

The first benefit everyone sees when looking at virtualization is the increase in server utilization and the decrease in energy costs. Using virtualization, the workloads available on a server are maximized, which is very different from scenarios where hardware uses only a fraction of the computing power. It can reduce the complexity of interaction with various environments and it also offers an easier-to-use management system. Today, working with a large number of virtual machines is not as complicated as interaction with a few of them because of the scalability most tools offer. Also, the time of deployment has really decreased. In a matter of minutes, you can deconfigure and deploy an operating system template or create a virtual environment for a virtual appliance deploy.
Virtualization is extensive, mainly because it contains a broad range of technologies, and also since large portions of the terms are not well defined. In this chapter, you will be presented with only components related to the Yocto Project and also to a new initiative that I personally am interested in. This initiative tries to make Network Function Virtualization (NFV) and Software-Defined Networking (SDN) a reality and is called Open Platform for NFV (OPNFV). It will be explained here briefly.
I have decided to start with this topic because I believe it is really important that all the research done in this area is starting to get traction with a number of open source initiatives from all sorts of areas and industries. Those two concepts are not new. They have been around for 20 years since they were first described, but the last few years have made possible it for them to resurface as real and very possible implementations. The focus of this section will be on the NFV section since it has received the most amount of attention, and also contains various implementation proposals.
NFV is a network architecture concept used to virtualize entire categories of network node functions into blocks that can be interconnected to create communication services. It is different from known virtualization techniques. It uses Virtual Network Functions (VNF) that can be contained in one or more virtual machines, which execute different processes and software components available on servers, switches, or even a cloud infrastructure. A couple of examples include virtualized load balancers, intrusion detected devices, firewalls, and so on.
The development product cycles in the telecommunication industry were very rigorous and long due to the fact that the various standards and protocols took a long time until adherence and quality meetings. This made it possible for fast moving organizations to become competitors and made them change their approach.
In 2013, an industry specification group published a white paper on software-defined networks and OpenFlow. The group was part of European Telecommunications Standards Institute (ETSI) and was called Network Functions Virtualisation. After this white paper was published, more in-depth research papers were published, explaining things ranging from terminology definitions to various use cases with references to vendors that could consider using NFV implementations.
The ETSI NFV workgroup has appeared useful for the telecommunication industry to create more agile cycles of development and also make it able to respond in time to any demands from dynamic and fast changing environments. SDN and NFV are two complementary concepts that are key enabling technologies in this regard and also contain the main ingredients of the technology that are developed by both telecom and IT industries.
The NFV framework consist of six components:
- NFV Infrastructure (NFVI): It is required to offer support to a variety of use cases and applications. It comprises of the totality of software and hardware components that create the environment for which VNF is deployed. It is a multitenant infrastructure that is responsible for the leveraging of multiple standard virtualization technologies use cases at the same time. It is described in the following NFV Industry Specification Groups (NFV ISG) documents:
- NFV Infrastructure Overview
- NFV Compute
- NFV Hypervisor Domain
- NFV Infrastructure Network Domain
The following image presents a visual graph of various use cases and fields of application for the NFV Infrastructure.

- NFV Management and Orchestration (MANO): It is the component responsible for the decoupling of the compute, networking, and storing components from the software implementation with the help of a virtualization layer. It requires the management of new elements and the orchestration of new dependencies between them, which require certain standards of interoperability and a certain mapping.
- NFV Software Architecture: It is related to the virtualization of the already implemented network functions, such as proprietary hardware appliances. It implies the understanding and transition from a hardware implementation into a software one. The transition is based on various defined patterns that can be used in a process.
- NFV Reliability and Availability: These are real challenges and the work involved in these components started from the definition of various problems, use cases, requirements, and principles, and it has proposed itself to offer the same level of availability as legacy systems. It relates to the reliability component and the documentation only sets the stage for future work. It only identifies various problems and indicates the best practices used in designing resilient NFV systems.
- NFV Performance and Portability: The purpose of NFV, in general, is to transform the way it works with networks of future. For this purpose, it needs to prove itself as wordy solution for industry standards. This section explains how to apply the best practices related to performance and portability in a general VNF deployment.
- NFV Security: Since it is a large component of the industry, it is concerned about and also dependent on the security of networking and cloud computing, which makes it critical for NFV to assure security. The Security Expert Group focuses on those concerns.
