

The following sections describe solutions to the preceding problems. Remember that there usually isn't a single correct way to solve a particular problem. Also remember that the explanations shown here include only the most interesting and important details needed to solve the problems. Download the example solutions to see additional details and to experiment with the programs at https://github.com/PacktPublishing/The-Modern-CSharp-Challenge/tree/master/Chapter01.
Extension methods must be contained in a public static class. This solution uses the following declaration for its StatisticsExtensions class:
public static class StatisticsExtensions
{
...
}Extension methods must also be declared as public and static. Their first parameter should be marked with the this keyword to indicate that the parameter is the object that is being extended.
The following code shows the TruncatedMean extension method:
// Return the truncated mean of an IEnumerable of numbers.
// Set discardNumber to the number of values to discard at the
// top and bottom. For example, set discardNumber = 5 to
// discard the 5 largest and smallest values.
public static double TruncatedMean<T>(this IEnumerable<T> values,
int discardNumber)
{
// Convert the values into an enumerable of doubles.
IEnumerable<double> doubles =
values.Select(value => Convert.ToDouble(value));
double[] doubleArray = doubles.ToArray();
// Sort the doubles.
Array.Sort(doubleArray);
// Find the values that we want to use.
int minIndex = discardNumber;
int maxIndex = doubleArray.Length - 1 - discardNumber;
// Copy the desired items into a new array.
int numRemaining = maxIndex - minIndex + 1;
double[] remainingItems = new double[numRemaining];
Array.Copy(doubleArray, minIndex, remainingItems, 0, numRemaining);
// Calculate and return the truncated mean.
return remainingItems.Average();
}
This method has a generic type parameter, T, between its name and its parameter list. The first parameter has type IEnumerable<T>, so the method extends that type. Because both arrays and lists implement IEnumerable, this means that the method applies to both arrays and lists.
The method's second parameter indicates the number of largest and smallest items that should be removed for the truncated mean.
Even if the input values are integers, their mean might not be an integer, so the method returns a double.
In order to discard the largest and smallest items, the method must sort the inputs. It cannot do that with objects that have the generic type T, so the code uses a LINQ query to convert the items into a list of double. The method uses the query to make an array of double and sorts it.
Note
If the values are not numeric, this code will throw an exception when it tries to convert the values into doubles.
Next, the code calculates the indices of the first and last items that it should keep when it discards the largest and smallest values. It uses Array.Copy to copy those values into a new array, uses the Average LINQ extension method to calculate the mean of the remaining values, and returns the result.
This extension method takes, as its second parameter, the number of largest and smallest values that it should discard. The following overloaded version of the method takes a discard fraction as a parameter instead:
// Return the truncated mean of an IEnumerable of numbers.
// Set discardFraction to the fraction of values to discard at the
// top and bottom. For example, set discardFraction = 0.05 to
// discard the 5% largest and smallest values.
public static double TruncatedMean<T>(this IEnumerable<T> values,
double discardFraction)
{
// Calculate the number of items to remove at the top and bottom.
int discardNumber = (int)(values.Count() * discardFraction);
// Invoke the previous version of TruncatedMean.
return TruncatedMean(values, discardNumber);
}
This method uses the discard fraction to calculate the number of values that it should discard. It then invokes the previous version of the method.
The following code shows the Median extension method:
// Return the median of an IEnumerable of numbers.
public static double Median<T>(this IEnumerable<T> values)
{
// Convert into an enumerable of doubles.
IEnumerable<double> doubles =
values.Select(value => Convert.ToDouble(value));
double[] doubleArray = doubles.ToArray();
// Sort the doubles.
Array.Sort(doubleArray);
// Calculate and return the median.
int numValues = doubleArray.Length;
if (numValues % 2 == 1)
{
// There are an odd number of values.
// Return the middle one.
return doubleArray[numValues / 2];
}
// Return the mean of the two middle values.
double value1 = doubleArray[numValues / 2 - 1];
double value2 = doubleArray[numValues / 2];
return (value1 + value2) / 2.0;
}In order to find the value in the middle of the others, the method must sort the values. To do that, the method converts the values into an array of double and then sorts it, just like the first version of the TruncatedMean method did.
Next, if the resulting array contains an odd number of values, the method calculates the index of the middle value and returns that value.
If the double array contains an even number of values, the method calculates the indices of the two middle values and returns the average of those values.
The following code shows the Modes extension method, which finds the values' modes:
// Return the mode(s) of an IEnumerable of numbers.
public static List<T> Modes<T>(this IEnumerable<T> values)
{
// Make a dictionary to hold value counts.
Dictionary<T, int> counts = new Dictionary<T, int>();
// Count the values.
foreach (T value in values)
{
if (!counts.ContainsKey(value))
counts.Add(value, 1);
else
counts[value]++;
}
// Find the largest count.
int largestCount = counts.Values.Max();
// Find the value(s) with that count.
