

A root filesystem consists of a directory and file hierarchy. In this file hierarchy, various filesystems can be mounted, revealing the content of a specific storage device. The mounting is done using the mount command, and after the operation is done, the mount point is populated with the content available on the storage device. The reverse operation is called umount and is used to empty the mount point of its content.
A root filesytem is available in the root hierarchy, also known as /. It is the first available filesystem and also the one on which the mount command is not used, since it is mounted directly by the kernel through the root= argument. The following are the multiple options to load the root filesystem:
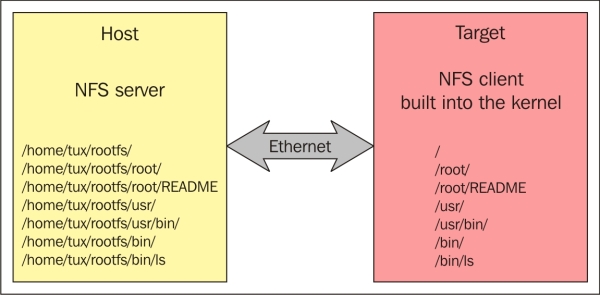
Besides the options that require interaction with a board's internal memory or storage devices, one of the most used methods to load the root filesystem is represented by the NFS option, which implies that the root filesystem is available on your local machine and is exported over the network on your target. This option offers the following advantages:
- The size of the root filesystem will not be an issue due to the fact that the storage space on the development machine is much larger than the one available on the target
- The update process is much easier and can be done without rebooting
- Having access to an over the network storage is the best solution for devices with small even inexistent internal or external storage devices
For the client side available on the target, the Linux kernel needs to be configured accordingly to make sure that the NFS support is enabled, and also that an IP address will be available at boot time. This configurations are CONFIG_NFS_FS=y, CONFIG_IP_PNP=y, and CONFIG_ROOT_NFS=y. The kernel also needs to be configured with the root=/dev/nfs parameter, the IP address for the target, and the NFS server nfsroot=192.168.1.110:/nfs/rootfs information. Here is an example of the communication between the two components:
There is also the possibility of having a root filesystem integrated inside the kernel image, that is, a minimal root filesytem whose purpose is to start the full featured root filesystem. This root filesystem is called initramfs. This type of filesystem is very helpful for people interested in fast booting options of smaller root filesystems that only contain a number of useful features and need to be started earlier. It is useful for the fast loading of the system at boot time, but also as an intermediate step before starting the real root filesystem available on one of the available storage locations. The root filesystem is first started after the kernel booting process, so it makes sense for it to be available alongside the Linux kernel, as it resides near the kernel on the RAM memory. The following image explains this:

To create initramfs, configurations need to be made available. This happens by defining either the path to the root filesystem directory, the path to a cpio archive, or even a text file describing the content of the initramfs inside the CONFIG_INITRAMFS_SOURCE. When the kernel build starts, the content of CONFIG_INITRAMFS_SOURCE will be read and the root filesystem will be integrated inside the kernel image.
The initial RAM disk or initrd is another mechanism of mounting an early root filesystem. It also needs the support enabled inside the Linux kernel and is loaded as a component of the kernel. It contains a small set of executables and directories and represents a transient stage to the full featured root filesystem. It only represents the final stage for embedded devices that do not have a storage device capable of fitting a bigger root filesystem.
Using initrd is not as simple as initramfs. In this case, an archive needs to be copied in a similar manner to the one used for the kernel image, and the bootloader needs to pass its location and size to the kernel to make sure that it has started. Therefore, in this case, the bootloader also requires the support of initrd. The central point of the initrd is constituted by the linuxrc file, which is the first script started and is usually used for the purpose of offering access to the final stage of the system boot, that is, the real root filesytem. After linuxrc finishes the execution, the kernel unmounts it and continues with the real root filesystem.
No matter what their provenience is, most of the available root filesystems have the same organization of directories, as defined by the Filesystem Hierarchy Standard (FHS), as it is commonly called. This organization is of great help to both developers and users because it not only mentions a directory hierarchy, but also the purpose and content of the directories The most notable ones are:
/bin: This refers to the location of most programs/sbin: This refers to the location of system programs/boot: This refers to the location for boot options, such as thekernel image,kernel config,initrd,system maps, and other information/home: This refers to the user home directory/root: This refers to the location of the root user's home location/usr: This refers to user-specific programs and libraries, and mimics parts of the content of the root filesystem/lib: This refers to the location of libraries/etc: This refers to the system-wide configurations/dev: This refers to the location of device files/media: This refers to the location of mount points of removable devices/mnt: This refers to the mount location point of static media/proc: This refers to the mounting point of theprocvirtual filesystem/sys: This refers to the mounting point of thesysfsvirtual filesystem/tmp: This refers to the location temporary files/var: This refers to data files, such as logging data, administrative information, or the location of transient data
The FHS changes over time, but not very much. Most of the previously mentioned directories remain the same for various reasons - the simplest one being the fact that they need to ensure backward compatibility.