An architectural of these components is presented here:
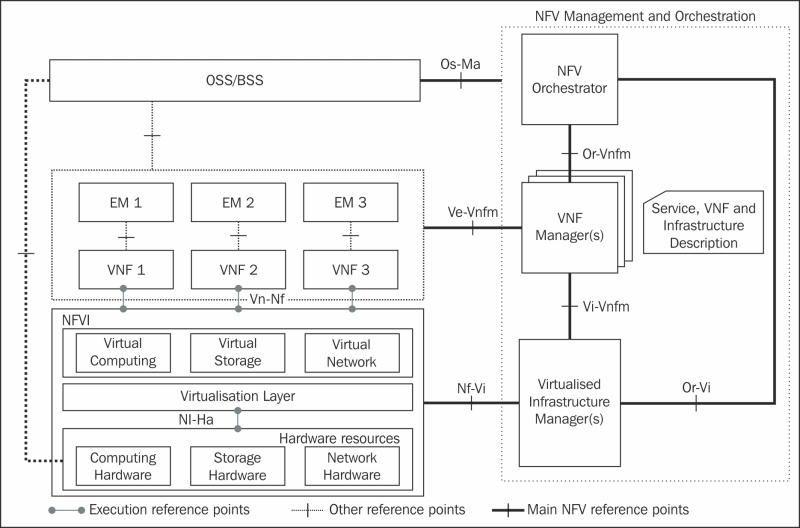
After all the documentation is in place, a number of proof of concepts need to be executed in order to test the limitation of these components and accordingly adjust the theoretical components. They have also appeared to encourage the development of the NFV ecosystem.
Software-Defined Networking (SDN) is an approach to networking that offers the possibility to manage various services using the abstraction of available functionalities to administrators. This is realized by decoupling the system into a control plane and data plane and making decisions based on the network traffic that is sent; this represents the control plane realm, and where the traffic is forwarded is represented by the data plane. Of course, some method of communication between the control and data plane is required, so the OpenFlow mechanism entered into the equation at first; however other components could as well take its place.
The intention of SDN was to offer an architecture that was manageable, cost-effective, adaptable, and dynamic, as well as suitable for the dynamic and high-bandwidth scenarios that are available today. The OpenFlow component was the foundation of the SDN solution. The SDN architecture permitted the following:
- Direct programming: The control plane is directly programmable because it is completely decoupled by the data plane.
- Programmatically configuration: SDN permitted management, configuration, and optimization of resources though programs. These programs could also be written by anyone because they were not dependent on any proprietary components.
- Agility: The abstraction between two components permitted the adjustment of network flows according to the needs of a developer.
- Central management: Logical components could be centered on the control plane, which offered a viewpoint of a network to other applications, engines, and so on.
- Opens standards and vendor neutrality: It is implemented using open standards that have simplified the SDN design and operations because of the number of instructions provided to controllers. This is smaller compared to other scenarios in which multiple vendor-specific protocols and devices should be handled.
The Open Platform for the NFV Project tries to offer an open source reference platform that is carrier-graded and tightly integrated in order to facilitate industry peers to help improve and move the NFV concept forward. Its purpose is to offer consistency, interoperability, and performance among numerous blocks and projects that already exist. This platform will also try to work closely with a variety of open source projects and continuously help with integration, and at the same time, fill development gaps left by any of them.

The project has been leveraging as many open source projects as possible. All the adaptations made to these project can be done in two places. Firstly, they can be made inside the project, if it does not require substantial functionality changes that could cause divergence from its purpose and roadmap. The second option complements the first and is necessary for changes that do not fall in the first category; they should be included somewhere in the OPNFV project's codebase. None of the changes that have been made should be up streamed without proper testing within the development cycle of OPNFV.
The OPNFV board and technical steering committee have a quite large palette of open source projects. They vary from Infrastructure as a Service (IaaS) and hypervisor to the SDN controller and the list continues. This only offers the possibility for a large number of contributors to try some of the skills that maybe did not have the time to work on, or wanted to learn but did not have the opportunity to. Also, a more diversified community offers a broader view of the same subject.