List<T> modes = new List<T>();
foreach (KeyValuePair<T, int> pair in counts)
if (pair.Value == largestCount) modes.Add(pair.Key);
return modes;
}This method creates a dictionary to hold counts for the values. The dictionary's keys are the original values, and the associated values are the counts.
After it creates the dictionary, the code loops through the values. When it comes to a value that is not already in the dictionary, the code adds it to the dictionary, setting its initial count to 1.
If the dictionary already contains a value, then the code increments its count.
After it has counted all of the values, the code uses the Max LINQ extension method to find the largest count.
The code then loops through the key/value pairs in the dictionary. If a pair has a count equal to the largest count, the code adds it to the list of modes.
After it has processed all of the values, the method returns the modes list.
Note
This method returns the items in the values list that occur the most, even if that value is non-numeric. For example, if the values are names, the method will return the names that occur the most.
The following code shows the final method in the StatisticsExtensions class, StdDev:
// Return the standard deviation of an IEnumerable of numbers.
//
// If the second argument is True, evaluate as a sample.
// If the second argument is False, evaluate as a population.
public static double StdDev<T>(this IEnumerable<T> values,
bool asSample = false)
{
// Convert into an enumerable of doubles.
IEnumerable<double> doubles =
values.Select(value => Convert.ToDouble(value));
// Get the number of items and the mean.
int numValues = doubles.Count();
double mean = doubles.Average();
// Get the sum of the squares of the differences between
// the values and the mean.
var squaresQuery =
from double value in doubles
select (value - mean) * (value - mean);
double sumOfSquares = squaresQuery.Sum();
// Return the apppropriate type of standard deviation.
if (asSample)
return Math.Sqrt(sumOfSquares / (numValues - 1));
return Math.Sqrt(sumOfSquares / numValues);
}This method converts the values into a double array as usual. It then gets the number of values and their mean.
Next, the code makes a LINQ query that selects the square of the difference between a value in the array and the mean. It then uses the Sum method to add all of those differences squared.
Finally, the method divides by the number of values, or one less than the number of values depending on whether it is calculating a sample or population standard deviation.
Now the main program can use extension methods to calculate statistical values. For example, it uses the following code to display the median of the values in the array named valuesArray:
arrayMedianTextBox.Text = valuesArray.Median().ToString("0.00");The following code shows a useful technique that the program uses to display the mode, which is a list of values:
arrayModeTextBox.Text = string.Join(" ",
valuesArray.Modes().ConvertAll(i => i.ToString()));This statement calls the Modes extension method to get the modes. It uses the ConvertAll LINQ extension method to convert the list of mode values into a list of strings. It then uses string.Join to combine the strings into a single string with the values separated by space characters.
Download the StatisticalFunctions example solution to see additional details, such as how the program uses labels to build its histogram.
This example defines extension methods in the static ArrangingExtensions class. The following code shows the main Permutations method:
// Find permutations containing the desired number of items.
public static List<List<T>> Permutations<T>(this T[] values, int numPerGroup)
{
int numValues = values.Count();
bool[] used = new bool[numValues];
List<T> currentSolution = new List<T>();
return FindPermutations(values, numPerGroup, currentSolution,
used, numValues);
}This method gets the number of values in the array and then creates an array of bool with the same size. The program will use that array to keep track of which values are in the solution as the code works on it.
The code then creates a List<T> to hold the current solution. It passes the values, the desired number of items in each permutation, the current solution (initially empty), the used array (initially all false), and the number of values into the following FindPermutations helper method:
// Find permutations that include the current solution.
private static List<List<T>> FindPermutations<T>(T[] values,
int numPerGroup, List<T> currentSolution, bool[] used,
int numValues)
{
List<List<T>> results = new List<List<T>>();
// If this solution has the desired length, return it.
if (currentSolution.Count() == numPerGroup)
{
// Make a copy because currentSolution will change over time.
List<T> copy = new List<T>(currentSolution);
results.Add(copy);
return results;
}
// Try adding other values to the solution.
for (int i = 0; i < numValues; i++)
{
// See if value[i] is in the solution yet.
if (!used[i])
{
// Try adding this value.
used[i] = true;
currentSolution.Add(values[i]);
// Recursively look for solutions that have values[i]
// added.
List<List<T>> newResults =
FindPermutations(values, numPerGroup, currentSolution,
used, numValues);
results.AddRange(newResults);
// Remove values[i].
used[i] = false;
currentSolution.RemoveAt(currentSolution.Count() - 1);
}
}
return results;
}
Before I describe the FindPermutations method in detail, it's worth giving you a short overview. The method calls itself recursively to build the permutations. When it is called, the currentSolution list holds the beginning of a permutation. The method examines the other items that are not already in the permutation (as determined by their used values being false) and adds some to the current solution.
