

This recipe explains how to implement a simple MapReduce program to count the number of occurrences of words in a dataset. WordCount is famous as the HelloWorld equivalent for Hadoop MapReduce.
To run a MapReduce job, users should supply a map function, a reduce function, input data, and a location to store the output data. When executed, Hadoop carries out the following steps:
Hadoop uses the supplied InputFormat to break the input data into key-value pairs and invokes the
mapfunction for each key-value pair, providing the key-value pair as the input. When executed, themapfunction can output zero or more key-value pairs.Hadoop transmits the key-value pairs emitted from the Mappers to the Reducers (this step is called Shuffle). Hadoop then sorts these key-value pairs by the key and groups together the values belonging to the same key.
For each distinct key, Hadoop invokes the reduce function once while passing that particular key and list of values for that key as the input.
The
reducefunction may output zero or more key-value pairs, and Hadoop writes them to the output data location as the final result.
Select the source code for the first chapter from the source code repository for this book. Export the $HADOOP_HOME environment variable pointing to the root of the extracted Hadoop distribution.
Now let's write our first Hadoop MapReduce program:
The WordCount sample uses MapReduce to count the number of word occurrences within a set of input documents. The sample code is available in the
chapter1/Wordcount.javafile of the source folder of this chapter. The code has three parts—Mapper, Reducer, and the main program.The Mapper extends from the
org.apache.hadoop.mapreduce.Mapperinterface. Hadoop InputFormat provides each line in the input files as an input key-value pair to themapfunction. Themapfunction breaks each line into substrings using whitespace characters such as the separator, and for each token (word) emits(word,1)as the output.public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // Split the input text value to words StringTokenizer itr = new StringTokenizer(value.toString()); // Iterate all the words in the input text value while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, new IntWritable(1)); } }Each
reducefunction invocation receives a key and all the values of that key as the input. Thereducefunction outputs the key and the number of occurrences of the key as the output.public void reduce(Text key, Iterable<IntWritable>values, Context context) throws IOException, InterruptedException { int sum = 0; // Sum all the occurrences of the word (key) for (IntWritableval : values) { sum += val.get(); } result.set(sum); context.write(key, result); }The
maindriver program configures the MapReduce job and submits it to the Hadoop YARN cluster:Configuration conf = new Configuration(); …… // Create a new job Job job = Job.getInstance(conf, "word count"); // Use the WordCount.class file to point to the job jar job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // Setting the input and output locations FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, newPath(otherArgs[1])); // Submit the job and wait for it's completion System.exit(job.waitForCompletion(true) ? 0 : 1);
Compile the sample using the Gradle build as mentioned in the introduction of this chapter by issuing the
gradle buildcommand from thechapter1folder of the sample code repository. Alternatively, you can also use the provided Apache Ant build file by issuing theant compilecommand.Run the WordCount sample using the following command. In this command,
chapter1.WordCountis the name of themainclass.wc-inputis the input data directory andwc-outputis the output path. Thewc-inputdirectory of the source repository contains a sample text file. Alternatively, you can copy any text file to thewc-inputdirectory.$ $HADOOP_HOME/bin/hadoop jar \ hcb-c1-samples.jar \ chapter1.WordCount wc-input wc-output
The output directory (
wc-output) will have a file namedpart-r-XXXXX, which will have the count of each word in the document. Congratulations! You have successfully run your first MapReduce program.$ cat wc-output/part*
In the preceding sample, MapReduce worked in the local mode without starting any servers and using the local filesystem as the storage system for inputs, outputs, and working data. The following diagram shows what happened in the WordCount program under the covers:
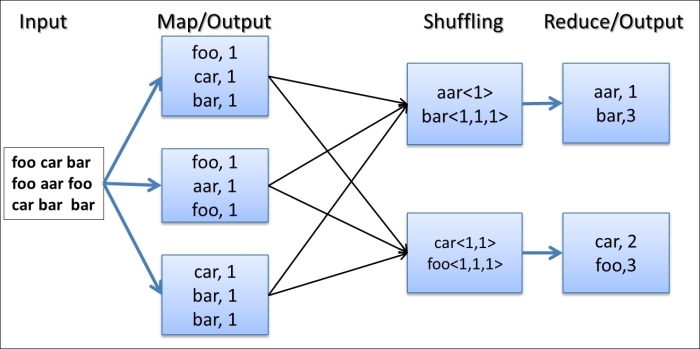
The WordCount MapReduce workflow works as follows:
Hadoop reads the input, breaks it using new line characters as the separator and then runs the
mapfunction passing each line as an argument with the line number as the key and the line contents as the value.The
mapfunction tokenizes the line, and for each token (word), emits a key-value pair(word,1).Hadoop collects all the
(word,1)pairs, sorts them by the word, groups all the values emitted against each unique key, and invokes thereducefunction once for each unique key passing the key and values for that key as an argument.The
reducefunction counts the number of occurrences of each word using the values and emits it as a key-value pair.Hadoop writes the final output to the output directory.
As an optional step, you can set up and run the WordCount application directly from your favorite Java Integrated Development Environment (IDE). Project files for Eclipse IDE and IntelliJ IDEA IDE can be generated by running gradle eclipse and gradle idea commands respectively in the main folder of the code repository.
For other IDEs, you'll have to add the JAR files in the following directories to the class-path of the IDE project you create for the sample code:
{HADOOP_HOME}/share/hadoop/common{HADOOP_HOME}/share/hadoop/common/lib{HADOOP_HOME}/share/hadoop/mapreduce{HADOOP_HOME}/share/hadoop/yarn{HADOOP_HOME}/share/hadoop/hdfs
Execute the chapter1.WordCount class by passing wc-input and wc-output as arguments. This will run the sample as before. Running MapReduce jobs from IDE in this manner is very useful for debugging your MapReduce jobs.
Although you ran the sample with Hadoop installed in your local machine, you can run it using the distributed Hadoop cluster setup with an HDFS-distributed filesystem. The Running the WordCount program in a distributed cluster environment recipe of this chapter will discuss how to run this sample in a distributed setup.