As previously mentioned, cloud native applications have associated challenges that need to be tackled to get them ready for production. Cloud native system designers should have a broad understanding of cloud native concepts. These concepts allow the developer to design and construct a better system. In this section, we will focus on software development methodologies used to build cloud native applications.
The twelve-factor app
Heroku engineers came up with twelve factors that should be adhered to for SaaS applications. The twelve-factor app methodology is specifically designed to create applications running on cloud platforms. The twelve-factor app allows the following to be carried out in cloud native applications:
- Minimize the time it takes to understand the system. Teams are agile and can be changed quickly. When new people join the team, they should be able to understand the system and set up the development environment locally.
- Provide complete portability between execution environments. This ensures that the system is decoupled from the underlying infrastructure and OS. The system is capable of being deployed independently from the OS.
- Suitable for use on modern cloud platforms. This reduces the maintenance costs associated with developing large cloud applications.
- Minimize the difference between the development and production environments. This makes CD straightforward, as the automated system can make any changes instantly with little effort.
- As the system is divided into several components that can perform independently, the system can scale with little effort. As these components are stateless, they can be scaled up or down easily.
Here are the twelve factors that you should consider when a cloud application is being developed:
- Code base
- Dependencies
- Config
- Backing services
- Build, release, run
- Processes
- Port binding
- Concurrency
- Disposability
- Dev/prod parity
- Logs
- Admin processes
The following subsections will discuss these factors in detail.
Code base
Version control systems (VCSes) are used for the code base in a central repository. The most common VCS is Git, which is faster and easier to use than SubVersion (SVN). It is not only important to have a VCS to manage the code in different versions, but it also helps to maintain the CI/CD pipeline. This allows for automated deployment where developers can send the pull request and automatically deploy the system with new improvements once it is merged.
The code base should be a single repository in the twelve-factor app, where all related programs are stored. This means you can't have several repositories for a single application. Having multiple repositories means that it is a distributed system rather than an app. You can split the code into several repositories and use it as a dependency when you need it in your application.
On the other hand, multiple deployments can be done in a single repository. These deployments may be for development, QA, or production purposes. But the code base should stay the same for all deployments. This means all deployments are generated by a single repository.
Dependencies
If you have dependencies that need to be added to a service, you should not copy the dependencies to the repository of the project code. Instead, dependencies are added via a dependency management tool. Manifest files are often used to add dependencies to a project.
Ballerina has a central repository where you can store dependencies and use them on a project by adding them to the dependency manifest. Ballerina uses the Dependencies.toml file as the dependency declaration file where you can add a dependency. During compilation, the Ballerina compiler pulls dependencies from the Ballerina Central repository if they are not available locally.
Another requirement of dependencies is that you specify the exact version of the dependencies used in the manifest file. Dependency isolation is the principle of ensuring that no implicit dependencies are leaked into a system. This makes code more reliable even when new developers start developing an application; they can easily set up a system without any problems. It's common to have a dependency conflict when creating an application. Finding this issue becomes a headache if the number of dependencies in the application is high. Always use the specific version that matches your application.
Ballerina offers built-in support for versioning and importing dependency modules along with the version. Ballerina pulls the latest dependencies from Ballerina Central at compile time. However, you can be specific with versioning when there are inter-module compatibility issues. This makes it simple when developers need to use a particular version, instead of always referring to the latest version, which may not be compatible.
Config
Applications certainly have configurations that need to be installed before a task is running. For example, think about using the following application configurations:
- Database connection string
- Backend service access credentials, such as username, password, and tokens
- Application environment data, such as IP, port, and DNS names
This factor requires that these configurations be kept out of the source code as the configurations can be updated more often than the source code. When the Ballerina program runs, it can load these configurations and configure the product out of the source code.
You can have a separate config file to keep all the required configurations. But twelve-factor app suggest using environmental variables to configure the system rather than using configuration files. Unlike config files, using an environment variable prevents adding configuration into the code repository accidentally as well.
On the other hand, it is a major security risk to maintain sensitive data such as passwords and authentication tokens in source code. Only at runtime should such data be needed. You can store this data in a secure vault or as an encrypted string that is decrypted at runtime.
Swan Lake Ballerina provides support for both file-based and environment-based configurations. The configs can be read directly from the environment variable by the Ballerina program. Otherwise, you can read configurations from the configuration file and overwrite it with an environment variable when the application starts up. This approach makes it simple for the config file to hold the default value and to override it with the environment variable.
