

Exploring SageMaker’s managed training stack
Amazon SageMaker provides a set of capabilities and integration points with other AWS services to configure, run, and monitor ML training jobs. With SageMaker managed training, developers can do the following:
- Choose from a variety of built-in algorithms and containers, as well as BYO models
- Choose from a wide range of compute instances, depending on the model requirements
- Debug and profile their training process in near-real-time using SageMaker Debugger
- Run bias detection and model explainability jobs
- Run incremental training jobs, resume from checkpoints, and use spot instances
Spot instances
Amazon EC2 Spot Instances provides customers with access to unused compute capacity at a lower price point (up to 90%). Spot instances will be released when someone else claims them, which results in workload interruption.
- Run model tuning jobs to search for optimal combinations of model hyperparameters
- Organize training jobs in a searchable catalog of experiments
Amazon SageMaker provides the following capabilities out of the box:
- Provisioning, bootstrapping, and tearing down training nodes
- Capturing training job logs and metrics
In this section, we will go over all the stages of a SageMaker training job and the components involved. Please refer to the following diagram for a visual narrative that provides a step-by-step guide on creating, managing, and monitoring your first SageMaker training job. We will address the advanced features of SageMaker’s managed training stack in Part 2 of this book:
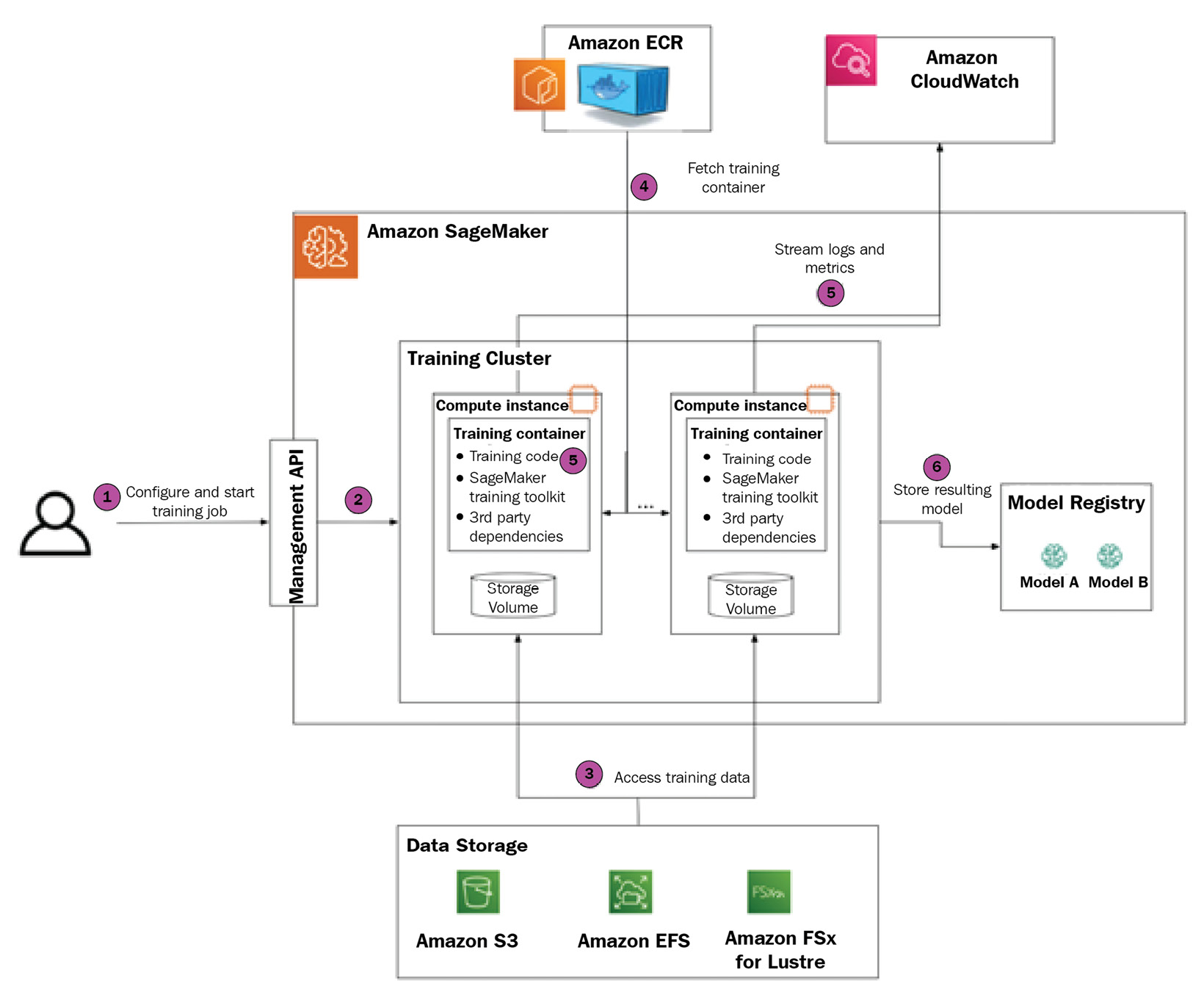
Figure 1.2 – Amazon SageMaker training stack
Let’s walk through each step in turn.