There are a large variety of appliances for the OPNFV project. The virtual network functions are diverse for mobile deployments where mobile gateways (such as Serving Gateway (SGW), Packet Data Network Gateway (PGW), and so on) and related functions (Mobility Management Entity (MME) and gateways), firewalls or application-level gateways and filters (web and e-mail traffic filters) are used to test diagnostic equipment (Service-Level Agreement (SLA) monitoring). These VNF deployments need to be easy to operate, scale, and evolve independently from the type of VNF that is deployed. OPNFV sets out to create a platform that has to support a set of qualities and use-cases as follows:
- A common mechanism is needed for the life-cycle management of VNFs, which include deployment, instantiation, configuration, start and stop, upgrade/downgrade, and final decommissioning
- A consistent mechanism is used to specify and interconnect VNFs, VNFCs, and PNFs; these are independant of the physical network infrastructure, network overlays, and so on, that is, a virtual link
- A common mechanism is used to dynamically instantiate new VNF instances or decommission sufficient ones to meet the current performance, scale, and network bandwidth needs
- A mechanism is used to detect faults and failure in the NFVI, VIM, and other components of an infrastructure as well as recover from these failures
- A mechanism is used to source/sink traffic from/to a physical network function to/from a virtual network function
- NFVI as a Service is used to host different VNF instances from different vendors on the same infrastructure
Note
More information about this project and various implementation components is available at https://www.opnfv.org/. For the definitions of missing terminologies, please consult http://www.etsi.org/deliver/etsi_gs/NFV/001_099/003/01.02.01_60/gs_NFV003v010201p.pdf.
The meta-virtualization layer tries to create a long and medium term production-ready layer specifically for an embedded virtualization. This roles that this has are:
- Simplifying the way collaborative benchmarking and researching is done with tools, such as KVM/LxC virtualization, combined with advance core isolation and other techniques
- Integrating and contributing with projects, such as OpenFlow, OpenvSwitch, LxC, dmtcp, CRIU and others, which can be used with other components, such as OpenStack or Carrier Graded Linux.
The packages that are available in this layer, which I will briefly talk about are as follows:
Having mentioned these components, I will now move on with the explanation of each of these tools. Let's start with the content of the meta-virtualization layer, more exactly with CRIU package, a project that implements Checkpoint/Restore In Userspace for Linux. It can be used to freeze an already running application and checkpoint it to a hard drive as a collection of files. These checkpoints can be used to restore and execute the application from that point. It can be used as part of a number of use cases, as follows:
- Live migration of containers: It is the primary use case for a project. The container is check pointed and the resulting image is moved into another box and restored there, making the whole experience almost unnoticeable by the user.
- Upgrading seamless kernels: The kernel replacement activity can be done without stopping activities. It can be check pointed, replaced by calling kexec, and all the services can be restored afterwards.
- Speeding up slow boot services: It is a service that has a slow boot procedure, can be check pointed after the first start up is finished, and for consecutive starts, can be restored from that point.
- Load balancing of networks: It is a part of the
TCP_REPAIRsocket option and switches the socket in a special state. The socket is actually put into the state expected from it at the end of the operation. For example, ifconnect()is called, the socket will be put in anESTABLISHEDstate as requested without checking for acknowledgment of communication from the other end, so offloading could be at the application level. - Desktop environment suspend/resume: It is based on the fact that the suspend/restore action for a screen session or an
Xapplication is by far faster than the close/open operation. - High performance and computing issues: It can be used for both load balancing of tasks over a cluster and the saving of cluster node states in case a crash occurs. Having a number of snapshots for application doesn't hurt anybody.
- Duplication of processes: It is similar to the remote
fork()operation. - Snapshots for applications: A series of application states can be saved and reversed back if necessary. It can be used both as a redo for the desired state of an application as well as for debugging purposes.
- Save ability in applications that do not have this option: An example of such an application could be games in which after reaching a certain level, the establishment of a checkpoint is the thing you need.
- Migrate a forgotten application onto the screen: If you have forgotten to include an application onto the screen and you are already there, CRIU can help with the migration process.
- Debugging of applications that have hung: For services that are stuck because of
gitand need a quick restart, a copy of the services can be used to restore. A dump process can also be used and through debugging, the cause of the problem can be found. - Application behavior analysis on a different machine: For those applications that could behave differently from one machine to another, a snapshot of the application in question can be used and transferred into the other. Here, the debugging process can also be an option.