Backing services
Backing services are the infrastructure or services that support an application service. These services include databases, message brokers, SMTP, and other API-accessible resources. In the twelve-factor app, these resources are loosely coupled so that if any of these resources fail, another resource can replace them. You should be able to change a resource without modifying the code.
There is no difference between local and third-party services for a twelve-factor app. Even though your database resides in your local machine or is managed by a third party, the application does not care about the location; rather, it cares about accessing the resource. For example, if your database is configured as local and later you need to switch to a third-party database provider, there should be no changes to the code repository. You should be able to change the database connection string by simply changing a system configuration.
Build, release, run
In the twelve-factor app, it is mandatory to split the deployment process into three distinct phases – build, release, and run:
- Build: In this phase, automated deployment tools use VCS code to build executable artifacts. The executable artifact is a set of JAR files for Ballerina. In this step, automated tests should be carried out to complete the task of building. If the tests fail, the entire deployment process should be stopped. When code changes are merged into the repository, the automated deployment tools will start building the application.
- Release: In the release stage, build the artifacts package together with the config to create the release package along with a unique release number. Each release has this unique number, which is mostly a timestamp-dependent ID. This specific ID can be used as an ID to switch back to the previous state. If the deployment fails, the system can automatically roll back to the last successful deployment.
- Run: This step is to run the application on the desired infrastructure. Deployment may take a few different stages, such as development, QA, stage, and production. The application is in the development pipeline to be deployed in production.
Processes
This factor forces developers to create stateless processes rather than stateful applications. The same process may be running in multiple instances of the system where scalability is necessary. Load balancers sitting in front of the processes distribute traffic between the processes. As there are several processes, we cannot guarantee that the same request dealt with earlier will obtain the same process again. Therefore, you need to make sure that these processes do not hold any state: it just reads data from the database, processes it, and stores it again.
Anything cached in memory to speed up the process is not worth it in the twelve-factor app. Since the next request will serve another process, caching is useless. Even for a single process, the process can die at any time and start again. There is also no great benefit in keeping the cache in memory or on disk.
Sticky sessions where a request is routed from the same visitor are not the best practice with the twelve-factor app. Instead, you can use scalable cache stores such as Memcached or Redis to store session information.
This applies to the filesystem as well. In certain cases, you may need to write data to a local filesystem. But keep in mind that the local filesystem is unreliable and, once the process is finished, keep it in a proper place.
Port binding
Some web applications, such as Java, run on the Tomcat web server, where the port is set across the entire application. The twelve-factor app does not recommend the use of runtime injections on a web server. Instead, apps should be self-contained; the port should read from the configuration and be set up by the application itself.
Compared to the Ballerina language, you can specify which ports should be exposed by specifying the port on the program itself. This is important where services are exposed as managed APIs for either the end user or another service. The principle of port binding is that the program should be self-contained.
Concurrency
Processes are first-class citizens in twelve-factor app. Instead of writing a single large application, divide it into smaller different processes where each process can separately start, terminate, and replicate independently. Don't depend on vertical scaling to add more resources to scale the application. Instead, increase the number of instances running the service. The load balancer may distribute traffic between these services. Increase the number of services when the load goes up, and vice versa.
Disposability
Twelve-factor app services should be able to start and stop within a minimal amount of time. Suppose, for instance, one service fails, and the system has to replace the failed system with a new instance clone. The new instance should be able to take responsibility as soon as possible to improve resilience. Ideally, an instance should be up and running within a few seconds after it is deployed. Since it takes less time to start the application, scaling up the system would also become more responsive.
On the other side, the process should be able to terminate as soon as possible. In the event of a system scale down or a process moving from one node to another node, the process should terminate quickly and gracefully with a SIGTERM signal from the process manager. In the event of the graceful shutdown of an HTTP server, no new incoming requests will be accepted. But long-running protocols, such as socket connections, should be handled properly by both the server and the client. When the server stops, the client should be able to connect to another service and continue to run.
In the event of sudden death due to infrastructure failure, the system should be designed in a way that it can handle client disconnection. A queuing backend can be used to get a job back in the queue when the job dies suddenly. Then another service will proceed with the task by reading the queue.