We will also provide code snippets to illustrate how to perform a SageMaker training job configuration using the SageMaker Python SDK (https://sagemaker.readthedocs.io/en/stable/).
Step 1 – configuring and creating a training job
You can instantiate a SageMaker training job via an API call.
SageMaker defines several mandatory configuration parameters that need to be supplied by you. They are listed as follows.
Choosing an algorithm to train
Amazon SageMaker supports several types of ML algorithms:
- Built-in algorithms are available out of the box for all SageMaker users. At the time of writing, 18 built-in algorithms cover a variety of use cases, including DL algorithms for computer vision and NLP tasks. The user is only responsible for providing algorithm hyperparameters.
- Custom algorithms are developed by the user. AWS is not responsible for training logic in this case. The training script will be executed inside a Docker container. Developers can choose to use AWS-authored Docker images with pre-installed software dependencies or can use BYO Docker images.
- Marketplace algorithms are developed by third-party vendors and available via the AWS Marketplace. Similar to built-in algorithms, they typically offer a fully managed experience where the user is responsible for providing algorithm hyperparameters. Unlike built-in algorithms, which are free to use, the user usually pays a fee for using marketplace algorithms.
Defining an IAM role
Amazon SageMaker relies on the Amazon IAM service and, specifically, IAM roles to define which AWS resources and services can be accessed from the training job. That’s why, whenever scheduling a SageMaker training job, you need to provide an IAM role, which will be then assigned to training nodes.
Defining a training cluster
Another set of required parameters defines the hardware configuration of the training cluster, which includes several compute instances, types of instances, and instance storage.
It’s recommended that you carefully choose your instance type based on specific requirements. At a minimum, ML engineers need to understand which compute device is used at training time. For example, in most cases for DL models, you will likely need to use a GPU-based instance, while many classical ML algorithms (such as linear regression or Random Forest) are CPU-bound.
ML engineers also need to consider how many instances to provision. When provisioning multiple nodes, you need to make sure that your algorithm and training script support distributed training.
Built-in algorithms usually provide recommended instance types and counts in their public documentation. They also define whether distributed training is supported or not. In the latter case, you should configure a single-node training cluster.
Defining training data
Amazon SageMaker supports several storage solutions for training data:
- Amazon S3: This is a low-cost, highly durable, and highly available object storage. This is considered a default choice for storing training datasets. Amazon S3 supports two types of input mode (also defined in training job configuration) for training datasets:
- Amazon EFS: This is an elastic filesystem service. If it’s used to persist training data, Amazon SageMaker will automatically mount the training instance to a shared filesystem.
- Amazon FSx for Luster: This is a high-performant shared filesystem optimized for the lowest latency and highest throughput.
Before training can begin, you need to make sure that data is persisted in one of these solutions, and then provide the location of the datasets.
Please note that you can provide the locations of several datasets (for example, training, test, and evaluation sets) in your training job.
Picking your algorithm hyperparameters
While it’s not strictly mandatory, in most cases, you will need to define certain hyperparameters of the algorithm. Examples of such hyperparameters include the batch size, number of training epochs, and learning rate.
At training time, these hyperparameters will be passed to the training script as command-line arguments. In the case of custom algorithms, developers are responsible for parsing and setting hyperparameters in the training script.
Defining the training metrics
Metrics are another optional but important parameter. SageMaker provides out-of-the-box integration with Amazon CloudWatch to stream training logs and metrics. In the case of logs, SageMaker will automatically stream stdout and stderr from the training container to CloudWatch.
stdout and stderr
stdout and stderr are standard data streams in Linux and Unix-like OSs. Every time you run a Linux command, these data streams are established automatically. Normal command output is sent to stdout; any error messages are sent to stderr.
In the case of metrics, the user needs to define the regex pattern for each metric first. At training time, the SageMaker utility running on the training instance will monitor stdout and stderr for the regex pattern match, then extract the value of the metric and submit the metric name and value to CloudWatch. As a result, developers can monitor training processes in CloudWatch in near-real time.
Some common examples of training metrics include loss value and accuracy measures.