The root filesystems are started by the kernel, and it is the last step done by the kernel before it ends the boot phase. Here is the exact code to do this:
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
pr_err("Failed to execute %s (error %d). Attempting defaults...\n",execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel." "See Linux Documentation/init.txt for guidance.");In this code, it can easily be identified that there are a number of locations used for searching the init process that needs to be started before exiting from the Linux kernel boot execution. The run_init_process() function is a wrapper around the execve() function that will not have a return value if no errors are encountered in the call procedure. The called program overwrites the memory space of the executing process, replacing the calling thread and inheriting its PID.
|
Runlevel value |
Runlevel purpose |
|---|---|
|
|
It refers to the shutdown and power down command for the whole system |
|
|
It is a single-user administrative mode with a standard login access |
|
|
It is multiuser without a TCP/IP connection |
|
|
It refers to a general purpose multiuser |
|
|
It is defined by the system's owner |
|
|
It refers to graphical interface and TCP/IP connection multiuser systems |
|
|
It refers to a system reboot |
|
|
It is a single user mode that offers access to a minimal root shell |
Each runlevel starts and kills a number of services. The services that are started begin with S, and the ones that a killed begin with K. Each service is, in fact, a shell script that defines the behaviour of the provides that it defines.
When the preceding inittab file is parsed by the init, the first script that is executed is the si::sysinit:/etc/init.d/rcS line, identified through the sysinit tag. Then, runlevel 5 is entered and the processing of instructions continues until the last level, until a shell is finally spawned using /sbin/getty symlink. More information on either init or inittab can be found by running man init or man inittab in the console.
One of the most important challenges for the Linux system is the access allowed to applications to various hardware devices. Notions, such as virtual memory, kernel space, and user space, do not help in simplifying things, but add another layer of complexity to this information.
A device driver has the sole purpose of isolating hardware devices and kernel data structures from user space applications. A user does not need to know that to write data to a hard disk, he or she will be required to use sectors of various sizes. The user only opens a file to write inside it and close when finished. The device driver is the one that does all the underlying work, such as isolating complexities.
- Block devices: These are composed of fixed size blocks that are usually used when interacting with hard disks, SD cards, USB sticks, and so on
- Character devices: These are streams of characters that do not have a size, beginning, or end; they are mostly not in the form of block devices, such as terminals, serial ports, sound card and so on
Each device has a structure that offers information about it:
The mknod utility that creates the device node uses a triplet of information, such as mknod /dev/testdev c 234 0. After the command is executed, a new /dev/testdev file appears. It should bind itself to a device driver that is already installed and has already defined its properties. If an open command is issued, the kernel looks for the device driver that registered with the same major number as the device node. The minor number is used for handling multiple devices, or a family of devices, with the same device driver. It is passed to the device driver so that it can use it. There is no standard way to use the minor, but usually, it defines a specific device from a family of the devices that share the same major number.
devfs: This refers to a device manager that is devised as a filesystem and is also accessible on a kernel space and user space.devtmpfs: This refers to a virtual filesystem that has been available since the 2.6.32 kernel version release, and is an improvement todevfsthat is used for boot time optimizations. It only creates device nodes for hardware available on a local system.udev: This refers to a daemon used on servers and desktop Linux systems. More information on this can be referred to by accesing https://www.kernel.org/pub/linux/utils/kernel/hotplug/udev/udev.html. The Yocto Project also uses it as the default device manager.mdev: This offers a simpler solution thenudev; it is, in fact, a derivation of udev.
Since system objects are also represented as files, it simplifies the method of interaction with them for applications. This would not been possible without the use of device nodes, that are actually files in which normal file interaction functions can be applied, such as open(), read(), write(), and close().
The root filesystem can be deployed under a very broad form of the filesystem type, and each one does a particular task better than the rest. If some filesystems are optimized for performance, others are better at saving space or even recovering data. Some of the most commonly used and interesting ones will be presented here.
The logical division for a physical device, such as a hard disk or SD card, is called a partition. A physical device can have one or more partitions that cover its available storage space. It can be viewed as a logical disk that has a filesystem available for the user's purposes. The management of partitions in Linux is done using the fdisk utility. It can be used to create, list, destroy, and other general interactions, with more than 100 partition types. To be more precise, 128 partition types are available on my Ubuntu 14.04 development machine.
