

Having considered AWS networking, we will now explore OpenStack's approach to networking and look at how its services are configured.
OpenStack is deployed in a data center on multiple controllers. These controllers contain all the OpenStack services, and they can be installed on either virtual machines, bare metal (physical) servers, or containers. The OpenStack controllers should host all the OpenStack services in a highly available and redundant fashion when they are deployed in production.
Different OpenStack vendors provide different installers to install OpenStack. Some examples of installers from the most prominent OpenStack distributions are RedHat Director (based on OpenStack TripleO), Mirantis Fuel, HPs HPE installer (based on Ansible), and Juju for Canonical, which all install OpenStack controllers and are used to scale out compute nodes on the OpenStack cloud acting as an OpenStack workflow management tool.
A breakdown of the core OpenStack services that are installed on an OpenStack controller are as follows:
Keystone is the identity service for OpenStack that allows user access, which issues tokens, and can be integrated with LDAP or Active directory.
Heat is the orchestration provisioning tool for OpenStack infrastructure.
Glance is the image service for OpenStack that stores all image templates for virtual machines or bare metal servers.
Cinder is the block storage service for OpenStack that allows centralized storage volumes to be provisioned and attached to vms or bare metal servers that can then be mounted.
Nova is the compute service for OpenStack used to provision vms and uses different scheduling algorithms to work out where to place virtual machines on available compute.
Horizon is the OpenStack dashboard that users connect to view the status of vms or bare metal servers that are running in a tenant network.
Galera is the database used to store all OpenStack data in the Nova (compute) and neutron (networking) databases holding vm, port, and subnet information.
Swift is the object storage service for OpenStack and can be used as a redundant storage backend that stores replicated copies of objects on multiple servers. Swift is not like traditional block or file-based storage; objects can be any unstructured data.
Ironic is the bare metal provisioning service for OpenStack. Originally, a fork of part of the Nova codebase, it allows provisioning of images on to bare metal servers and uses IPMI and ILO or DRAC interfaces to manage physical hardware.
Neutron is the networking service for OpenStack and contains ML2 and L3 agents and allows configuration of network subnets and routers.
In terms of neutron networking services, neutron architecture is very similar in constructs to AWS.
Note
Useful links covering OpenStack services can be found at:
http://docs.openstack.org/admin-guide/common/get-started-openstack-services.html.
A Project, often referred to in OpenStack as a tenant, gives an isolated view of everything that a team has provisioned in an OpenStack cloud. Different user accounts can then be set up against a Project (tenant) using the keystone identity service, which can be integrated with Lightweight Directory Access Protocol (LDAP) or Active Directory to support customizable permission models.
OpenStack neutron performs all the networking functions in OpenStack.
The following network functions are provided by the neutron project in an OpenStack cloud:
Creating instances (virtual machines) mapped to networks
Assigning IP addresses using its in-built DHCP service
DNS entries are applied to instances from named servers
The assignment of private and Floating IP addresses
Creating or associating network subnets
Creating routers
Applying security groups
OpenStack is set up into its Modular Layer 2 (ML2) and Layer 3 (L3) agents that are configured on the OpenStack controllers. OpenStack's ML2 plugin allows OpenStack to integrate with switch vendors that use either Open vSwitch or Linux Bridge and acts as an agnostic plugin to switch vendors, so vendors can create plugins, to make their switches OpenStack compatible. The ML2 agent runs on the hypervisor communicating over Remote Procedure Call (RPC) to the compute host server.
OpenStack compute hosts are typically deployed using a hypervisor that uses Open vSwitch. Most OpenStack vendor distributions use the KVM hypervisor by default in their reference architectures, so this is deployed and configured on each compute host by the chosen OpenStack installer.
Compute hosts in OpenStack are connected to the access layer of the STP 3-tier model, or in modern networks connected to the Leaf switches, with VLANs connected to each individual OpenStack compute host. Tenant networks are then used to provide isolation between tenants and use VXLAN and GRE tunneling to connect the layer 2 network.
Open vSwitch runs in kernel space on the KVM hypervisor and looks after firewall rules by using OpenStack security groups that pushes down flow data via OVSDB from the switches. The neutron L3 agent allows OpenStack to route between tenant networks and uses neutron routers, which are deployed within the tenant network to accomplish this, without a neutron router networks are isolated from each other and everything else.
When setting up simple networking using neutron in a Project (tenant) network, two different networks, an internal network, and an external network will be configured. The internal network will be used for east-west traffic between instances. This is created as shown in the following horizon dashboard with an appropriate Network Name:
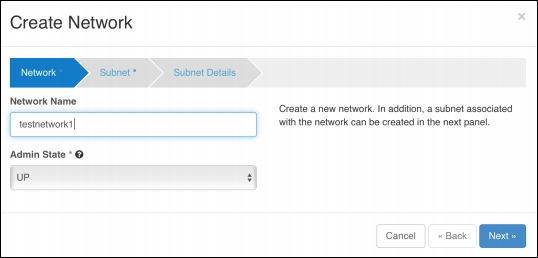
The Subnet Name and subnet range are then specified in the Subnet section, as shown in the following screenshot:

Finally, DHCP is enabled on the network, and any named Allocation Pools (specifies only a range of addresses that can be used in a subnet) are optionally configured alongside any named DNS Name Servers, as shown below:

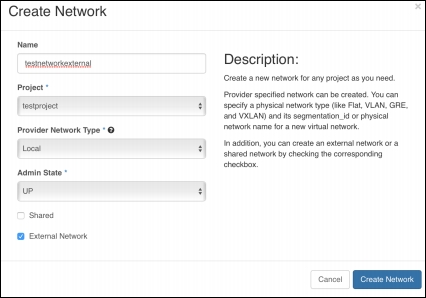
An external network will also need to be created to make the internal network accessible from outside of OpenStack, when external networks are created by an administrative user, the set External Network checkbox needs to be selected, as shown in the next screenshot:
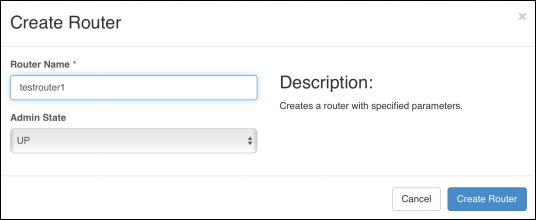
A router is then created in OpenStack to route packets to the network, as shown below:
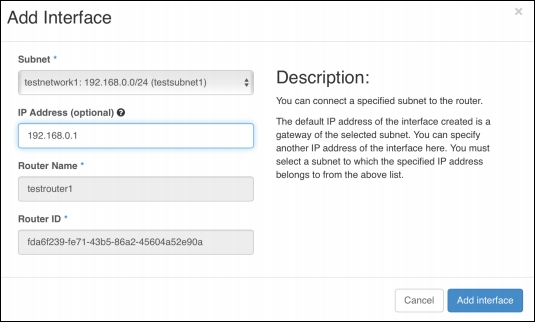
The created router will then need to be associated with the networks; this is achieved by adding an interface on the router for the private network, as illustrated in the following screenshot:
The External Network that was created then needs to be set as the router's gateway, as per the following screenshot:
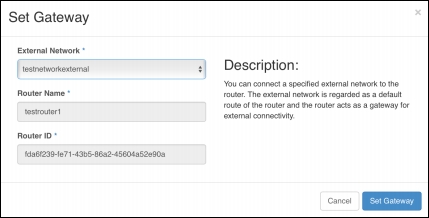
This then completes the network setup; the final configuration for the internal and external network is displayed below, which shows one router connected to an internal and external network:

In OpenStack, instances are provisioned onto the internal private network by selecting the private network NIC when deploying instances. OpenStack has the convention of assigning pools of public IPs (floating IP) addresses from an external network for instances that need to be externally routable outside of OpenStack.
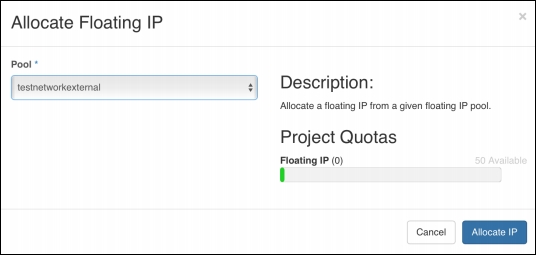
To set up a set of floating IP addresses, an OpenStack administrator will set up an allocation pool using the external network from an external network, as shown in the following screenshot:
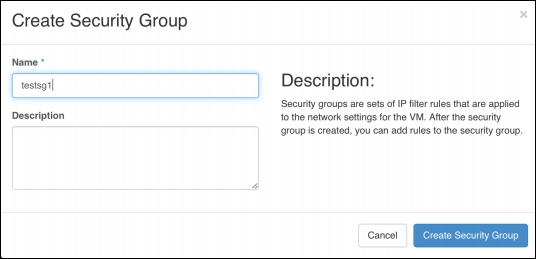
OpenStack like AWS, uses security groups to set up firewall rules between instances. Unlike AWS, OpenStack supports both ingress and egress ACL rules, whereas AWS allows all outbound communication, OpenStack can deal with both ingress and egress rules. Bespoke security groups are created to group ACL rules as shown below
Ingress and Rules can then be created against a security group. SSH access is configured as an ACL rule against the parent security group, which is pushed down to Open VSwitch into kernel space on each hypervisor, as seen in the next screenshot:

Once the Project (tenant) has two networks, one internal and one external, and an appropriate security group has been configured, instances are ready to be launched on the private network.
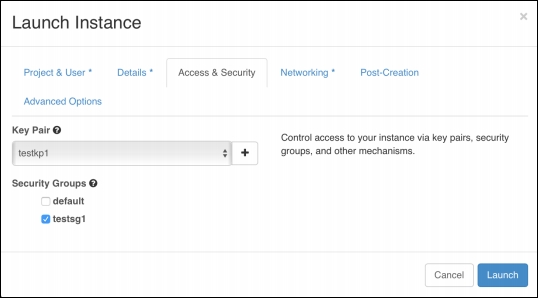
An instance is launched by selecting Launch Instance in horizon and setting the following parameters:
Availability Zone
Instance Name
Flavor (CPU, RAM, and disk space)
Image Name (base operating system)

The private network is then selected as the NIC for the instance under the Networking tab:
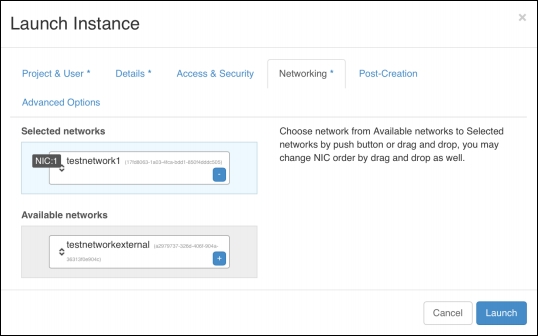
This will mean that when the instance is launched, it will use OpenStack's internal DHCP service to pick an available IP address from the allocated subnet range.
A security group should also be selected to govern the ACL rules for the instance; in this instance, the testsg1 security group is selected as shown in the following screenshot:
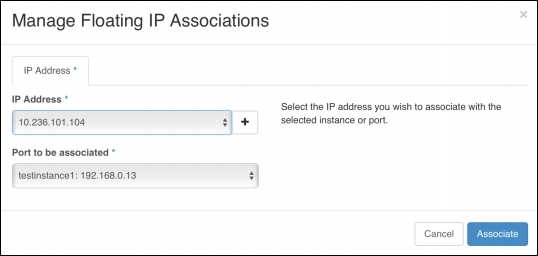
Once the instance has been provisioned, a floating IP address can be associated from the external network:

A floating IP address from the external network floating IP address pool is then selected and associated with the instance:
The floating IP addresses NATs OpenStack instances that are deployed on the internal public IP address to the external network's floating IP address, which will allow the instance to be accessible from outside of OpenStack.
OpenStack like AWS, as seen on instance creation, also utilizes regions and availability zones. Compute hosts in OpenStack (hypervisors) can be assigned to different availability zones.
An availability zone in OpenStack is just a virtual separation of compute resources. In OpenStack, an availability zone can be further segmented into host aggregates. It is important to note that a compute host can be assigned to only one availability zone, but can be a part of multiple host aggregates in that same availability zone.
Nova uses a concept named nova scheduler rules, which dictates the placement of instances on compute hosts at provisioning time. A simple example of a nova scheduler rule is the AvailabiltyZoneFilter filter, which means that if a user selects an availability zone at provisioning time, then the instance will land only on any of the compute instances grouped under that availability zone.
Another example of the AggregateInstanceExtraSpecsFilter filter that means that if a custom flavor (CPU, RAM, and disk) is tagged with a key value pair and a host aggregate is tagged with the same key value pair, then if a user deploys with that flavor the AggregateInstanceExtraSpecsFilter filter will place all instances on compute hosts under that host aggregate.
These host aggregates can be assigned to specific teams, which means that teams can be selective about which applications they share their compute with and can be used to prevent noisy neighbor syndrome. There is a wide array of filters that can be applied in OpenStack in all sorts of orders to dictate instance scheduling. OpenStack allows cloud operators to create a traditional cloud model with large groups of contended compute to more bespoke use cases where the isolation of compute resources is required for particular application workloads.
The following example shows host aggregates with groups and shows a host aggregate named 1-Host-Aggregate, grouped under an Availability Zone named DC1 containing two compute hosts (hypervisors), which could be allocated to a particular team:

When an instance (virtual machine) is provisioned in OpenStack, the following high-level steps are carried out:
The Nova compute service will issue a request for a new instance (virtual machine) using the image selected from the glance images service
The nova request may then be queued by RabbitMQ before being processed (RabbitMQ allows OpenStack to deal with multiple simultaneous provisioning requests)
Once the request for a new instance is processed, the request will write a new row into the nova Galera database in the nova database
Nova will look at the nova scheduler rules defined on the OpenStack controllers and will use those rules to place the instance on an available compute node (KVM hypervisor)
If an available hypervisor is found that meets the nova scheduler rules, then the provisioning process will begin
Nova will check whether the image already exists on the matched hypervisor. If it doesn't, the image will be transferred from the hypervisor and booted from local disk
Nova will issue a neutron request, which will create a new VPort in OpenStack and map it to the neutron network
The VPort information will then be written to both the nova and neutron databases in Galera to correlate the instance with the network
Neutron will issue a DHCP request to assign the instance a private IP address from an unallocated IP address from the subnet it has been associated with
A private IP address will then be assigned, and the instance will start to start up on the private network
The neutron metadata service will then be contacted to retrieve cloud-init information on boot, which will assign a DNS entry to the instance from the named server, if specified
Once cloud-init has run, the instance will be ready to use
Floating IPs can then be assigned to the instance to NAT to external networks to make the instances publicly accessible
Like AWS OpenStack also offers a Load-Balancer-as-a-Service (LBaaS) option that allows incoming requests to be distributed evenly among designated instances using a Virtual IP (VIP). The features and functionality supported by LBaaS are dependent on the vendor plugin that is used.
Popular LBaaS plugins in OpenStack are:
Citrix NetScaler
F5
HaProxy
Avi networks
These load balancers all expose varying degrees of features to the OpenStack LBaaS agent. The main driver for utilizing LBaaS on OpenStack is that it allows users to use LBaaS as a broker to the load balancing solution, allowing users to use the OpenStack API or configure the load balancer via the horizon GUI.
LBaaS allows load balancing to be set up within a tenant network in OpenStack. Using LBaaS means that if for any reason a user wishes to use a new load balancer vendor as opposed to their incumbent one; as long as they are using OpenStack LBaaS, it is made much easier. As all calls or administration are being done via the LBaaS APIs or Horizon, no changes would be required to the orchestration scripting required to provision and administrate the load balancer, and they wouldn't be tied into each vendor's custom APIs and the load balancing solution becomes a commodity.