Now, on to the method's details. The method begins by checking the number of items in the current solution. If that solution contains the desired number of items, then it is a valid solution so the method returns it.
However, the currentSolution list will be changed later as instances of the FindPermutations method pass the currentSolution variable back and forth. If the method simply returned currentSolution, its value would change later and that would destroy the current solution.
In order to preserve the current solution, the method makes a copy of it and returns the copy.
If the current solution isn't long enough, the method loops through all of the items trying to extend the solution. If an item's used flag indicates that it is not yet in the solution, the method tries adding it.
The method sets the item's used value to true, adds it to the current solution, and then recursively calls itself to continue building the solution. Other recursive calls to FindPermutations will add more items to the solution until it has the desired length.
After the recursive call returns, the method adds any results returned by that call to the results list.
The method then removes the most recently added item from the current solution by setting its used value to false and removing it from the currentSolution list. The method does that so it can consider other items for the next position in the solution.
After it has considered adding all of the items to the solution, the method returns whatever results it has found.
Notice that the method considers all of the items that are not yet part of the solution. For example, suppose the current solution contains three items. The method could place any of the remaining items in the fourth position.
If an item is not used in the fourth position, it might be added later by another recursive call to FindPermutations.
In particular, consider the items in positions i and j in the original array of values. The FindPermutations method could add item i and then later add item j, or it could add item j and then later add item i. The values could appear in any positions and in any order. This flexibility of ordering is what makes the result a permutation. You should contrast this with the combinations produced by the next solution.
One special case that is not handled is by the previous Permutations method, that is, when the numPerGroup parameter is omitted. In that case, the Permutations method should return permutations of every possible length. The following overloaded version of the method does just that:
// Find permutations containing any number of items.
public static List<List<T>> Permutations<T>(this T[] values)
{
List<List<T>> results = new List<List<T>>();
// Get permutations of all lengths.
for (int i = 1; i <= values.Count(); i++)
results.AddRange(values.Permutations(i));
return results;
}This version of the Permutations method loops through all of the possible permutation lengths between 1 and the number of values present. It calls the previous version of the method to find permutations of those lengths, combines the results into a single list, and returns it.
The solution's main program uses the Permutations extension methods to display permutations. The heart of the program is shown in the following code snippet:
// Get the inputs.
char[] separators = { ' ' };
string[] values = valuesTextBox.Text.Split(separators, StringSplitOptions.RemoveEmptyEntries);
int numPerGroup = int.Parse(numPerGroupTextBox.Text);
// Get the permutations.
List<List<string>> permutations;
if (numPerGroup == 0)
permutations = values.Permutations();
else
permutations = values.Permutations(numPerGroup);
// Display the results.
foreach (List<string> permutation in permutations)
resultsListBox.Items.Add(string.Join(" ", permutation.ToArray()));
This code gets the values and the number of items that should be in each permutation. Next, the method calls the Permutations extension method on the values array. It finishes by looping through the permutations, adding each to the result list box. It uses the technique described in the preceding solution to convert the permutation list into a string containing values separated by spaces.
Download the Permutations example solution to see additional details.
The Combinations method works much like the Permutations method did in the preceding section. The main Combinations method calls the FindCombinations helper method to do most of the work recursively. That method loops through the values, adds them to the growing current solution, and calls itself recursively to build longer combinations.
The following code shows the Combinations method:
// Find combinations containing the desired number of items.
public static List<List<T>> Combinations<T>(this T[] values,
int numPerGroup)
{
int numValues = values.Count();
bool[] used = new bool[numValues];
List<T> currentSolution = new List<T>();
return FindCombinations(values, numPerGroup, currentSolution,
used, 0, numValues);
}See the description of the Permutations method in the preceding section for details about how this method works.
The following code shows the FindCombinations method:
// Find Combinations that include the current solution.
private static List<List<T>> FindCombinations<T>(T[] values,
int numPerGroup, List<T> currentSolution, bool[] used,
int firstIndex, int numValues)
{
List<List<T>> results = new List<List<T>>();
// If this solution has the desired length, return it.
if (currentSolution.Count() == numPerGroup)
{
// Make a copy because currentSolution will change over time.
List<T> copy = new List<T>(currentSolution);
results.Add(copy);
return results;
}
// Try adding other values to the solution.
for (int i = firstIndex; i < numValues; i++)
{
// See if value[i] is in the solution yet.
if (!used[i])
{
// Try adding this value.
used[i] = true;
currentSolution.Add(values[i]);
// Recursively look for solutions that have values[i]
// added.