One of the most used and well known filesystem partition formats is ext2. Also called second extended filesystem, it was introduced in 1993 by Rémy Card, a French software developer. It was used as the default filesystem for a large number of Linux distributions, such as Debian and Red Hat Linux, until it was replaced by its younger brothers, ext3 and ext4. It continues to remain the choice of many embedded Linux distributions and flash storage devices.
The ext2 filesystem splits data into blocks, and the blocks are arranged into block groups. Each block group maintains a copy of a superblock and the descriptor table for that block group. Superblocks are to store configuration information, and hold the information required by the booting process, although there are available multiple copies of it; usually, the first copy that is situated in the first block of the file system is the one used. All the data for a file is usually kept in a single block so that searches can be made faster. Each block group, besides the data it contains, has information about the superblock, descriptor table for the block group, inode bitmap and table information, and the block bitmap. The superblock is the one that holds the information important for the booting process. Its first block is used for the booting process. The last notion presented is in the form of inodes, or the index nodes, which represent files and directories by their permission, size, location on disk, and ownership.
There are multiple applications used for interaction with the ext2 filesystem format. One of them is
mke2fs, which is used to create an ext2 filesystem on a mke2fs /deb/sdb1 –L partition (ext2 label partition). The is the e2fsck command, which is used to verify the integrity of the filesystem. If no errors are found, these tools give you information about the partition filesystem configuration, e2fsck /dev/sdb1. This utility is also able to fix some of the errors that appear after improper utilization of the device, but cannot be used in all scenarios.
Ext3 is another powerful and well known filesystem. It replaced ext2 and became one of the most used filesystems on Linux distributions. It is in fact similar to ext2; the difference being that it has the possibility to journalize the information available to it. The ext2 file format can be changed in an ext3 file format using the tune2fs –j /dev/sdb1 command. It is basically seen as an extension for the ext2 filesystem format, one that adds the journaling feature. This happens because it was engineered to be both forward and backward compatible.
Ext4 is the successor of ext3, and was built with the idea of improving the performance and the storage limit in ext3. It is also backward compatible with the ext3 and ext2 filesystems and also adds a number of features:
- Persistent preallocation: This defines the
fallocate()system call that can be used to preallocate space, which is most likely in a contiguous form; it is very useful for databases and streaming of media - Delayed allocation: This is also called allocate-on-flush; it is used to delay the allocation blocks from the moment data from the disk is flushed, to reduce fragmentation and increase performance
- Multi block allocation: This is a side effect of delayed allocation because it allows for data buffering and, at the same time, the allocation of multiple blocks.
- Increase subdirectory limit: This the
ext3has a limit of 32000 subdirectories, theext4does not have this limitation, that is, the number of subdirectories are unlimited - Checksum for journal: This is used to improve reliability
Journalling Flash Filesystem version 2 (JFFS2) is a filesystem designed for the NAND and NOR flash memory. It was included in the Linux mainline kernel in 2001, the same year as the ext3 filesystem, although in different months. It was released in November for the Linux version 2.4.15, and the JFFS2 filesystem was released in September with the 2.4.10 kernel release. Since it's especially used to support flash devices, it takes into consideration certain things, such as the need to work with small files, and the fact that these devices have a wear level associated with them, which solves and reduces them by their design. Although JFFS2 is the standard for flash memory, there are also alternatives that try to replace it, such as LogFS, Yet Another Flash File System (YAFFS), and Unsorted Block Image File System (UBIFS).
Besides the previously mentioned filesystems, there are also some pseudo filesystems available, including proc, sysfs, and tmpfs. In the next section, the first two of them will be described, leaving the last one for you to discover by yourself.
The proc filesystem is a virtual filesystem available from the first version of Linux. It was defined to allow a kernel to offer information to the user about the processes that are run, but over time, it has evolved and is now able to not only offer statistics about processes that are run, but also offer the possibility to adjust various parameters regarding the management of memory, processes, interrupts, and so on.
The proc filesystem has the following structure:
- For each running process, there is an available directory inside
/proc/<pid>.It contains information about opened files, used memory, CPU usage, and other process-specific information. - Information on general devices is available inside
/proc/devices,/proc/interrupts,/proc/ioports, and/proc/iomem. - The kernel command line is available inside
/proc/cmdline. - Files used to change kernel parameters are available inside
/proc/sys. More information is also available insideDocumentation/sysctl.
