

In this recipe, we will set up a simple sharded setup made up of two data shards. There will be no replication to keep it simple, as this is the most basic shard setup to demonstrate the concept. We won't be getting deep into the internals of sharding, which we will explore further in Chapter 4, Administration.
Here is a bit of theory before we proceed. Scalability and availability are two important cornerstones for building any mission-critical application. Availability is something that was taken care of by replica sets, which we discussed in the previous recipes of this chapter. Let's look at scalability now. Simply put, scalability is the ease with which the system can cope with an increasing data and request load. Consider an e-commerce platform. On regular days, the number of hits to the site and load is fairly modest, and the system response times and error rates are minimal (this is subjective).
Now, consider the days where the system load becomes twice or three times an average day's load (or even more), for example, say on Thanksgiving Day, Christmas, and so on. If the platform is able to deliver similar levels of service on these high-load days compared with any other day, the system is said to have scaled up well to the sudden increase in the number of requests.
Now, consider an archiving application that needs to store the details of all the requests that hit a particular website over the past decade. For each request that hits the website, we will create a new record in the underlying data store. Suppose each record is of 250 bytes with an average load of 3 million requests per day, then we will cross the 1 TB data mark in about 5 years. This data will be used for various analytic purposes and might be frequently queried. The query performance should not be drastically affected when the data size increases. If the system is able to cope with this increasing data volume and still gives a decent performance comparable to that on low data volumes, the system is said to have scaled up well against the increasing data volumes.
Now that we have seen in brief what scalability is, let me tell you that sharding is a mechanism that lets a system scale to increasing demands. The crux lies in the fact that the entire data is partitioned into smaller segments and distributed across various nodes called shards. Let's assume that we have a total of 10 million documents in a Mongo collection. If we shard this collection across 10 shards, we will ideally have 10,000,000/10 = 1,000,000 documents on each shard. At a given point of time, one document will only reside on one shard (which, by itself, will be a replica set in a production system). There is, however, some magic involved that keeps this concept hidden from the developer querying the collection, who gets one unified view of the collection irrespective of the number of shards. Based on the query, it is Mongo that decides which shard to query for the data and return the entire result set. With this background, let's set up a simple shard and take a closer look at it.
Apart from the MongoDB server already installed, there are no prerequisites from a software perspective. We will create two data directories, one for each shard. There will be one directory for data and one for logs.
Let's take a look at the steps in detail:
We will start by creating directories for logs and data. Create the
/data/s1/db,/data/s2/db, and/logsdirectories. On Windows, we can havec:\data\s1\db, and so on for thedataandlogdirectories. There is also a config server that is used in a sharded environment to store some metadata. We will use/data/con1/dbas the data directory for the config server.Start the following
mongodprocesses, one for each of the two shards and one for the config database, and onemongosprocess (we will see what this process does). For the Windows platform, skip the--forkparameter as it is not supported:$ mongod --shardsvr --dbpath /data/s1/db --port 27000 --logpath /logs/s1.log --smallfiles --oplogSize 128 --fork $ mongod --shardsvr --dbpath /data/s2/db --port 27001 --logpath /logs/s2.log --smallfiles --oplogSize 128 --fork $ mongod --configsvr --dbpath /data/con1/db --port 25000 --logpath /logs/config.log --fork $ mongos --configdb localhost:25000 --logpath /logs/mongos.log --fork
In the command prompt, execute the following command. This will show a
mongosprompt:$ mongo MongoDB shell version: 2.4.6 connecting to: test mongos>
Finally, we set up the shard. From the
mongosshell, execute the following two commands:mongos> sh.addShard("localhost:27000") mongos> sh.addShard("localhost:27001")
On the addition of each shard, we will get an
okreply. Something like the following JSON message will be seen giving the unique ID for each shard that is added:{ "shardAdded" : "shard0000", "ok" : 1 }
Let's see what we did in the process. We created three directories for data (two for the shards and one for the config database) and one directory for logs. We can have a shell script or a batch file to create the directories as well. In fact, in large production deployments, setting up shards manually is not only time-consuming but also error-prone.
Let's try to get a picture of what exactly we have done and what we are trying to achieve.
The following diagram shows the shard setup we just built:
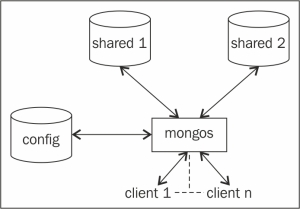
If we look at the preceding diagram and the servers started in step 2, we will see that we have shard servers that will store the actual data in the collections. These were the first two of the four processes that started listening to port 27000 and 27001. Next, we started a config server, which is seen on the left-hand side in the preceding diagram. It is the third server of the four servers started in step 2, and it listens to port 25000 for incoming connections. The sole purpose of this database is to maintain the metadata of the shard servers. Ideally, only the mongos process or drivers connect to this server for the shard details/metadata and the shard key information. We will see what a shard key is in the next recipe, where we will play around with a sharded collection and see the shards we created in action.
Finally, we have a mongos process. This is a lightweight process that doesn't do any persistence of data and just accepts connections from clients. This is the layer that acts as a gatekeeper and abstracts the client from the concept of shards. For now, we can view it as a router that consults the config server and takes the decision to route the client's query to the appropriate shard server for execution. It then aggregates the result from various shards if applicable and returns the result to the client. It is safe to say that no client directly connects to the config or the shard servers; in fact, ideally, no one should connect to these processes directly, except for some administration operations. Clients simply connect to the mongos process and execute their queries, or insert or update operations.
Just by starting the shard servers, the config server and mongos process don't create a sharded environment. On starting up the mongos process, we provided it with the details of the config server. What about the two shards that will be storing the actual data? The two mongod processes that started as shard servers are, however, not yet declared anywhere as shard servers in the configuration. That is exactly what we do in the final step by invoking sh.addShard() for both the shard servers. The mongos process is provided with the config server's details on startup. Adding shards from the shell stores this metadata about the shards in the config database; then, the mongos processes will query this config database for the shard's information. On executing all the steps of this recipe, we will have an operational shard. Before we conclude, the shard we set up here is far from ideal and not how it will be done in the production environment. The following diagram gives us an idea of how a typical shard will be in a production environment:
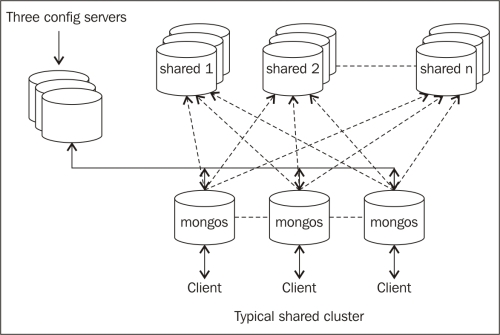
The number of shards will not be two but much more. Also, each shard will be a replica set to ensure high availability. There will be three config servers to ensure the availability of the config servers too. Similarly, there will be any number of mongos processes created for a shard that listens for client connections. In some cases, it might even be started on a client application's server.