List<List<T>> newResults =
FindCombinations(values, numPerGroup, currentSolution,
used, i + 1, numValues);
results.AddRange(newResults);
// Remove values[i].
used[i] = false;
currentSolution.RemoveAt(currentSolution.Count() - 1);
}
}
return results;
}This method is somewhat similar to the FindPermutations method described in the preceding section, with the major exception that it takes a parameter that gives the index of the first item that the method should consider adding to the solution. When the method loops through the values, it only considers the items that have this index or later.
This prevents the method from adding items in orders other than the one in which they appear in the values array. For example, suppose i and j are indices of items in the array and that i < j. Then this method would consider adding values[i] and then later adding values[j], but it would not consider adding values[j] before adding values[i] because i < j.
By keeping the values in their sorted order, the method produces combinations rather than permutations.
The following code shows the overloaded version of the Combinations method that returns combinations of any length:
// Find combinations containing any number of items.
public static List<List<T>> Combinations<T>(this T[] values)
{
List<List<T>> results = new List<List<T>>();
// Get combinations of all lengths.
for (int i = 1; i <= values.Count(); i++)
results.AddRange(values.Combinations(i));
return results;
}This method loops through the possible combination sizes, calls the earlier version of the Combinations method to get combinations of those lengths, combines them, and returns the result.
The solution's main program is similar to the one for the preceding problem. See the preceding section for more information and download the Combinations example solution to see additional details.
The following code shows a recursive method for calculating factorials:
// Calculate the factorial recursively.
private long RecursiveFactorial(long number)
{
checked
{
if (number <= 1) return 1;
return number * RecursiveFactorial(number - 1);
}
}This method first checks whether number is less than or equal to 1. If number ≤ 1, the method returns 1. If number is greater than 1, the method calls itself recursively to calculate (number – 1)! and then returns number times (number – 1)!.
The following code shows a non-recursive method for calculating factorials:
// Calculate the factorial non-recursively.
private long NonRecursiveFactorial(long number)
{
checked
{
long total = 1;
for (long i = 2; i <= number; i++) total *= i;
return total;
}
}This method initializes the total variable to 1. It then enters a loop where it multiples total by the values between 2 and number. The result is 1 × 2 × 3 × ... × number, which is the factorial.
Some recursive programs may have very large depths of recursion where the method calls itself so many times that the stack memory is exhausted and the program crashes. For example, if a program tried to calculate RecursiveFactorial(1000000), the method would call itself 1 million times. That could exhaust the program's stack space and crash the program.
Fortunately (or unfortunately, depending on how you look at it), the factorial function grows extremely quickly, so the number of recursive calls that will work is limited. These methods use 64-bit long integers to perform their calculations, so they can only hold values up to 9,223,372,036,854,775,807. The value 20! is 2,432,902,008,176,640,000 and the value 21! is too big to fit in a 64-bit integer, so the program can only calculate values up to 20! anyway. That means the recursive version can use, at most, 20 levels of recursion, and the program will never exhaust its stack space.
In general, non-recursive versions of methods are often better than recursive versions because they don't make as many demands on stack memory, but in this example the difference doesn't really matter. The limiting factor for this program is the fact that the factorial method grows so quickly that it can exceed the limits of 64-bit integers.
That brings us to the most important lesson in this example. By default, C# does not check integer operations for overflow. If the result of an integer operation is too big to fit inside the appropriate data type, the program normally does not notice. Instead, it continues merrily along using whatever garbage is present in its variables as if nothing was wrong.
You can force C# to check for integer overflow by placing risky statements inside a checked block, as shown in preceding code. If you omit the checked statements, the factorial methods will try to calculate values for numbers greater than 20. For example, they will report that 21! is -4,249,290,049,419,214,848, which is clearly wrong because it's a negative number. If you try to calculate factorials for much larger values such as 10,000 or 1 million, the program will exhaust its stack space.
C# ignores integer overflow for performance reasons, although in my tests, using a checked block only increased runtime by about 10%. The moral of all this is that if a certain calculation may cause an integer overflow, then you should place it inside a checked block.
Note
A group of checked blocks does not nest across method calls the way try catch blocks do. For example, if a checked block includes a method call and that method might cause an integer overflow, then the method also needs its own checked block because the calling checked block will not protect it.
Download the Factorials example solution to see additional details.
The following code shows a recursive method that calculates Fibonacci numbers:
// Calculate the Fibonacci number recursively.
private long RecursiveFibonacci(int number)
{
checked
{
// On 0 or 1, return 0 or 1.
if (number <= 1) return number;
// Fibonacci(N) = Fibonacci(N - 1) + Fibonacci(N - 2).
return
RecursiveFibonacci(number - 1) +
RecursiveFibonacci(number - 2);
}
}This method simply follows the recursive definition of Fibonacci numbers.