- Dry running updates: Before a system or kernel update on a system is done, its services and critical applications could be duplicated onto a virtual machine and after the system update and all the test cases pass, the real update can be done.
- Fault-tolerant systems: It can be used successfully for process duplication on other machines.
Besides these packages, it also offers support for storage on a large variety of filesystems, such as IDE, SCSI or USB disks, FiberChannel, LVM, and iSCSI or NFS, as well as support for virtual networks. It is the building block for other higher-level applications and tools that focus on the virtualization of a node and it does this in a secure way. It also offers the possibility of a remote connection.
The next is Open vSwitch, a production-quality implementation of a multilayer virtual switch. This software component is licensed under Apache 2.0 and is designed to enable massive network automations through various programmatic extensions. The Open vSwitch package, also abbreviated as
OVS, provides a two stack layer for hardware virtualizations and also supports a large number of the standards and protocols available in a computer network, such as sFlow, NetFlow, SPAN, CLI, RSPAN, 802.1ag, LACP, and so on.
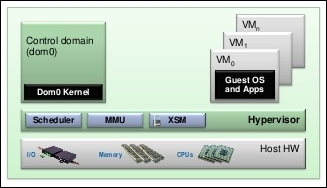
A hypervisor is a piece of software that is concerned with the CPU scheduling and memory management of various domains. It does this from the domain 0 (dom0), which controls all the other unprivileged domains called domU; Xen boots from a bootloader and usually loads into the dom0 host domain, a paravirtualized operating system. A brief look at the Xen project architecture is available here:
Linux Containers (LXC) is the next element available in the meta-virtualization layer. It is a well-known set of tools and libraries that offer virtualization at the operating system level by offering isolated containers on a Linux control host machine. It combines the functionalities of kernel control groups (cgroups) with the support for isolated namespaces to provide an isolated environment. It has received a fair amount of attention mostly due to Docker, which will be briefly mentioned a bit later. Also, it is considered a lightweight alternative to full machine virtualization.
Both of these options, containers and machine virtualization, have a fair amount of advantages and disadvantages. If the first option, containers offer low overheads by sharing certain components, and it may turn out that it does not have a good isolation. Machine virtualization is exactly the opposite of this and offers a great solution to isolation at the cost of a bigger overhead. These two solutions could also be seen as complementary, but this is only my personal view of the two. In reality, each of them has its particular set of advantages and disadvantages that could sometimes be uncomplementary as well.
The last component of the meta-virtualization layer that will be discussed is
Docker, an open source piece of software that tries to automate the method of deploying applications inside Linux containers. It does this by offering an abstraction layer over LXC. Its architecture is better described in this image:
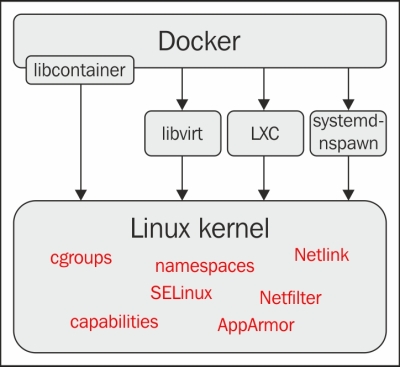
As you can see in the preceding diagram, this software package is able to use the resources of the operating system. Here, I am referring to the functionalities of the Linux kernel and have isolated other applications from the operating system. It can do this either through LXC or other alternatives, such as libvirt and systemd-nspawn, which are seen as indirect implementations. It can also do this directly through the libcontainer library, which has been around since the 0.9 version of Docker.
Docker is a great component if you want to obtain automation for distributed systems, such as large-scale web deployments, service-oriented architectures, continuous deployment systems, database clusters, private PaaS, and so on. More information about its use cases is available at https://www.docker.com/resources/usecases/. Make sure you take a look at this website; interesting information is often here.
After finishing with the meta-virtualization layer, I will move next to the meta-cloud-services layer that contains various elements. I will start with
Simple Protocol for Independent Computing Environments (Spice). This can be translated into a remote-display system for virtualized desktop devices.