Dev/prod parity
This factor is to make sure that the gap is as minimal as possible between the development and production environments. A developer should be able to test the deployment in their local environment and push the code to the repository. Deployment tools take on these changes and deploy them in production. The goal of this factor is to make new improvements to production with minimal disruptions. The difference between dev and prod environments can be due to the following reasons:
- The time gap: After integrating new functionality into the system, the developer will take some time to deploy code into the production environment. The code can be quickly reflected in the deployment by reducing this time gap. This solves problems with code compatibility between multiple teams of developers. Since the application is built by different teams, it can cause tons of discrepancies that take time to integrate components.
- The personal gap: Another gap is that the code is created by developers and deployed by operations engineers. The twelve-factor app forces developers to also be involved in the deployment process and analyze how the deployment process is going.
- The tool gap: Developers cannot use tools that are not used for production. For example, an H2 database may be used by the developer to create a product, while a MySQL database may be used in production. Therefore, make sure that you use the same resources that have already been used for production in the development environment as well.
Containerized applications should be able to adjust the environment by simply modifying the configuration. For example, if the system is running on the production or development environment, the developer can change the configuration to the developer mode and test it on the local computer. The automated tool can change the mode to production mode and deploy it to the production environment.
Logs
Logs are output streams that are created by an application and are necessary for the system to debug when it fails. The popular way to log is to print it to your stdout or filesystem. The twelve-factor app is not concerned with routing or storing logs. Instead, the program logs are written directly to stdout. There are tools, such as log routers, that collect and store these logs from the application environment. None of this log routing or configuring is important to the code, and developers only concentrate on logging data into the console.
Ballerina includes a logging framework where you can quickly log in to different log levels. Logging can be easily incorporated with tools such as Elasticsearch, Logstash, and Kibana, where you can easily keep and visualize logs.
Admin processes
This factor enforces the one-off processes of running admin and management processes. Other than the long-running process that manages business logic, there could be other supporting processes, such as database migration and inspection processes. These one-off processes should also be carried out in the same environment as the business process.
Developers may attach one-off tasks to the deployment in such a way that it executes when it is deployed.
Twelve-factor app provide sets of guidelines to create cloud native applications that need to be followed. This allows developers to construct stateless systems that can be deployed with minimal effort in production. The Ballerina language offers support for all of these factors, and in the following chapters, we will look at how these principles can be implemented in practice.
Now let's look at another design approach, API-first design, which speeds up the development process by designing API interfaces first.
API-first design
As mentioned previously, services are designed to solve a particular business problem. Each service has its own functionality to execute. This leads to the problem of design first versus code first. The traditional approach, which is code first, is to build the API along with the development. In this case, the API documentation is created from the code.
On the other hand, design first forces the developer to concentrate more on the design of the API rather than on internal implementations. In API-first design, the design is the starting point of building the system. A common example for code first is that when you are building a service, you write the code and generate the WSDL definition automatically. Swagger also allows this type of development method by generating the relevant OpenAPI documentation from the source code. On the other hand, Swagger Codegen lets the developer create the source code based on the API specifications. This is known as the design-first approach, in which code is generated from the API.
The code-first approach is used when it comes to speed of delivery. Developers can create an application with the requirement documentation and generate the API later. The API is created from the code and can change over time. Developers can create an internal API using this approach, since an internal team can work together to build the system.
If the target customer is outside of your organization, the API is the way they communicate with your system. The API plays a key role in your application in this scenario. The API specification is a good starting point for developers to start developing applications. The API specification acts as a requirement document for an application.
Multiple teams can work in parallel because each service implementation is a matter for each team and the API determines the final output.
There are advantages and disadvantages associated with each of these design patterns. Nowadays, with the emergence of cloud-based architecture, API-first design plays a key role in software development. Multiple teams work collaboratively to incorporate each of the services in the design of microservices. REST is a common protocol that is widely used to communicate with services. The OpenAPI definition can be used to share the API specifications with others. Protobuf is another protocol that strongly supports API-first development, which is widely used in GRPC communication.
The 4+1 view model
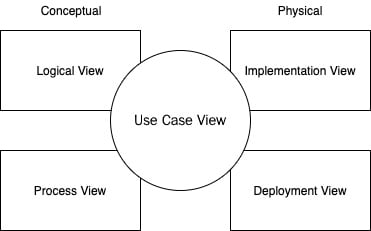
Whatever programming languages you use, the first step when developing software applications is to gather all the specifications and design the system. Only then can you move on to the implementation. Philippe Kruchten came up with the idea of analyzing the architecture of software in five views called the 4+1 view model. This model gives you a set of views where you can examine a system from different viewpoints:
Figure 1.7 – The 4+1 view model
Let's talk about this briefly:
- Logical View: The logical view includes the components that make up the structure. This emphasizes the relationship between the class and the package. In this view, you can decompose the system into classes and packages and evaluate the system using the Object-Oriented Programming (OOP). Classes, states, and object diagrams are widely used to represent this view.