Fibonacci numbers grow very quickly (although not as quickly as the factorial function), so the program uses a checked block to protect itself from integer overflow errors.
Unfortunately, this method has a more pressing problem—it recalculates certain values a huge number of times. For example, suppose you want to calculate FN. To do that, the method calls itself to calculate FN-1 and FN-2. Then, to calculate FN-1, the method calls itself to calculate FN-2 and FN-3. Here, the method is calculating FN-2 twice.
If you follow the recursive calls further, you'll find that the method calls itself to recalculate the same values an enormous number of times. The following diagram shows the calls needed to calculate F5:
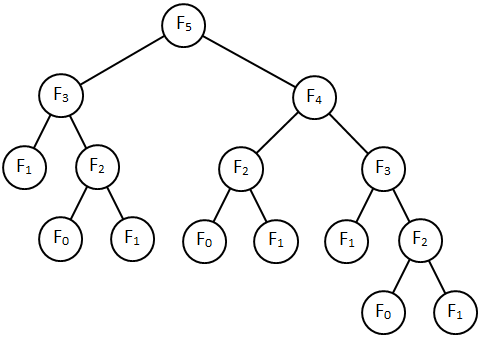
You can see in the preceding diagram that the values F1 and F0 are calculated many times. Those values are easy to calculate, but if the tree were bigger, the method would also calculate more complicated values many times. The following table shows the total number of times the method is called while calculating various Fibonacci numbers:
Value | Method Calls |
F5 | 15 |
F10 | 177 |
F15 | 1,973 |
F20 | 21,891 |
F25 | 242,785 |
F30 | 2,692,537 |
F35 | 29,860,703 |
F40 | 331,160,281 |
You can see from the preceding table that the number of method calls grows very quickly.The method calls itself so many times that it cannot calculate values larger than around F45 in a reasonable amount of time.
In cases such as this, you need to remove the need for all of the duplicate calculations. One way to do that is to change the way you think about the recursive definition of Fibonacci numbers. Recall the following definition:
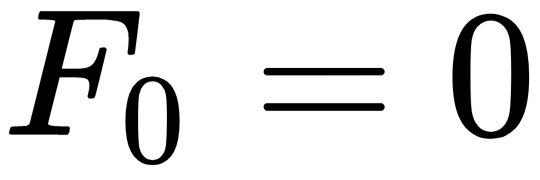
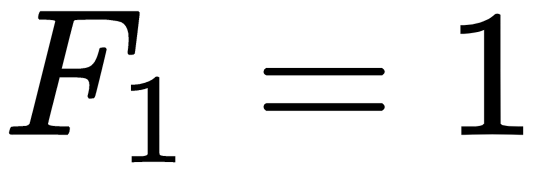
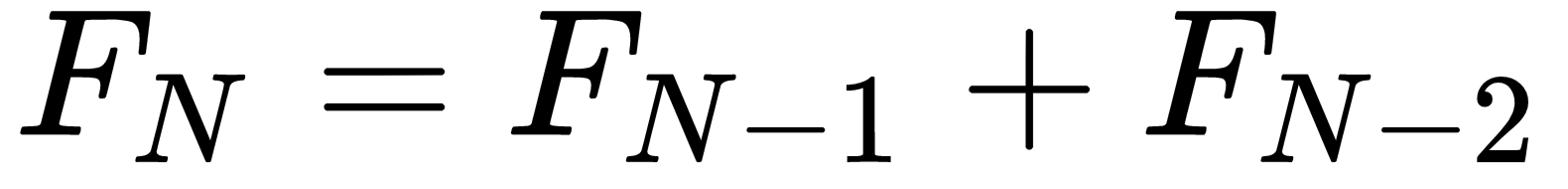
for N>1
The previous method used a top-down approach, where it started with a large value (say F10) and then recursively called itself to calculate the smaller values needed to build that value (F9 and F8).
Alternatively, you can take a bottom-up approach, where you build smaller values and then use them to create larger ones. The following method uses the bottom-up approach:
// Calculate the Fibonacci number non-recursively.
private long NonRecursiveFibonacci(int number)
{
checked
{
// On 0 or 1, return 0 or 1.
if (number <= 1) return number;
// Start at i = 2.
long fiboIMinus2 = 0; // Fibonacci(0)
long fiboIMinus1 = 1; // Fibonacci(1)
long fiboI = fiboIMinus1 + fiboIMinus2; // Fibonacci(2)
for (int i = 2; i < number; i++)
{
// Update the values.
fiboIMinus2 = fiboIMinus1;
fiboIMinus1 = fiboI;
fiboI = fiboIMinus1 + fiboIMinus2;
}
return fiboI;
}
}
This method uses variables to hold the values Fi, Fi-1, and Fi-2 as it performs its calculations. It enters a loop where it uses Fi-1 and Fi-2 to calculate Fi until it has calculated the value it needs.
