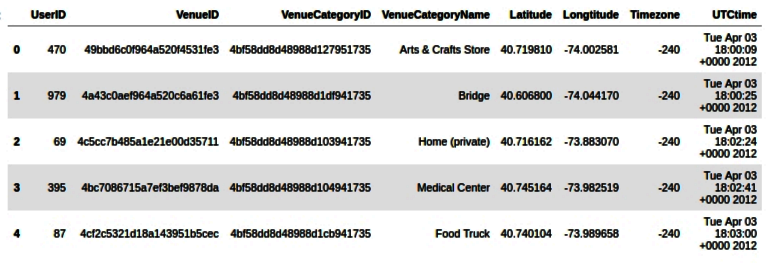
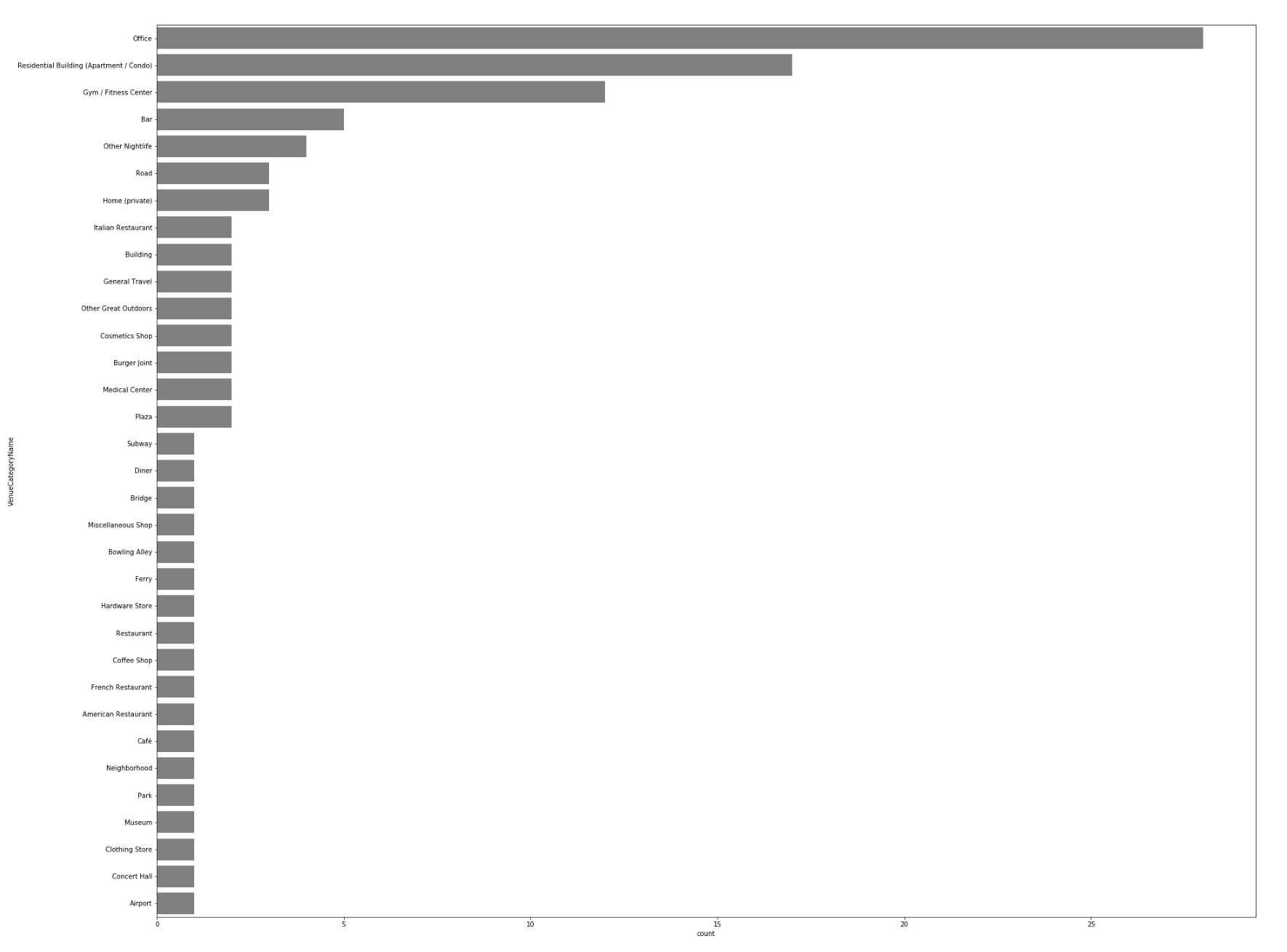
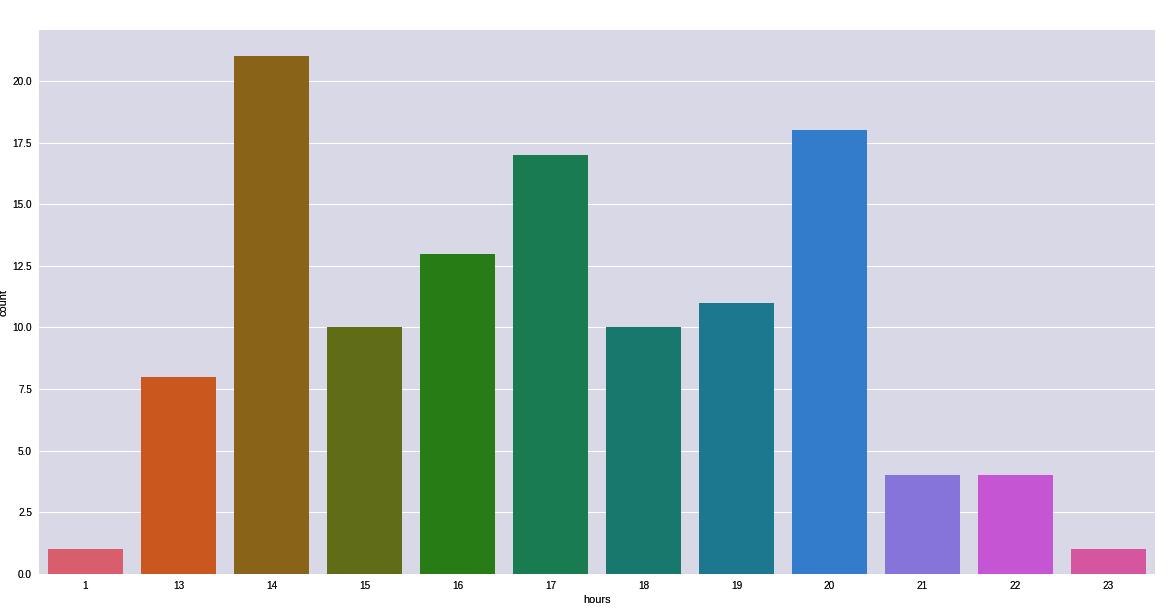
Every industry uses location intelligence. It helps industries understand what their customers are doing, where their customers are based, what the geographic environment of their customers is, and what their interests are. Location intelligence is normally defined as using location data with other attributes to add context and derive useful information, services, and products that help organizations make effective and efficient decisions. The information derived through location intelligence can have a business and economic insights as well as environmental and social insights.
-
Book Overview & Buying

-
Table Of Contents

Geospatial Data Science Quick Start Guide
By :
Geospatial Data Science Quick Start Guide
By:
Overview of this book
Data scientists, who have access to vast data streams, are a bit myopic when it comes to intrinsic and extrinsic location-based data and are missing out on the intelligence it can provide to their models. This book demonstrates effective techniques for using the power of data science and geospatial intelligence to build effective, intelligent data models that make use of location-based data to give useful predictions and analyses.
This book begins with a quick overview of the fundamentals of location-based data and how techniques such as Exploratory Data Analysis can be applied to it. We then delve into spatial operations such as computing distances, areas, extents, centroids, buffer polygons, intersecting geometries, geocoding, and more, which adds additional context to location data. Moving ahead, you will learn how to quickly build and deploy a geo-fencing system using Python. Lastly, you will learn how to leverage geospatial analysis techniques in popular recommendation systems such as collaborative filtering and location-based recommendations, and more.
By the end of the book, you will be a rockstar when it comes to performing geospatial analysis with ease.
Table of Contents (9 chapters)
Preface
 Free Chapter
Free Chapter
Introducing Location Intelligence
Consuming Location Data Like a Data Scientist
Performing Spatial Operations Like a Pro
Making Sense of Humongous Location Datasets
Nudging Check-Ins with Geofences
Let's Build a Routing Engine
Getting Location Recommender Systems
Other Books You May Enjoy