- Process View: This explains the process inside the system and how it interacts with other processes. This view analyzes the process behavior, concurrency, and the flow of information between different processes. This view is crucial in explaining the overall system throughput, availability, and concurrency. Activity, sequence, and communication diagrams can be used to analyze and present this view.
- Deployment View: This view describes how the process is mapped to the host computer. This gives you a building block view of the system. Deployment diagrams can be used to visualize this kind of view.
- Implementation View: This view illustrates the output of the build system from the viewpoint of the programmer. This view emphasizes bundled code, components, and units that can be deployed. This also gives you a building block view of the system. Developers need to organize hierarchical layers, reuse libraries, and pick different tools and software management. Component diagrams are used to visualize this view.
- Use Case View: This is the +1 in the 4+1 view model, where all views are animated. This view uses goals and scenarios to visualize the system. Use case diagrams are usually used to display this view.
To demonstrate how a cloud native application is built with the Ballerina language, we will introduce an example system. We will build an order management system to demonstrate different aspects of cloud native technologies. We will discuss this example throughout this book. In the next section, let's gain an understanding of the basic requirements of this system and come up with an architecture that complies with cloud native architecture.
Building an order management system
The software design process begins with an overview of the requirements. During the initial event storming, developers, subject experts, and all other related roles work together to gather system requirements. Throughout this book, we're going to address developing cloud native systems by referring to a basic order management system.
You will gain an understanding of the requirements of this order management system in this section.
An example scenario of an order management system can be visualized with the following steps:
Figure 1.8 – Order management system workflow
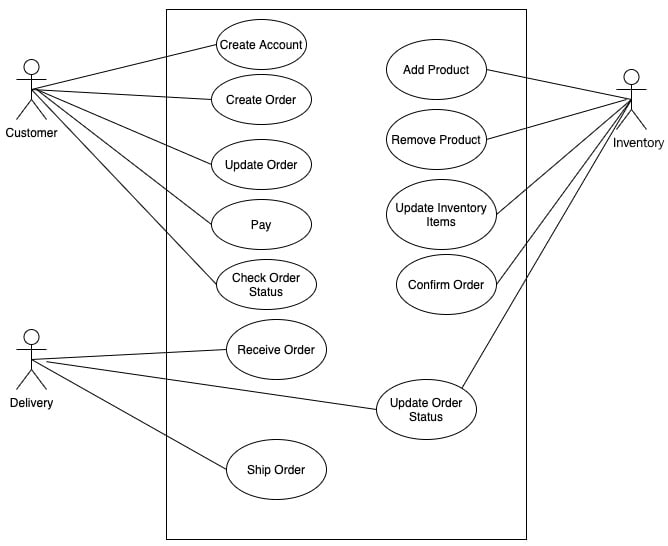
The customer begins by placing an order. The customer may then add, remove, or update products from the order. The system will confirm the order with inventory once the order items are picked by the customer. If products are available in the inventory, the payment can be made by the customer. Once the payment has been completed, the delivery service will take the order and ship it to the desired location.
Use cases can be represented with a use case diagram, as follows for this system:
Figure 1.9 – Use case diagram for the order management system
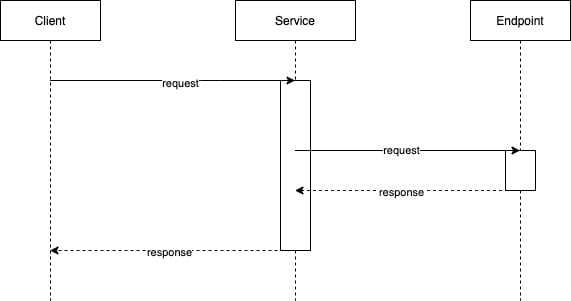
Diagrams play a vital role in the design and analysis of a system. As defined in the 4+1 view, for each of these views, the designer may draw diagrams to visualize the different aspects of the system. Due to the distributed nature of cloud native applications, sequence diagrams play a key role in their development. Sequence diagrams display the association of objects, resources, or processes over a period of time. Let's have a look at a sample sequence diagram where the client calls a service, and the service responds after calling a remote backend endpoint:
Figure 1.10 – Sequence diagram
Building order management systems to fulfill these requirements is easy and straightforward with monolithic applications. Based on the three-tier architecture, we can divide the system into three layers that manage the UI, business logic, and database. Interfaces can be web pages loaded in a web browser. The UI sends requests to the server, which has an API that handles the request. You can use a single database to store the application data. We can break down the application into several components to modularize it. Unlike a monolithic architecture, when we break this system into loosely coupled services, it allows developers to take a much more convenient approach to building and managing the system.