This version calculates each Fibonacci value once. For example, to calculate F40, it calculates F0, F1, and F2, and so on for a total of 40 calculations instead of the 331 million required by the recursive method.
This non-recursive version is extremely efficient, but it's also rather confusing because it requires you to keep track of which variables hold which values.
A table of values can sometimes make this sort of recursion removal easier to understand. The following method stores values in an array and then fills the array until it has calculated the value that it needs:
// Use a table to calculate the Fibonacci number non-recursively.
private long TableFibonacci(int number)
{
checked
{
// Make a table to hold Fibonacci values.
long[] values = new long[number + 1];
// Initialize Fibonacci(0) and Fibonacci(1).
values[0] = 0;
values[1] = 1;
// Fill the table.
for (int i = 2; i <= number; i++)
values[i] = values[i - 1] + values[i - 2];
// Return values[number].
return values[number];
}
}This version is also fast and effective. Its one drawback is that it recreates the table every time it calculates a Fibonacci value. It might be nice to keep any previously calculated values for later use. The following method uses a cache to hold values in case they are needed later:
// Use a cache table to calculate the Fibonacci number non-recursively.
private long[] FibonacciCache = null;
private long CachedFibonacci(int number)
{
// Initialize the cache if necessary.
if (FibonacciCache == null)
{
// Initialize the table to hold all -1 entries.
// Fibonacci(92) is the largest value that doesn't overflow.
const int MaxNumber = 92;
FibonacciCache =
Enumerable.Repeat(-1L, MaxNumber + 1).ToArray();
// Initialize Fibonacci(0) and Fibonacci(1).
FibonacciCache[0] = 0;
FibonacciCache[1] = 1;
}
// Use the cache to calculate the Fibonacci number.
checked
{
// We don't have the value. Calculate and save it.
if (FibonacciCache[number] < 0) FibonacciCache[number] =
CachedFibonacci(number - 1) +
CachedFibonacci(number - 2);
// Return the cached value.
return FibonacciCache[number];
}
}This code defines the cache array outside the method. When the method starts, it checks the cache to see if it has been initialized. If the cache is null, the method creates a new array with each entry set to -1. It then initializes the first two values to F0 = 0 and F1 = 1. (The method gives the array 93 positions with indices 0 through 92 because F92 is the largest Fibonacci number that fits in a long integer.)
The method then checks the cache to see if it has already calculated the value that it needs. If the value is not yet in the cache, the method calls itself recursively to store that value in the array. It can then return the desired value.
This method follows the same general approach as the initial recursive approach. The big difference is that it stores any value that it calculates so that it doesn't need to calculate the same values again and again. For example, if you look back at the earlier diagram, you'll see that the tree calculates F4 twice. The new method would only calculate that value once and save it, so it would chop off the entire F4 subtree from the calculation. When calculating larger values, the savings are huge.
Even better, after a while the cache table will contain all of the Fibonacci numbers up to F92, so the method will never need to perform new calculations. You could even prefill the table when the program starts so that the method can look up values later.
There's one more point about this example worth mentioning. Fibonacci numbers don't grow as quickly as factorials, but they do grow quickly, so large Fibonacci numbers will overflow 64-bit long integers. For that reason, the methods protect themselves with checked blocks.
To summarize, there are several lessons to be learned from this example. First, if a recursive solution works and is easy to understand, then use it. If a recursive approach recalculates the same values many times, try a bottom-up approach. If a bottom-up approach is confusing, consider saving intermediate values in a table. Finally, if you're using a table, ask yourself whether it's worth converting the table into a cache so that you can reuse saved values later.
Download the FibonacciNumbers example solution to see additional details.
The following method simply uses the formula for calculating the binomial coefficient:
// Calculate the binomial coefficient.
private long CalculatedNchooseK(int n, int k)
{
checked
{
return Factorial(n) / Factorial(k) / Factorial(n - k);
}
}This is quick and easy, but it only works if the factorials are all small enough to be calculated. For example, it is obvious that
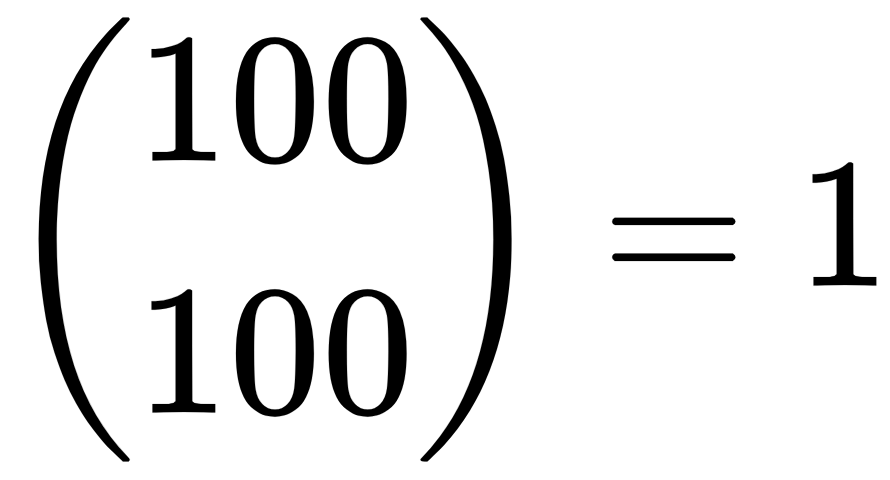
because there's only one way to pick 100 items out of 100 items, namely picking all of them.