Configuring a SageMaker training job for image classification
In the following Python code sample, we will demonstrate how to configure a simple training job for a built-in image classification algorithm (https://docs.aws.amazon.com/sagemaker/latest/dg/image-classification.html):
- Begin with your initial imports:
import sagemaker from sagemaker import get_execution_role
- The
get_execution_role()method allows you to get the current IAM role. This role will be used to call the SageMaker APIs, whereassagemaker.Session()stores the context of the interaction with SageMaker and other AWS services such as S3:role = get_execution_role() sess = sagemaker.Session()
- The
.image_uris.retrieve()method allows you to identify the correct container with the built-in image classification algorithm. Note that if you choose to use custom containers, you will need to specify a URI for your specific training container:training_image = sagemaker.image_uris.retrieve('image-classification', sess.boto_region_name) - Define the number of instances in the training cluster. Since image classification supports distributed training, we can allocate more than one instance to the training cluster to speed up training:
num_instances = 2
- The image classification algorithm requires GPU-based instances, so we will choose to use a SageMaker P2 instance type:
instance_type = "ml.p2.xlarge"
- Next, we must define the location of training and validation datasets. Note that the image classification algorithm supports several data formats. In this case, we choose to use the JPG file format, which also requires
.lstfiles to list all the available images:data_channels = { 'train': f"s3://{sess.default_bucket()}/data/train", 'validation': f"s3://{sess.default_bucket()}/data/validation", 'train_lst': f"s3://{sess.default_bucket()}/data/train.lst", 'vadidation_lst': f"s3://{sess.default_bucket()}/data/validation.lst", } - Configure the training hyperparameters:
hyperparameters=dict( use_pretrained_model=1, image_shape='3,224,224', num_classes=10, num_training_samples=40000, # TODO: update it learning_rate=0.001, mini_batch_size= 8 )
- Configure the
Estimatorobject, which encapsulates training job configuration:image_classifier = sagemaker.estimator.Estimator( training_image, role, train_instance_count= num_instances, train_instance_type= instance_type, sagemaker_session=sess, hyperparameters=hyperparameters, )
- The
fit()method submits the training job to the SageMaker API. If there are no issues, you should observe a new training job instance in your AWS Console. You can do so by going to Amazon SageMaker | Training | Training Jobs:image_classifier.fit(inputs=data_channels, job_name="sample-train")
Next, we’ll provision the training cluster.
Step 2 – provisioning the SageMaker training cluster
Once you submit a request for the training job, SageMaker automatically does the following:
- Allocates the requested number of training nodes
- Allocates the Amazon EBS volumes and mounts them on the training nodes
- Assigns an IAM role to each node
- Bootstraps various utilities (such as Docker, SageMaker toolkit libraries, and so on)
- Defines the training configuration (hyperparameters, input data configuration, and so on) as an environment variable
Next up is the training data.
Step 3 – SageMaker accesses the training data
When your training cluster is ready, SageMaker establishes access to training data for compute instances. The exact mechanism to access training data depends on your storage solution:
- If data is stored in S3 and the input mode is File, then data will be downloaded to instance EBS volumes. Note that depending on the dataset’s size, it may take minutes to download the data.
- If the data is stored in S3 and the input mode is Pipe, then the data will be streamed from S3 at training time as needed.
- If the data is stored in S3 and the input mode is FastFile, then the training program will access the files as if they are stored on training nodes. However, under the hood, the files will be streamed from S3.
- If the data is stored in EFS or FSx for Luster, then the training nodes will be mounted on the filesystem.
The training continues with deploying the container.
Step 4 – SageMaker deploys the training container
SageMaker automatically pulls the training images from the ECR repository. Note that built-in algorithms abstract the underlying training images so that users don’t have to define the container image, just the algorithm to be used.
Step 5 – SageMaker starts and monitors the training job
To start the training job, SageMaker issues the following command on all training nodes:
docker run [TrainingImage] train
If the training cluster has instances with GPU devices, then nvidia-docker will be used.
Once the training script has started, SageMaker does the following:
- Captures
stdout/stderrand sends it to CloudWatch logs. - Runs a regex pattern match for metrics and sends the metric values to CloudWatch.
- Monitors for a
SIGTERMsignal from the SageMaker API (for example, if the user decides to stop the training job earlier). - Monitors if an early stopping condition occurs and issues
SIGTERMwhen this happens. - Monitors for the exit code of the training script. In the case of a non-zero exit code, SageMaker will mark the training job as “failed.”
Step 6 – SageMaker persists the training artifacts
Regardless of whether the training job fails or succeeds, SageMaker stores artifacts in the following locations:
- The
/opt/ml/outputdirectory, which can be used to persist any training artifacts after the job is completed. - The
/opt/ml/modeldirectory, the content of which will be compressed into.tarformat and stored in the SageMaker model registry.
Once you have your first model trained to solve a particular business problem, the next step is to use your model (in ML parlance, perform inference). In the next few sections, we will learn what capabilities SageMaker provides to run ML inference workloads for various use cases.