

OpenStack is a cloud operating system software that allows running and managing Infrastructure as a Service (IaaS) clouds on the standard commodity hardware. OpenStack is not an operating system of its own, which manages bare metal hardware machines, is a stack of open source software projects. The projects run on top of Linux operating system. The projects usually consist of several components that run as Linux services on top of the operating system.
OpenStack lets users to rapidly deploy instances of virtual machines or Linux containers on the fly, which run different kinds of workloads that serve public online services or deployed privately on company's premise. In some cases, workloads can run both on private environment, and on a public cloud, creating a hybrid model cloud.
OpenStack has a modular architecture. Projects are constructed of functional components. Each project has several components that are responsible for project's sole functionality. An API component exposes its capabilities, functionalities, and objects it manages via standard HTTP Restful API, so it can be consumed as a service by other services and users.
The components are responsible for managing and maintaining services, and the actual implementation of the services leverage exciting technologies such as backend drivers.
Basically, OpenStack is an upper layer management system that leverages existing underlying technologies and presents a standard API layer for services to interconnect and interact.
The computing industry and information technology, in particular, made a major progress in the past 20 year moving toward distributed systems that use common standards. OpenStack is another step forward, introducing a new standard for technologies that were progressing separately in the past two decades, to interconnect in an industry standard manner.
OpenStack environment consists of projects that provide their functionality as services. Each project is designed to provide a specific function. The core projects are the required services in most OpenStack environments, and in most use cases, an OpenStack environment cannot run without them. Additional projects are optional and provide value and add or fulfill certain functionalities for the cloud.
Core services provided by OpenStack projects are as follows:
Keystone authenticates and authorizes commands and requests.
Neutron is the project that provides networking for the instances as a service. Older releases used Nova-network service to provide networking connectivity to the instance, which is a part of the Nova project, but efforts are made to deprecate Nova-network in favor of Neutron.
Optional services provide additional functionality but are not considered as necessary in every OpenStack environment:
The complete list of additional projects is growing rapidly, and every new release has several new projects.
All services use a database service, usually MariaDB to store persistent data, and use a message broker for service inner communication, most commonly, RabbitMQ server.
To better understand this design concept, let's take one project to explore this. Nova is a project that manages the compute resources. Basically, Nova is responsible for launching and managing instances for virtual machines. Nova is implemented via several components such as Linux services. Nova-Compute Linux service is responsible for launching the VM instances. It does not implement a virtualization technology hypervisor, rather it uses a virtualization technology as a supportive backend mechanism, kernel-based virtual machine (KVM) with the libvirt driver in most cases, to launch KVM instances.
Nova API Linux service exposes Nova's capabilities via RESTful API and allows launching new instances, using standard RESTful API calls. To launch new instances, Nova needs a base image to boot from, and Nova makes an API call to Glance, which is the project responsible for serving images.
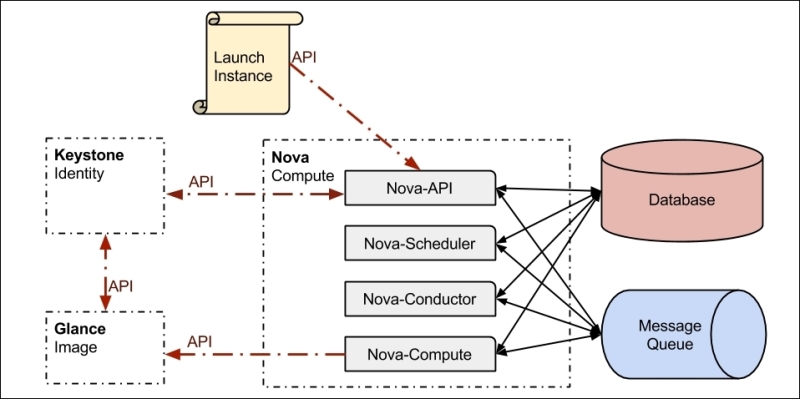
OpenStack consists of several core projects—Nova for compute, Glance for images, Cinder for block storage, Keystone for Identity, Neutron for networking, and additional optional services. Each project exposes all its capabilities via RESTful API. The services inner-communicate over RESTful API calls, so when a service requires resources from another service, it makes a RESTful API call to query services' capabilities, list its resources, or call for a certain action.
Every OpenStack project consists of several components. Each component fulfills a certain functionality or performs a certain task. The components are standard POSIX Linux services, which use a message broker server for inner component communication of that project, using RabbitMQ in most cases. The services save their persistent data and objects states in a database.
All OpenStack services use this modular design. Each services has a component that is responsible to receive API calls, and other components are responsible for performing actions, for example, launching a virtual machine or creating a volume, weighing filters and scheduling, or other tasks that are part of project's functionality.
This design makes OpenStack highly modular; the components of each project can be installed on separate hosts while inner communicating via the message broker. There's no single permutation that fits all use cases OpenStack is used for, but there are a few commonly used layouts. Some layouts are easier for management, some focus on scaling compute resources, other layouts focus on scaling object storage, each with its own benefits and drawbacks.
