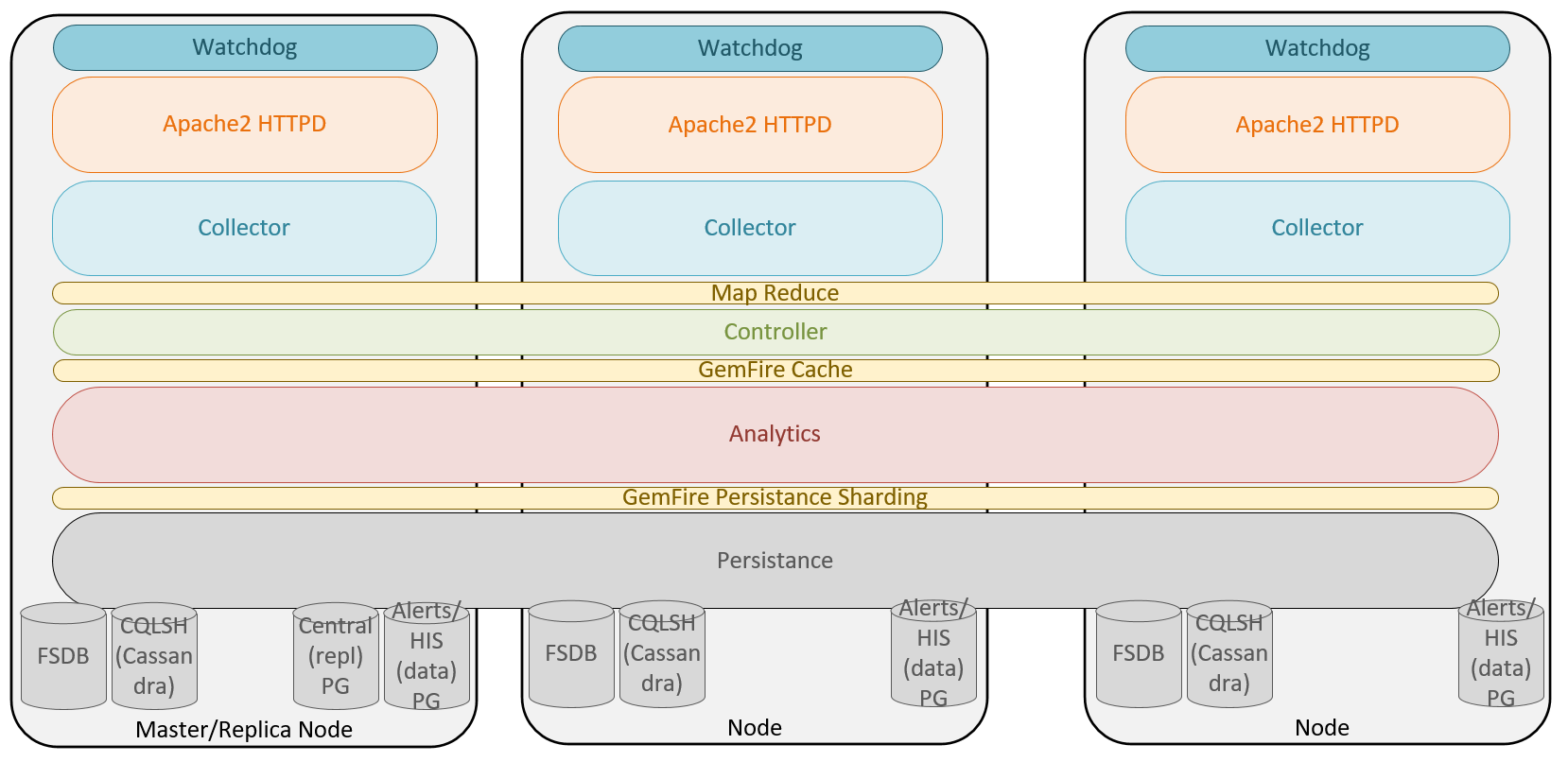
One of the biggest advantages of a GemFire-based cluster is the elasticity of adding nodes to the cluster as the number of resources and metrics grows in your environment. This allows administrators to add or remove nodes if the size of their environment changes unexpectedly; for example, a merger with another IT department, or catering for seasonal workloads that only exist for a small period of the year.
From a deployment perspective, we want to hide the complexities of scaling out from the user, so we deploy the whole stack at a time. When one instance/slice of the stack runs out of capacity (CPU/disk/memory), we can spin up another, and add more capacity. We can keep doing this as necessary to handle the scale.
Although adding nodes to an existing cluster is something that can be done at any time, there is a slight cost when doing so. As just mentioned, it is important when adding new nodes that they are sized the same as the existing cluster nodes; this will ensure during a rebalance operation that the load is distributed equally between the cluster nodes:

When adding new nodes to the cluster sometime after initial deployment, it is recommended that the Rebalance Disk option be selected under Cluster Management. As seen in the preceding figure, the warning advises that this is a very disruptive operation that may take hours and, as such, it is recommended that this be a planned maintenance activity. The amount of time this operation will take will vary depending on the size of the existing cluster and the amount of data in the FSDB. As you can probably imagine, if you are adding the eighth node to an existing seven-node cluster with tens of thousands of resources, there could potentially be several TBs of data that need to be re-sharded over the entire cluster. It is also strongly recommended that when adding new nodes the disk capacity and performance match that of existing nodes, as the Rebalance Disk operation assumes this is the case.
This activity is not required to start receiving the compute and network load balancing benefits of the new node. This can be achieved by selecting the Rebalance GemFire option, which is a far less disruptive process. As per the description, this process re-partitions the JVM buckets, balancing the memory across all active nodes in the GemFire federation. With the GemFire cache balanced across all nodes, the compute and network demand should be roughly equal across all the nodes in the cluster.
Although this allows early benefit from adding a new node into an existing cluster, unless a large number of new resources is discovered by the system shortly afterward, the majority of disk I/O for persisted, sharded data will occur on other nodes.
Apart from adding nodes, vRealize Operations also allows the removal of a node at any time, as long as it has been taken offline first. This can be valuable if a cluster was originally oversized for a requirement, and is considered a waste of physical compute resource; however, this task should not be taken lightly, as the removal of a data node without HA enabled will result in the loss of all metrics on that node. As such, it is recommended that removing nodes from the cluster is generally avoided.
If the permanent removal of a data node is necessary, ensure HA is first enabled to prevent data loss.