons:
$jps 2184 DataNode 2765 NodeManager 2835 Jps 2403 SecondaryNameNode 2025 NameNode 2606 ResourceManager
We can also access the web portals for HDFS and YARN by accessing the following URLs:
For HDFS:
http://<hostname>:50070/For YARN:
http://<hostname>:8088/
Hadoop 2.0 has been majorly reformed in order to solve issues of scalability and high-availability. Earlier in Hadoop 1.0, Map Reduce was the only means of processing data stored in HDFS. With advancement of YARN, Map Reduce is one of the ways of processing data on Hadoop. Here is a pictorial difference between Hadoop 1.x and Hadoop 2.x:
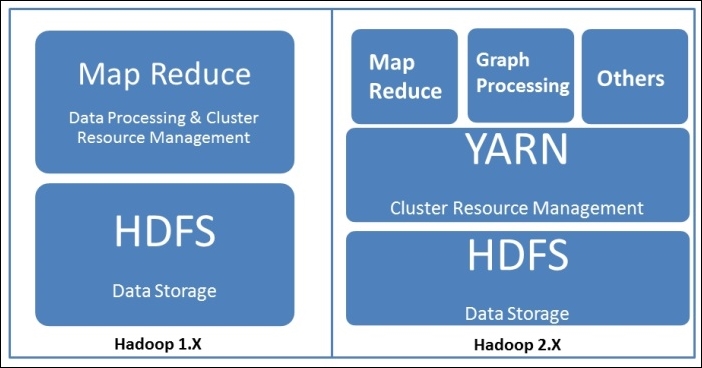
Now, let's try to understand how HDFS and YARN works.
HDFS is a redundant, reliable storage for Hadoop. It consists of three important parts: NameNode, the secondary NameNode, and DataNodes. When a file needs to be processed on Hadoop, it first needs to be saved on HDFS. HDFS distributes the file in chunks of 64/128 MB data blocks across the data nodes. The blocks are replicated across data nodes for reliability. NameNode stores the metadata in the blocks and replicas. After a certain period of time, the metadata is backed up on the secondary NameNode. The default time is 60 seconds. We can modify this by setting a property called dfs.namenode.checkpoint.check.period in hdfs-site.xml.
YARN has been developed to address scalability issues and for the better management of jobs in Hadoop; till date, it has proved itself to be the perfect solution. It is responsible for the management of resources available in clusters. It consists of two important components: ResouceManager(Master) and NodeManager(Worker). NodeManager provides a node-level view of the cluster, while ResourceManager takes a view of a cluster. When an application is submitted by an application client, the following things happen:
The application talks to
ResourceManagerand provides details about it.ResourceManagermakes a container request on behalf of an application to any of the worker nodes andApplicationMasterstarts running within that container.ApplicationMasterthen makes subsequent requests for the containers to execute tasks on other nodes.These tasks then take care of all the communication. Once all the tasks are complete, containers are deallocated and
ApplicationMasterexits.After this, the application client also exits.
Now that your single node Hadoop cluster is up and running, you can try some HDFS file operations on it, such as creating a directory, copying a file from a local machine to HDFS, and so on. Here some sample commands.
To list all the files in the HDFS root directory, take a look at this:
hadoop fs –ls /
To create a new directory, take a look at this:
hadoop fs –mkdir /input
To copy a file from the local machine to HDFS, take a look at this:
hadoop fs –copyFromLocal /usr/local/hadoop/LICENSE.txt /input
In order to access all the command options that are available, go to https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html.