In all-in-one layout, all OpenStack's services and components, including the database, message broker, and Nova-Compute service are installed on a single host. All-in-one layout is mostly used for testing OpenStack or while running proof of concept environments to evaluate functionality. While Nova-Compute nodes can be added for additional compute scalability, this layout introduces risks when using a single node as management plane, storage pool, and compute.
In Controller computes layout, all API services and components responsible for OpenStack management are deployed on a node, named OpenStack controller node. This includes Keystone Identity, Glance for instance images, Cinder block device, Neutron networking, Nova management, Horizon dashboard, message broker, and database services. All networking services are installed on Neutron Network Node—L3 Agent, Open vSwitch (L2) Agent, DHCP agent, and metadata service. Compute Nodes run Nova-Compute services that are responsible for running the instances as shown in the following chart:
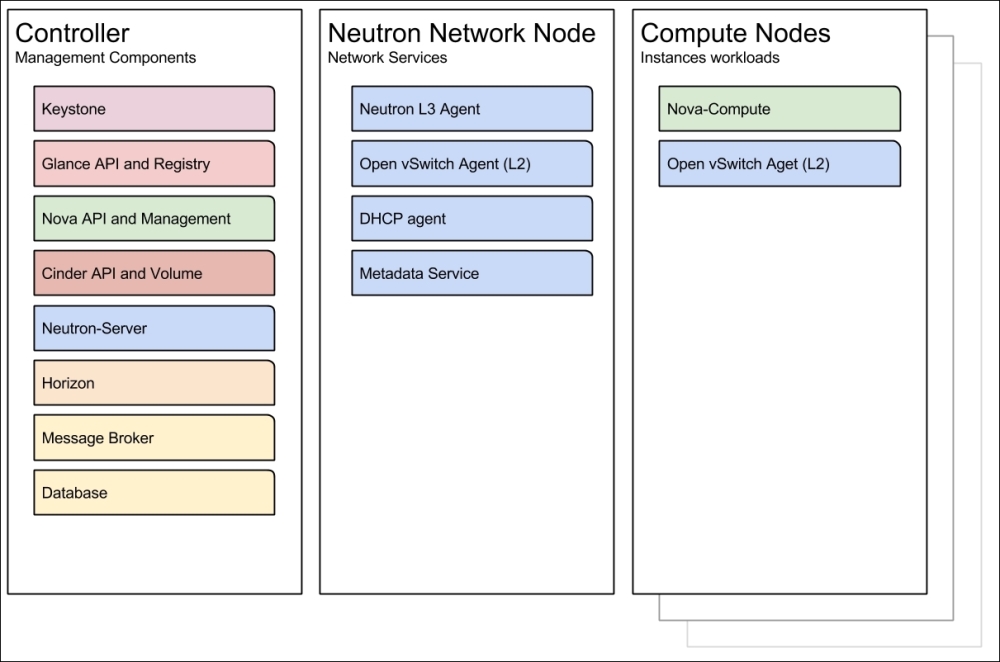
This layout allows the compute resources to scale out to multiple nodes while keeping all management and all API components on a single control plane. The controller is easy to maintain and manage as all API interfaces are on a single node. Neutron network node manages the all layer 2 and layer 3 networks, virtual subnets, and all virtual routers. It is also responsible for routing traffic to external networks, which are not managed by Neutron.
Typically, large-scale environments run under heavy loads, along with running large amount of instances and handling large amount of simultaneous API calls. To handle such high loads, it is possible to deploy the services in a distributed layout, where every service is installed on its own dedicated node, and every node can individually scale out to additional nodes according to the load of each component. In the following diagram, all services are distributed based on core functionality. All Nova management services are installed on dedicated nodes:

Project Tuskar aims to become the standard way to deploy and OpenStack environments. While the project started to gain momentum in recent release cycles, the need to deploy OpenStack in a standard predictable manner existed from OpenStacks early days. This need brought various deployment tools to use.
OpenStack project's source code is available on GitHub, while the different distributions compile the source code and ship it as packaged, RPMs for Red Hat bases operating systems, and .deb files for Ubuntu-based systems. One way to deploy OpenStack is to install distribution packages based on a chosen deployed layout and manually configure all services and components needed for fully operational OpenStack environment. This manual process is fairly complex and requires being familiar with all basic configurations needed for OpenStack to function.
This chapter focuses on packages' deployment and manual configuration of the services, as this is a good practice to become familiar with all the basic configurations and getting ready for more advanced OpenStack configurations.
Configuring OpenStack services manually is a complex task, that requires editing lots of files and configuring lots of depending services, as such, it is a very error-prone process. A common way to automate this process is to use configuration management tools, such as Puppet, Chef, or Ansible, for installing OpenStack packages and automate all the configuration needed for OpenStack to operate. There's a large community, developing open source Puppet modules and Chef cookbooks to deploy OpenStack, which are available on GitHub.