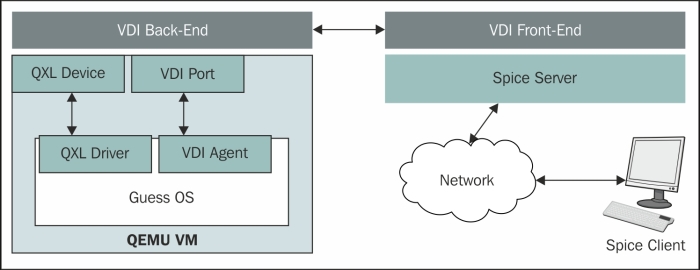
It initially started as a closed source software, and in two years it was decided to make it open source. It then became an open standard to interaction with devices, regardless of whether they are virtualized one not. It is built on a client-server architecture, making it able to deal with both physical and virtualized devices. The interaction between backend and frontend is realized through VD-Interfaces (VDI), and as shown in the following diagram, its current focus is the remote access to QEMU/KVM virtual machines:
Next on the list is oVirt, a virtualization platform that offers a web interface. It is easy to use and helps in the management of virtual machines, virtualized networks, and storages. Its architecture consists of an oVirt Engine and multiple nodes. The engine is the component that comes equipped with a user-friendly interface to manage logical and physical resources. It also runs the virtual machines that could be either oVirt nodes, Fedora, or CentOS hosts. The only downfall of using oVirt is that it only offers support for a limited number of hosts, as follows:
As a tool, it is really powerful. It offers integration with libvirt for
Virtual Desktops and Servers Manager (VDSM) communications with virtual machines and also support for SPICE communication protocols that enable remote desktop sharing. It is a solution that was started and is mainly maintained by Red Hat. It is the base element of their Red Hat Enterprise Virtualization (RHEV), but one thing is interesting and should be watched out for is that Red Hat now is not only a supporter of projects, such as oVirt and Aeolus, but has also been a platinum member of the OpenStack foundation since 2012.
I will move on to a different component now. Here, I am referring to the open source implementation of the Lightweight Directory Access Protocol, simply called OpenLDAP. Although it has a somewhat controverted license called OpenLDAP Public License, which is similar in essence to the BSD license, it is not recorded at opensource.org, making it uncertified by Open Source Initiative (OSI).
This software component comes as a suite of elements, as follows:
There are also a number of additions that should be mentioned, such as ldapc++ and libraries written in C++, JLDAP and the libraries written in Java; LMDB, a memory mapped database library; Fortress, a role-based identity management; SDK, also written in Java; and a JDBC-LDAP Bridge driver that is written in Java and called JDBC-LDAP.
Cyrus SASL is a generic client-server library implementation for Simple Authentication and Security Layer (SASL) authentication. It is a method used for adding authentication support for connection-based protocols. A connection-based protocol adds a command that identifies and authenticates a user to the requested server and if negotiation is required, an additional security layer is added between the protocol and the connection for security purposes. More information about SASL is available in the RFC 2222, available at http://www.ietf.org/rfc/rfc2222.txt.
Qpid is a messaging tool developed by Apache, which understands Advanced Message Queueing Protocol (AMQP) and has support for various languages and platforms. AMQP is an open source protocol designed for high-performance messaging over a network in a reliable fashion. More information about AMQP is available at http://www.amqp.org/specification/1.0/amqp-org-download. Here, you can find more information about the protocol specifications as well as about the project in general.
- Letting the source code open source.
- Making AMQP available for a large variety of computing environments and programming languages.
- Offering the necessary tools to simplify the development process of an application.
- Creating a messaging infrastructure to make sure that other services can integrate well with the AMQP network.
- Creating a messaging product that makes integration with AMQP trivial for any programming language or computing environment. Make sure that you take a look at Qpid Proton at http://qpid.apache.org/proton/overview.html for this.