Unfortunately, to use the formula, the method must calculate 100!, and we know from the Solution to Problem4. Factorials, that a program can only calculate factorials up to 20!. Larger values such as 100! cause integer overflow. Even though the final solution may be perfectly reasonable, the formula is impractical if N or K is greater than 20.
The problem statement asked you to verify the following:
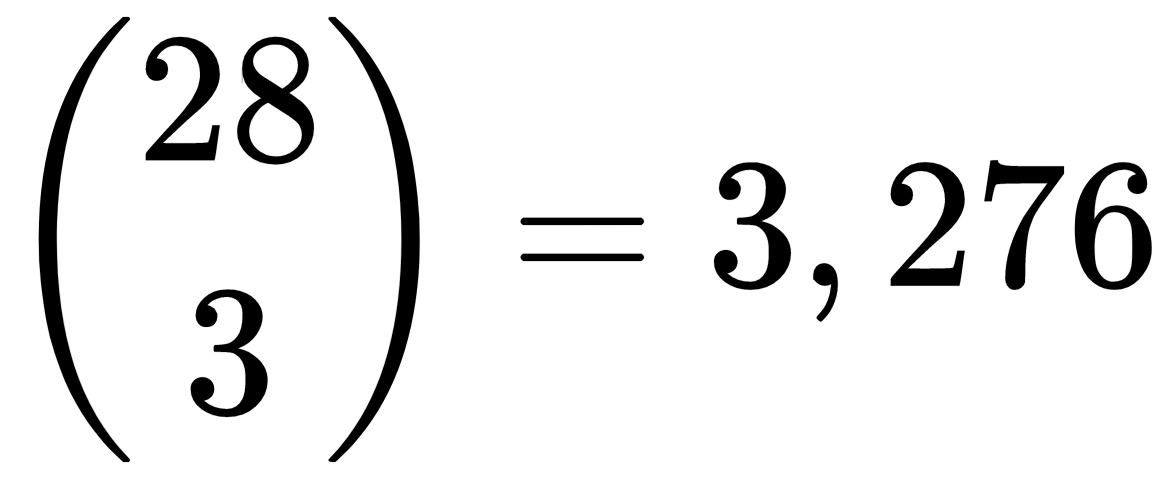
Unfortunately, 28! is too big to fit in a long integer, so this method cannot calculate that value. Fortunately, there's another way to calculate binomial coefficients.
Recall that
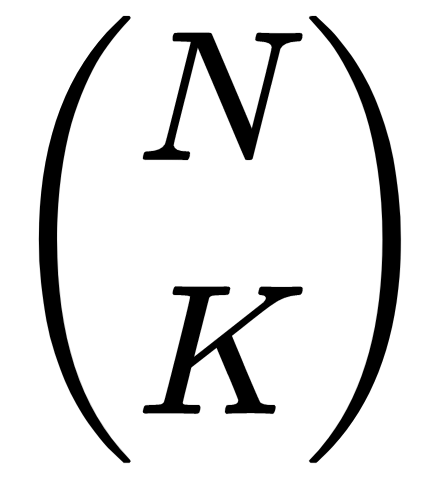
gives the number of ways that you can pick K items from a set of N items. Now, think about how you might pick K items. The selection could include the first item or not. The total number of ways you could pick K items equals the sum of the numbers of ways the selection could include the first item, plus the number of ways it could not include that item.
