

When we try to find or calculate interesting information from large datasets, often we need to calculate more complicated algorithms than the algorithms we discussed so far. There are many such algorithms available (for example clustering, collaborative filtering, and data mining algorithms). This recipe will implement one such algorithm called Kmeans that belongs to clustering algorithms.
Let us assume that the Amazon dataset includes customer locations. Since that information is not available, we will create a dataset by picking random values from IP addresses to the latitude and longitude dataset available from http://www.infochimps.com/datasets/united-states-ip-address-to-geolocation-data.
If we can group the customers by geo location, we can provide more specialized and localized services. In this recipe, we will implement the Kmeans clustering algorithm using MapReduce and use that identify the clusters based on geo location of customers.
A clustering algorithm groups a dataset into several groups called clusters such that data points within the same cluster are much closer to each other than data points between two different clusters. In this case, we will represent the cluster using the center of it's data points.
This assumes that you have installed Hadoop and started it. Writing a word count application using Java (Simple) and Installing Hadoop in a distributed setup and running a word count application (Simple) recipes for more information. We will use
HADOOP_HOMEto refer to the Hadoop installation directory.This recipe assumes you are aware of how Hadoop processing works. If you have not already done so, you should follow the Writing a word count application with MapReduce and running it (Simple) recipe.
Download the sample code for the chapter and download the data files from http://www.infochimps.com/datasets/united-states-ip-address-to-geolocation-data.
Unzip the geo-location dataset to a directory of your choice. We will call this
GEO_DATA_DIR.Change the directory to
HADOOP_HOMEand copy thehadoop-microbook.jarfile fromSAMPLE_DIRtoHADOOP_HOME.Generate the sample dataset and initial clusters by running the following command. It will generate a file called
customer-geo.data.> java –cp hadoop-microbook.jar microbook.kmean.GenerateGeoDataset GEO_DATA_DIR/ip_blocks_us_geo.tsv customer-geo.dataUpload the dataset to the HDFS filesystem.
> bin/hadoop dfs -mkdir /data/ > bin/hadoop dfs -mkdir /data/kmeans/ > bin/hadoop dfs -mkdir /data/kmeans-input/ > bin/hadoop dfs -put HADOOP_HOME/customer-geo.data /data/kmeans-input/
Run the MapReduce job to calculate the clusters. To do that run the following command from
HADOOP_HOME. Here,5stands for the number of iterations and10stands for number of clusters.$ bin/hadoop jar hadoop-microbook.jar microbook.kmean.KmeanCluster /data/kmeans-input/ /data/kmeans-output 5 10The execution will finish and print the final clusters to the console, and you can also find the results from the output directory,
/data/kmeans-output.
You can find the mapper and reducer code from src/microbook/KmeanCluster.java. This class includes the map function, reduce function, and the driver program.
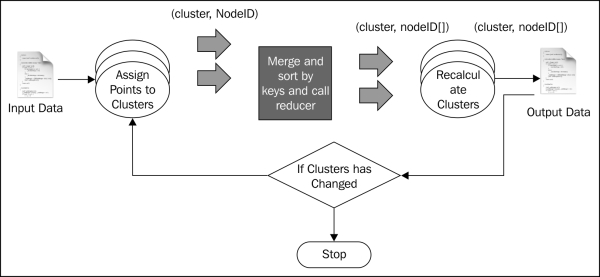
When started, the driver program generates 10 random clusters, and writes them to a file in the HDFS filesystem. Then, it invokes the MapReduce job once for each iteration.
The preceding figure shows the execution of two MapReduce jobs. This recipe belongs to the iterative MapReduce style where we iteratively run the MapReduce program until the results converge.
When the MapReduce job is invoked, Hadoop invokes the setup method of mapper class, where the mapper loads the current clusters into memory by reading them from the HDFS filesystem.
As shown by the figure, Hadoop will read the input file from the input folder and read records using the custom formatter, that we introduced in the Write a formatter (Intermediate) recipe. It invokes the mapper once per each record passing the record as input.
When the mapper is invoked, it parses and extracts the location from the input, finds the cluster that is nearest to the location, and emits that cluster ID as the key and the location as the value. The following code listing shows the map function:
public void map(Object key, Text value, Context context) {
Matcher matcher = parsingPattern.matcher(value.toString());
if (matcher.find()) {
String propName = matcher.group(1);
String propValue = matcher.group(2);
String[] tokens = propValue.split(",");
double lat = Double.parseDouble(tokens[0]);
double lon = Double.parseDouble(tokens[1]);
int minCentroidIndex = -1;
double minDistance = Double.MAX_VALUE;
int index = 0;
for(Double[] point: centriodList){
double distance =
Math.sqrt(Math.pow(point[0] -lat, 2)
+ Math.pow(point[1] -lon, 2));
if(distance < minDistance){
minDistance = distance;
minCentroidIndex = index;
}
index++;
}
Double[] centriod = centriodList.get(minCentroidIndex);
String centriodAsStr = centriod[0] + "," + centriod[1];
String point = lat +"," + lon;
context.write(new Text(centriodAsStr), new Text(point));
}
}MapReduce will sort the key-value pairs by the key and invoke the reducer once for each unique key passing the list of values emitted against that key as the input.
The reducer receives a cluster ID as the key and the list of all locations that are emitted against that cluster ID. Using these, the reducer recalculates the cluster as the mean of all the locations in that cluster and updates the HDFS location with the cluster information. The following code listing shows the reducer function:
public void reduce(Text key, Iterable<Text> values,
Context context)
{
context.write(key, key);
//recalcualte clusters
double totLat = 0;
double totLon = 0;
int count = 0;
for(Text text: values){
String[] tokens = text.toString().split(",");
double lat = Double.parseDouble(tokens[0]);
double lon = Double.parseDouble(tokens[1]);
totLat = totLat + lat;
totLon = totLon + lon;
count++;
}
String centroid = (totLat/count) + "," + (totLon/count);
//print them out
for(Text token: values){
context.write(new Text(token), new Text(centroid));
}
FileSystem fs =FileSystem.get(context.getConfiguration());
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter(fs.create(new Path("/data/kmeans/clusters.data"), true)));
bw.write(centroid);bw.write("\n");
bw.close();
}The driver program continues above per each iteration until input cluster and output clusters for a MapReduce job are the same.
The algorithm starts with random cluster points. At each step, it assigns locations to cluster points, and at the reduced phase it adjusts each cluster point to be the mean of the locations assigned to each cluster. At each iteration, the clusters move until the clusters are the best clusters for the dataset. We stop when clusters stop changing in the iteration.
One limitation of the Kmeans algorithm is that we need to know the number of clusters in the dataset. There are many other clustering algorithms. You can find more information about these algorithms from the Chapter 7 of the freely available book Mining of Massive Datasets, Anand Rajaraman and Jeffrey D. Ullman, Cambridge University Press, 2011.