PackStack is a utility that uses Puppet modules to deploy OpenStack on multiple preinstalled nodes automatically. It requires neither Puppet skills nor being familiar with OpenStack configuration. Installing OpenStack using PackStack is fairly simple; all it reacquires is to execute a single command #packstack --gen-answer-file to generate an answers file that desires the deployment layout and to initiate deployment run with #packstack --answer-file=/path/to/packstack_answers.txt.
The project Staypuft is an OpenStack deployment tool, which is based on Foreman, a robust and mature life cycle management tool. Staypuft includes a user interface designed specifically to deploy OpenStack and uses supporting Puppet modules. It also includes a discovery tool to easily add and deploy new hardware, and it can deploy the controller node with high availability configuration for production use.
Staypuft makes it easy to install OpenStack, with lower learning curve than managing Puppet modules manually, and it is more robust than using Packstack. Chapter 2, Deploying OpenStack Using Staypuft OpenStack Installer, will describe how to install a new OpenStack environment using Staypuft.
This chapter covers the manual installation of OpenStack from RDO distribution packages and the manual configuration of all basic OpenStack services. As mentioned earlier, manually installing OpenStack is not the optimal way to set up an OpenStack environment, as it involves numerous manual steps that are not easily reproducible and very error-prone, but the manual process is a great way to get familiar with all OpenStack internal components.
The following diagram describes a high-level design of most OpenStack services and outlines the steps needed for configuring an OpenStack service:

Basic OpenStack service configuration will include configuring the service to use Keystone as authentication strategy, authenticating and authorizing incoming API calls, a database connection in which the service will store metadata about the objects it manages, and the message broker, which the Linux services use to inner communicate.
The most important, and usually the most complex, part is to configure the service to use a backend for its core functionality, for example, Nova, which launches virtual machines, can use libvirtd as a backend services provider that actually launches KVM virtual machines on the local Linux node. Another good example is Keystone that can be configured to use Lightweight Directory Access Protocol (LDAP) server as a backend to store user credentials instead of storing user credentials in the SQL database.
Over the course of this chapter, we will install and configure OpenStack using RDO distribution packages of kilo release, on top of CentOS 7.0 Linux operating system. We will deploy controller-Neutron-computes layout with a single controller node, one Neutron network node, and one compute node, additional compute nodes can be easily added to the environment following the same steps to install the compute node.
Operating system: CentOS 7.0 or newer
OpenStack distribution: RDO kilo release
Architecture layout: controller-Neutron-computes
Every service that we install and configure while following this chapter will require its own database user account, and a Keystone user account. It is highly recommended for security reasons to choose a unique password for each account. For ease of deployment, it is recommended to maintain a password list as in the following table:
|
Database accounts |
Password |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
Keystone accounts |
Password |
|
|
|
|
|
|
|
|
|
This chapter focuses on the controller-Neutron-computes topology layout. Before starting the installation of packages, we need to ensure that network interfaces are correctly wired and configured.
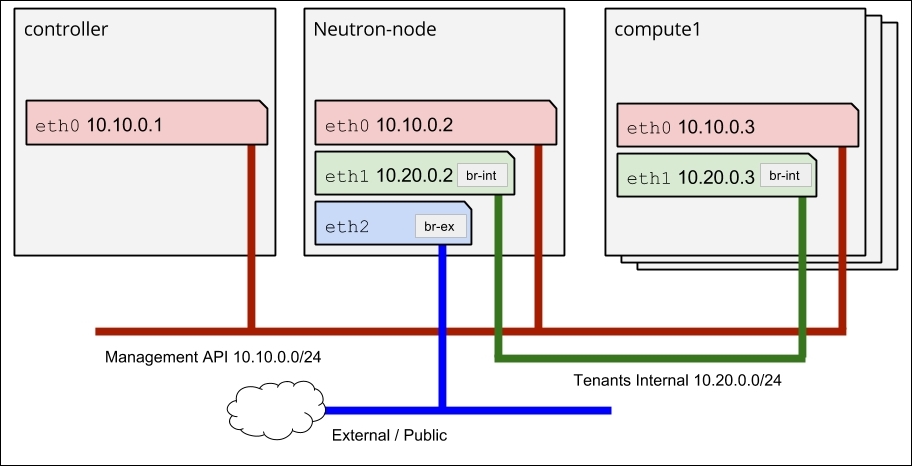
All nodes in our environment use eth0 as a management interface; the controller node exposes OpenStack's APIs via eth0. Neutron network node and compute nodes use eth1 for tenant's network; Neutron uses the tenant's network to route traffic between instances. Neutron network node uses eth2 for routing traffic from instances to the public network, which could be organization's IT network or publicly accessible network, as shown in the following diagram:
Note
Neutron service configuration in this chapter and Chapter 7, Neutron Networking Service, Neutron software defined network service will further discuss the creation of bridges needed for Neutron br-int and br-ex.
All hostnames should be resolvable on to their management network IP addresses.
|
Role |
Host Name |
NICs |
|---|---|---|
|
Controller node |
|
|
|
Neutron network node |
|
|
|
Compute node |
|
|