- The RabbitMQ exchange server
- Gateways for HTTP, Streaming Text Oriented Message Protocol (STOMP) and Message Queue Telemetry Transport (MQTT)
- AMQP client libraries for a variety of programming languages, most notably Java, Erlang, and .Net Framework
- A plugin platform for a number of custom components that also offer a collection of predefined one:
Comparing the two, Qpid and RabbitMQ, it can be concluded that RabbitMQ is better and also that it has a fantastic documentation. This makes it the first choice for the OpenStack Foundation as well as for readers interested in benchmarking information for more than these frameworks. It is also available at http://blog.x-aeon.com/2013/04/10/a-quick-message-queue-benchmark-activemq-rabbitmq-hornetq-qpid-apollo/. One such result is also available in this image for comparison purposes:
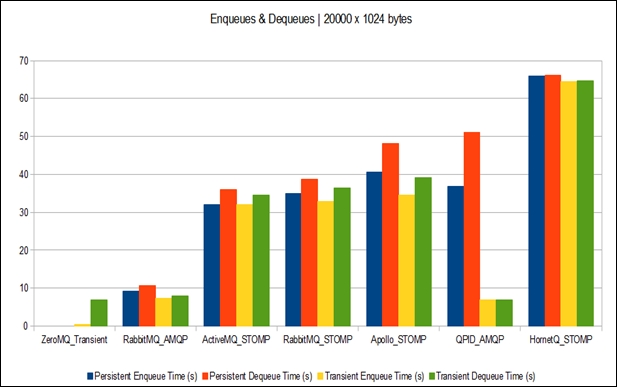
The next element is puppet, an open source configuration management system that allows IT infrastructure to have certain states defined and also enforce these states. By doing this, it offers a great automation system for system administrators. This project is developed by the Puppet Labs and was released under GNU General Public License until version 2.7.0. After this, it moved to the Apache License 2.0 and is now available in two flavors:
- The open source puppet version: It is mostly similar to the preceding tool and is capable of configuration management solutions that permit for definition and automation of states. It is available for both Linux and UNIX as well as Max OS X and Windows.
- The puppet enterprise edition: It is a commercial version that goes beyond the capabilities of the open source puppet and permits the automation of the configuration and management process.
Note
If you visit http://docs.puppetlabs.com/, you will find more documentation related to Puppet and other Puppet Lab tools.
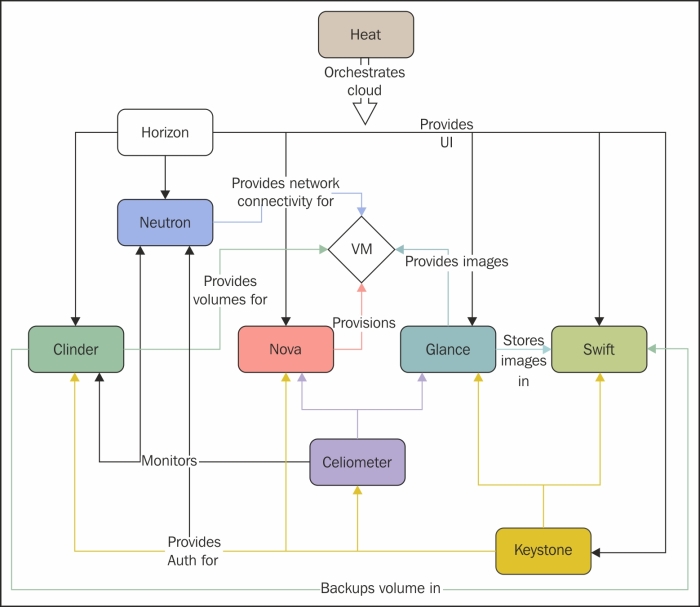
With all this in place, I believe it is time to present the main component of the meta-cloud-services layer, called OpenStack. It is a cloud operating system that is based on controlling a large number of components and together it offers pools of compute, storage, and networking resources. All of them are managed through a dashboard that is, of course, offered by another component and offers administrators control. It offers users the possibility of providing resources from the same web interface. Here is an image depicting the Open Source Cloud operating System, which is actually OpenStack:

- Compute (Nova): It is used for the hosting and management of cloud computing systems. It manages the life cycles of the compute instances of an environment. It is responsible for the spawning, decommissioning, and scheduling of various virtual machines on demand. With regard to hypervisors, KVM is the preferred option but other options such as Xen and VMware are also viable.
- Object Storage (Swift): It is used for storage and data structure retrieval via RESTful and the HTTP API. It is a scalable and fault-tolerant system that permits data replication with objects and files available on multiple disk drives. It is developed mainly by an object storage software company called SwiftStack.