How small each service should be is a decision that should be made by looking at the overall design. Large services are harder to scale and maintain. Small services have too many dependencies and network communication overhead. Let's discuss breaking down the services of a large system with an example in the next section.
Breaking down services
When developing microservices, how small the microservices should be is a common problem. It's certainly not dependent on the number of code lines that each of the components has. The concept of the Single-Responsibility Principle (SRP) for object-oriented principles was developed by Robert C. Martin. SRP enforces that a class of a component should have only one reason to change. Services should have a single purpose and the service domain should be limited.
The order management system can be broken down into the following loosely coupled services, and each of the services has its own responsibilities:
- Order service: The order service is responsible for the placement and maintenance of orders. Customers should be able to generate orders and update them. Once customers have added products from an inventory, the payment will then be made.
- Inventory service: The inventory service maintains products that are available in the store. Sellers can add and remove items from the inventory. The customer can list products and add them to their order.
- Payment service: The payment service connects with a payment gateway from a third party and charges for the order. The system does not hold card details, as all of these can be managed by payment gateway systems. When the payment has been made, the system sends an email to the customer with payment details.
- Delivery service: The delivery service can add and remove delivery methods. The user can select a delivery method from the delivery service. The delivery service takes the order and ships the order to the location specified by the customer.
- Notification service: Details of the payment and order status are sent to the client via the email notification system. To send notifications, the notification service connects to an email gateway.
We need to come up with a proper way of communicating with each of these services once the single service is split into multiple services. The HTTP protocol is a good candidate for inter-process communication.
It is simple for scenarios such as making an order as the order service receives the request from the customer and adds a database record to the order table. Then several products are added to the same order by the client. The order service gets and stores these products in the database. The customer places the order for verification when they have finished selecting products. In this case, the order service must check with the inventory service for product availability. Since the inventory service is decoupled, the order service needs to send the inventory service a remote network call to confirm the order.
HTTP is known as a synchronous form of communication, where clients wait until the server responds. This might create a bottleneck in the order service as it waits to get the response from the inventory service. Asynchronous communication methods, such as JMS and AMQP, play an important role in developing distributed systems in this type of scenario. Brokers take the orders and dispatch them asynchronously to the inventory service.
Asynchronous communication protocol plays a key role in the architecture of microservices as it decouples services. Microservice architecture relies heavily on asynchronous communication to adopt event-driven architecture. Event-driven architecture allows programmers to create events-based programs rather than procedural commands. Message brokers serve as a layer of mediation for events. Message brokers offer the guaranteed delivery of messages with topics and queues. Events published on each channel are consumed and executed by other services. We will discuss event-driven architecture more in Chapter 5, Accessing Data in Microservice Architecture.
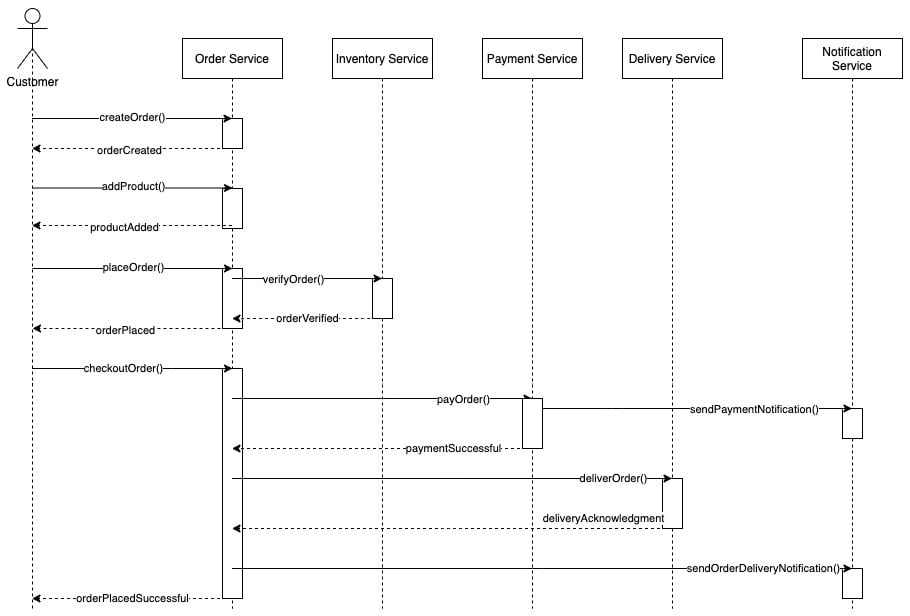
If the order has been verified, the customer may proceed to payment. The payment service uses a third-party payment gateway to complete the financial transaction. Once the transaction is completed, the order can be sent to the delivery service to deliver the product. Notification services send notifications such as payment and order information and delivery status to the customer.
