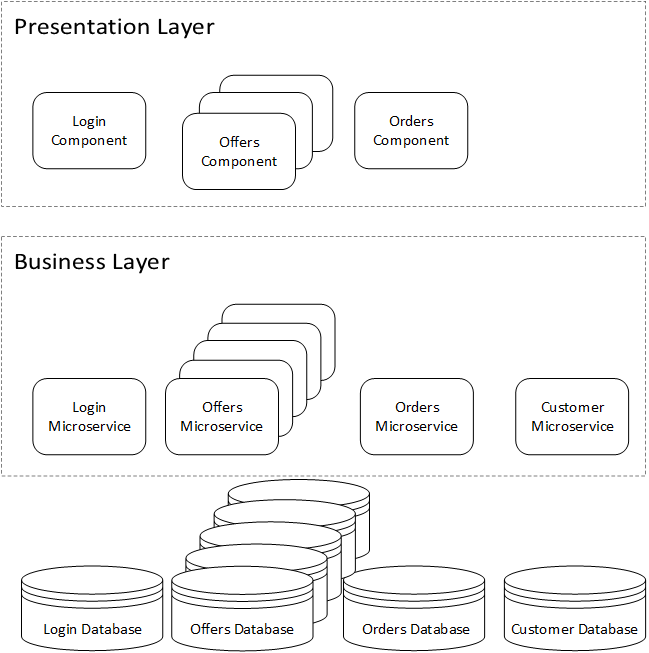
Defining microservices principles will allow us to build scalable, easy-to-maintain enterprise applications. We will focus on benefits and downsides when we review them. We understand that sometimes there could be some disagreement in some of them; however, we encourage you to review them all. Finally, we know that there are probably dozens or more principles that could be included, but we chose the ones that made most sense in the context of this book.
-
Book Overview & Buying

-
Table Of Contents

Hands-On Microservices with Kotlin
By :
Hands-On Microservices with Kotlin
By:
Overview of this book
With Google's inclusion of first-class support for Kotlin in their Android
ecosystem, Kotlin's future as a mainstream language is assured. Microservices help
design scalable, easy-to-maintain web applications; Kotlin allows us to take
advantage of modern idioms to simplify our development and create high-quality
services. With 100% interoperability with the JVM, Kotlin makes working with
existing Java code easier. Well-known Java systems such as Spring, Jackson, and
Reactor have included Kotlin modules to exploit its language features.
This book guides the reader in designing and implementing services, and producing
production-ready, testable, lean code that's shorter and simpler than a traditional
Java implementation. Reap the benefits of using the reactive paradigm and take
advantage of non-blocking techniques to take your services to the next level in terms
of industry standards. You will consume NoSQL databases reactively to allow you
to create high-throughput microservices. Create cloud-native microservices that
can run on a wide range of cloud providers, and monitor them. You will create Docker
containers for your microservices and scale them. Finally, you will deploy your
microservices in OpenShift Online.
Table of Contents (14 chapters)
Preface
 Free Chapter
Free Chapter
Understanding Microservices
Getting Started with Spring Boot 2.0
Creating RESTful Services
Creating Reactive Microservices
Reactive Spring Data
Creating Cloud-Native Microservices
Creating Dockers
Scaling Microservices
Testing Spring Microservices
Monitoring Microservices
Deploying Microservices
Best Practices
Other Books You May Enjoy