- Block Storage (Cinder): It provides persistent block storage for OpenStack instances. It manages the creation and attach and detach actions for block devices. In a cloud, a user manages its own devices, so a vast majority of storage platforms and scenarios should be supported. For this purpose, it offers a pluggable architecture that facilitates the process.
- Networking (Neutron): It is the component responsible for network-related services, also known as Network Connectivity as a Service. It provides an API for network management and also makes sure that certain limitations are prevented. It also has an architecture based on pluggable modules to ensure that as many networking vendors and technologies as possible are supported.
- Dashboard (Horizon): It provides web-based administrators and user graphical interfaces for interaction with the other resources made available by all the other components. It is also designed keeping extensibility in mind because it is able to interact with other components responsible for monitoring and billing as well as with additional management tools. It also offers the possibility of rebranding according to the needs of commercial vendors.
- Identity Service (Keystone): It is an authentication and authorization service It offers support for multiple forms of authentication and also existing backend directory services such as LDAP. It provides a catalogue for users and the resources they can access.
- Image Service (Glance): It is used for the discovery, storage, registration, and retrieval of images of virtual machines. A number of already stored images can be used as templates. OpenStack also provides an operating system image for testing purposes. Glance is the only module capable of adding, deleting, duplicating, and sharing OpenStack images between various servers and virtual machines. All the other modules interact with the images using the available APIs of Glance.
- Telemetry (Ceilometer): It is a module that provides billing, benchmarking, and statistical results across all current and future components of OpenStack with the help of numerous counters that permit extensibility. This makes it a very scalable module.
- Orchestrator (Heat): It is a service that manages multiple composite cloud applications with the help of various template formats, such as Heat Orchestration Templates (HOT) or AWS CloudFormation. The communication is done both on a CloudFormation compatible Query API and an Open Stack REST API.
- Database (Trove): It provides Cloud Database as service functionalities that are both reliable and scalable. It uses relational and nonrelational database engines.
- Bare Metal Provisioning (Ironic): It is a components that provides virtual machine support instead of bare metal machines support. It started as a fork of the Nova Baremetal driver and grew to become the best solution for a bare-metal hypervisor. It also offers a set of plugins for interaction with various bare-metal hypervisors. It is used by default with PXE and IPMI, but of course, with the help of the available plugins it can offer extended support for various vendor-specific functionalities.
- Multiple Tenant Cloud Messaging (Zaqar): It is, as the name suggests, a multitenant cloud messaging service for the web developers who are interested in Software as a Service (SaaS). It can be used by them to send messages between various components by using a number of communication patterns. However, it can also be used with other components for surfacing events to end users as well as communication in the over-cloud layer. Its former name was Marconi and it also provides the possibility of scalable and secure messaging.
- Elastic Map Reduce (Sahara): It is a module that tries to automate the method of providing the functionalities of Hadoop clusters. It only requires the defines for various fields, such as Hadoop versions, various topology nodes, hardware details, and so on. After this, in a few minutes, a Hadoop cluster is deployed and ready for interaction. It also offers the possibility of various configurations after deployment.
Now, let's move on and see how such a system can be deployed using the functionalities of the Yocto Project. For this activity to start, all the required metadata layers should be put together. Besides the already available Poky repository, other ones are also required and they are defined in the layer index on OpenEmbedded's website because this time, the README file is incomplete:
meta-cloud-servicesmeta-cloud-services/meta-openstack-controller-deploymeta-cloud-services/meta-openstackmeta-cloud-services/meta-openstack-qemumeta-openembedded/meta-oemeta-openembedded/meta-networkingmeta-openembedded/meta-pythonmeta-openembedded/meta-filesystemmeta-openembedded/meta-webservermeta-openembedded/meta-ruby
With the new build directory created and also since most of the work of the build process has already been done with the controller, build directories such as downloads and sstate-cache, can be shared between them. This information should be indicated through DL_DIR and SSTATE_DIR. The difference between the two conf/bblayers.conf files is that the second one for the build-compute build directory replaces meta-cloud-services/meta-openstack-controller-deploy with meta-cloud-services/meta-openstack-compute-deploy.
The last element from the meta-cloud-services layer is the
Tempest integration test suite
for OpenStack. It is represented through a set of tests that are executed on the OpenStack trunk to make sure everything is working as it should. It is very useful for any OpenStack deployments.