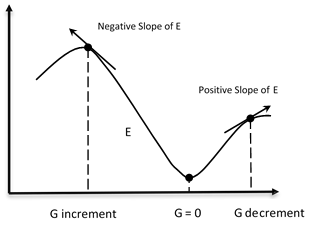
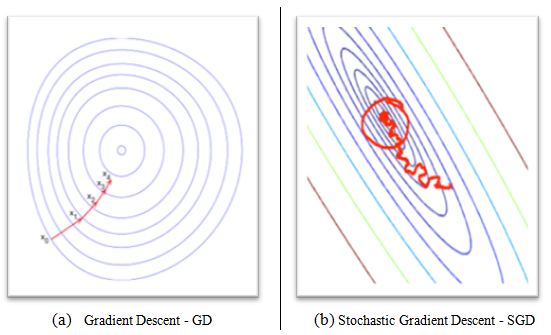
The learning process of a neural network is configured as an iterative process of optimization of the weights, and is therefore of the supervised type. The weights are modified based on the network performance on a set of examples belonging to the training set, where the category they belong to is known. The aim is to minimize a loss function, which indicates the degree to which the behavior of the network deviates from the desired one. The performance of the network is then verified on a test set consisting of objects (for example, images in a image classification problem) other than those of the training set.
-
Book Overview & Buying

-
Table Of Contents

Deep Learning with TensorFlow
By :
Deep Learning with TensorFlow
By:
Overview of this book
Deep learning is the step that comes after machine learning, and has more advanced
implementations. Machine learning is not just for academics anymore, but is becoming a mainstream practice through wide adoption, and deep learning has taken the front seat. As a data scientist, if you want to explore data abstraction layers, this book will be your guide. This book shows how this can be exploited in the real world with complex raw data using TensorFlow 1.x.
Throughout the book, you’ll learn how to implement deep learning algorithms for machine learning systems and integrate them into your product offerings, including
search, image recognition, and language processing. Additionally, you’ll learn how
to analyze and improve the performance of deep learning models. This can be done by
comparing algorithms against benchmarks, along with machine intelligence, to learn
from the information and determine ideal behaviors within a specific context.
After finishing the book, you will be familiar with machine learning techniques, in particular the use of TensorFlow for deep learning, and will be ready to apply your knowledge to research or commercial projects.
Table of Contents (11 chapters)
Preface
 Free Chapter
Free Chapter
Getting Started with Deep Learning
First Look at TensorFlow
Using TensorFlow on a Feed-Forward Neural Network
TensorFlow on a Convolutional Neural Network
Optimizing TensorFlow Autoencoders
Recurrent Neural Networks
GPU Computing
Advanced TensorFlow Programming
Advanced Multimedia Programming with TensorFlow