The sysfs filesystem is used for the representation of physical devices. It is available since the introduction of the 2.6 Linux kernel versions, and offers the possibility of representing physical devices as kernel objects and associate device drivers with corresponding devices. It is very useful for tools, such as udev and other device managers.
BusyBox was developed by Bruce Perens in 1999 with the purpose of integrating available Linux tools in a single executable. It has been used with great success as a replacement for a great number of Linux command line utilities. Due to this, and the fact that it is able to fit inside small embedded Linux distributions, it has gained a lot of popularity in the embedded environment. It provides utilities from file interactions, such as cp, mkdir, touch, ls, and cat, as well as general utilities, such as dmesg, kill, fdisk, mount, umount, and many others.
Not only is it very easy to configure and compile, but it is also very easy to use. The fact that it is very modular and offers a high degree of configuration makes it the perfect choice to use. It may not include all the commands available in a full-blown Linux distribution available on your host PC, but the ones that it does are more than enough. Also, these commands are just simpler versions of the full-blown ones used at implementation level, and are all integrated in one single executable available in /bin/busybox as symbolic links of this executable.
The configuration of the BusyBox package also has a menuconfig option available, similar to the one available for the kernel and U-Boot, that is, make menuconfig. It is used to show a text menu that can be used for faster configuration and configuration searches. For this menu to be available, first the ncurses package needs to be available on the system that calls the make menuconfig command.
It presents the list of the utilities enabled in the configuration stage. To invoke one of the preceding utilities, there are two options. The first option requires the use of the BusyBox binary and the number of utilities called, which are represented as ./busybox ls, while the second option involves the use of the symbolic link already available in directories, such as /bin, /sbin, /usr/bin, and so on.
Now that all the information relating to the root filesystem has been presented to you, it would be good exercise to describe the must-have components of the minimal root filesystem. This would not only help you to understand the rootfs structure and its dependencies better, but also help with requirements needed for boot time and the size optimization of the root filesystem.
From this information, the /lib directory structure is defined. Its minimal form is:
The following symbolic links to ensure backward compatibility and version immunity for the libraries. The linux-gate.so.1 file in the preceding code is a virtual dynamically linked shared object (vDSO), exposed by the kernel at a well established location. The address where it can be found varies from one machine architecture to another.
Having mentioned all of this, the minimal root filesystem seems to have only five directories and eight files. Its minimal size is below 2 MB and around 80 percent of its size is due to the C library package. It is also possible to minimize its size by using the Library Optimizer Tool. You can find more information on this at http://libraryopt.sourceforge.net/.
Moving to the Yocto Project, we can take a look at the core-image-minimal to identify its content and minimal requirements, as defined inside the Yocto Project. The core-image-minimal.bb image is available inside the meta/recipes-core/images directory, and this is how it looks:
Constructing a root filesystem is not an easy task for anyone, but Yocto does it with a bit more success. It starts from the base-files recipe that is used to lay down the directory structure according to the Filesystem Hierarchy Standard (FHS), and, along with it, a number of other recipes are placed. This information is available inside the ./meta/recipes-core/packagegroups/packagegroup-core-boot.bb recipe. As can be seen in the previous example, it also inherits a different kind of class, such as packagegroup.bbclass, which is a requirement for all the package groups available. However, the most important factor is that it clearly defines the packages that constitute packagegroup. In our case, the core boot package group contains packages, such as base-files, base-passwd (which contains the base system master password and group files), udev, busybox, and sysvinit (a System V similar to init).
As can be seen in the previously shown file, the BusyBox package is a core component of the Yocto Project's generated distributions. Although information was available about the fact that BusyBox can offer an init alternative, the default Yocto generated distributions do not use this. Instead, they choose to move to the System V-like init, which is similar to the one available for Debian-based distributions. Nevertheless, a number of shell interaction tools are made available through the BusyBox recipe available inside the meta/recipes-core/busybox location. For users interested in enhancing or removing some of features made available by the busybox package, the same concepts that are available for the Linux kernel configuration are used. The busybox package uses a defconfig file on which a number of configuration fragments are applied. These fragments can add or remove features and, in the end, the final configuration file is obtained. This identifies the final features available inside the root filesystem.
Inside this image, there is also another more generic image definition that is inherited. Here, I am referring to the atmel-demo-image.inc file, and when opened, you can see that it contains the core of all the meta-atmel layer images. Of course, if all the available packages are not enough, a developer could decide to add their own. There has two possibilities in front of a developer: to create a new image, or to add packages to an already available one. The end result is built using the bitbake atmel-xplained-demo-image command. The output is available in various forms, and they are highly dependent on the requirements of the defined machine. At the end of the build procedure, the output will be used to boot the root filesystem on the actual board.