Sample sequence diagrams can be generated as follows based on these service separations:
Figure 1.11 – Sequence diagram for the order management system
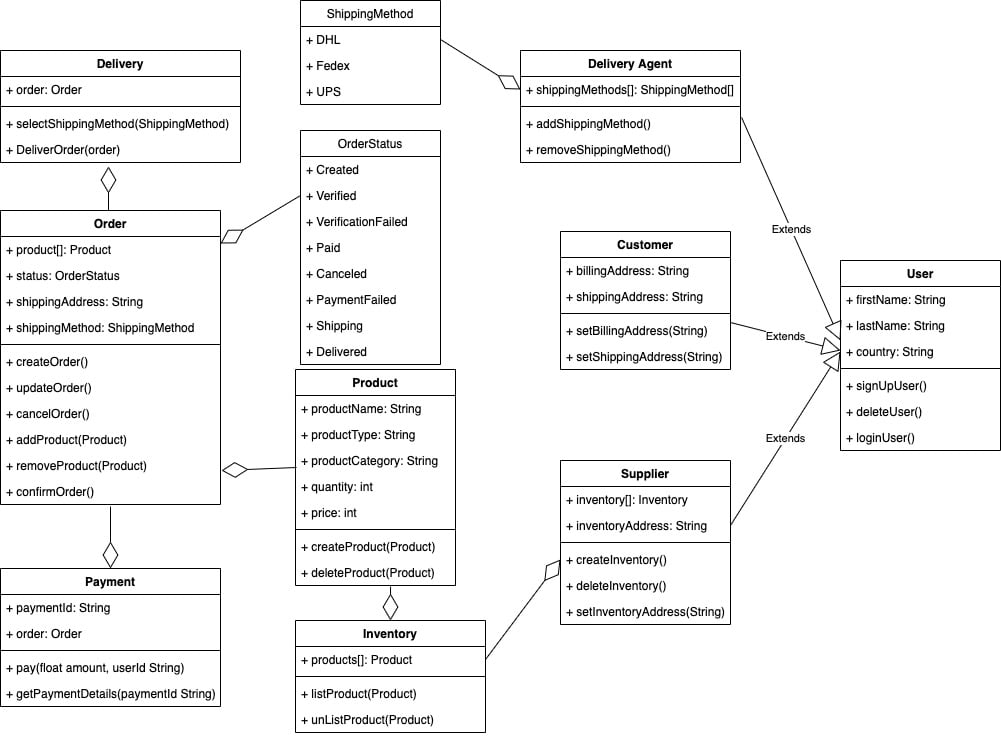
There are certain entities that interact with the system, such as customers, orders, products, inventory, and so on. Modeling these entities makes the architecture of the system more understandable. Next, we'll look at a class diagram to represent this system. Each entity in the system has a specific task associated with it. Each class in the diagram represents the functionality assigned to each object:
Figure 1.12 – Class diagram for the order management system
In data-driven design, a class diagram can easily be translated to a database scheme and the system design can be started from there. Because the architecture of microservices fits well with event-driven architecture, class diagrams do not explicitly infer system design, even though the class diagram plays a crucial role in defining and developing the system as it identifies the entities that interact with the system.
In the following chapters, we will review these initial specifications and come up with a design model to construct this order management system in a cloud native architecture using the Ballerina language.
So far, we have discussed what cloud native architecture is and the properties that it should have. But we always need to remember the fact that cloud native is not just all about technology. It is also associated with the humans that build, maintain, and use the system. The next section discusses how to adopt cloud native technologies in an organization.






 Free Chapter
Free Chapter