-
Book Overview & Buying

-
Table Of Contents

Hands-On Computer Vision with Detectron2
By :
Hands-On Computer Vision with Detectron2
By:
Overview of this book
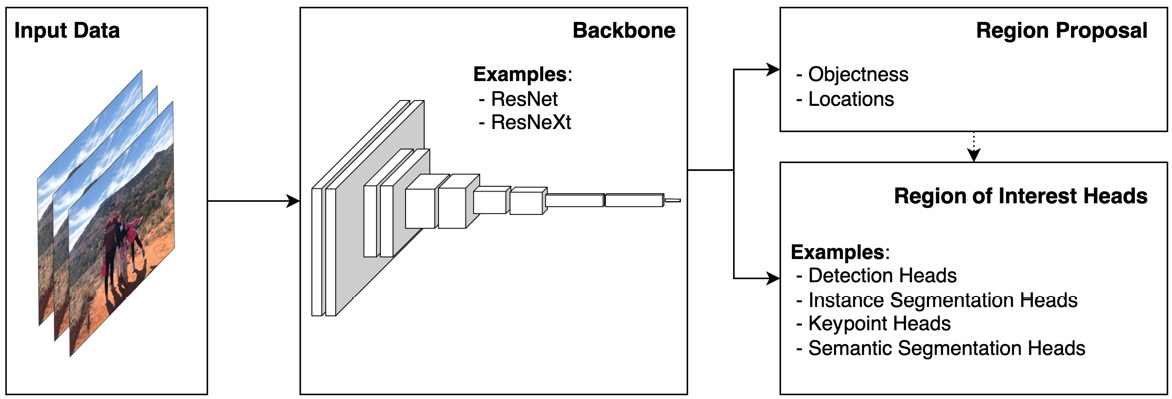
Computer vision is a crucial component of many modern businesses, including automobiles, robotics, and manufacturing, and its market is growing rapidly. This book helps you explore Detectron2, Facebook's next-gen library providing cutting-edge detection and segmentation algorithms. It’s used in research and practical projects at Facebook to support computer vision tasks, and its models can be exported to TorchScript or ONNX for deployment.
The book provides you with step-by-step guidance on using existing models in Detectron2 for computer vision tasks (object detection, instance segmentation, key-point detection, semantic detection, and panoptic segmentation). You’ll get to grips with the theories and visualizations of Detectron2’s architecture and learn how each module in Detectron2 works. As you advance, you’ll build your practical skills by working on two real-life projects (preparing data, training models, fine-tuning models, and deployments) for object detection and instance segmentation tasks using Detectron2. Finally, you’ll deploy Detectron2 models into production and develop Detectron2 applications for mobile devices.
By the end of this deep learning book, you’ll have gained sound theoretical knowledge and useful hands-on skills to help you solve advanced computer vision tasks using Detectron2.
Table of Contents (20 chapters)
Preface

Part 1: Introduction to Detectron2
 Free Chapter
Free Chapter
Chapter 1: An Introduction to Detectron2 and Computer Vision Tasks
Chapter 2: Developing Computer Vision Applications Using Existing Detectron2 Models
Part 2: Developing Custom Object Detection Models
Chapter 3: Data Preparation for Object Detection Applications
Chapter 4: The Architecture of the Object Detection Model in Detectron2
Chapter 5: Training Custom Object Detection Models
Chapter 6: Inspecting Training Results and Fine-Tuning Detectron2’s Solvers
Chapter 7: Fine-Tuning Object Detection Models
Chapter 8: Image Data Augmentation Techniques
Chapter 9: Applying Train-Time and Test-Time Image Augmentations
Part 3: Developing a Custom Detectron2 Model for Instance Segmentation Tasks
Chapter 10: Training Instance Segmentation Models
Chapter 11: Fine-Tuning Instance Segmentation Models
Part 4: Deploying Detectron2 Models into Production
Chapter 12: Deploying Detectron2 Models into Server Environments
Chapter 13: Deploying Detectron2 Models into Browsers and Mobile Environments
Index