Suppose the selection includes the first item. If this is the case, you still need to pick K – 1 items from the remaining N – 1 items to make a full selection. The number of ways to pick K – 1 items from the remaining N – 1 items is the following:
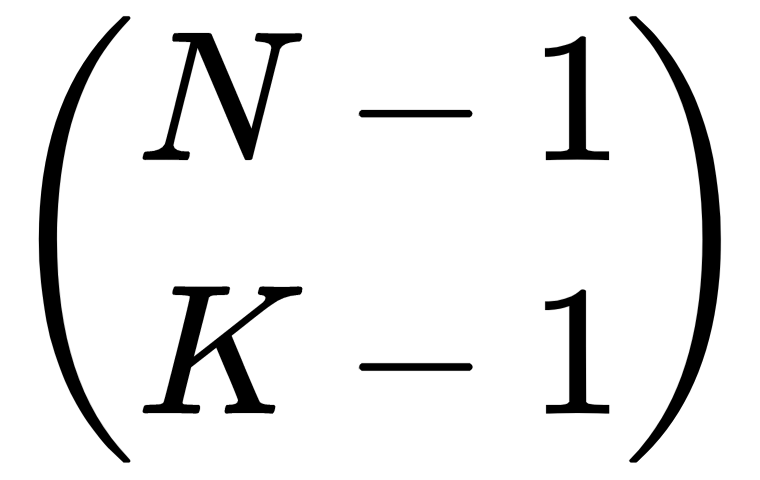
Now, suppose the selection does not include the first item. In that case, you still need to pick K items from the remaining N – 1 items to make a full selection. The number of ways to pick K items out of N – 1 items is as follows:
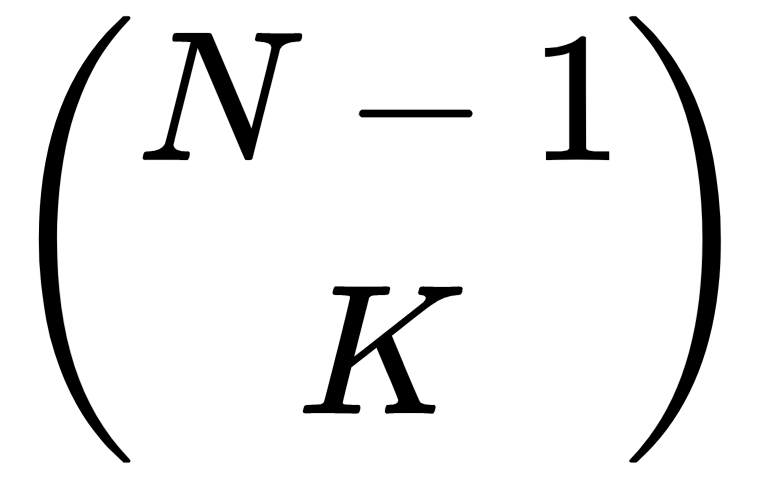
That means the total number of ways you can pick K items from N items is given by the following formula:
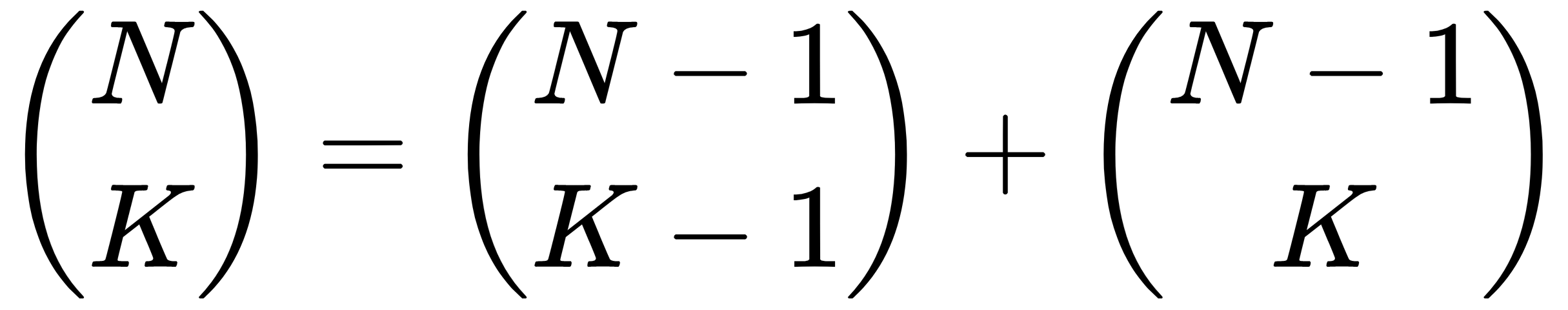
This formula leads to the following recursive method for calculating binomial coefficients:
// Use recursion to find the binomial coefficient.
private long RecursiveNchooseK(int n, int k)
{
checked
{
if (k == 1) return n;
if (k == n) return 1;
return
RecursiveNchooseK(n - 1, k) +
RecursiveNchooseK(n - 1, k - 1);
}
}If k is 1, the method returns n because there are n ways to pick 1 value from a set of n values.
Next, if k equals n, the method returns 1 because there is one way to pick n values from a set of n values, namely, pick every item.
If k is neither 1 nor n, the method calls itself recursively to calculate the following:
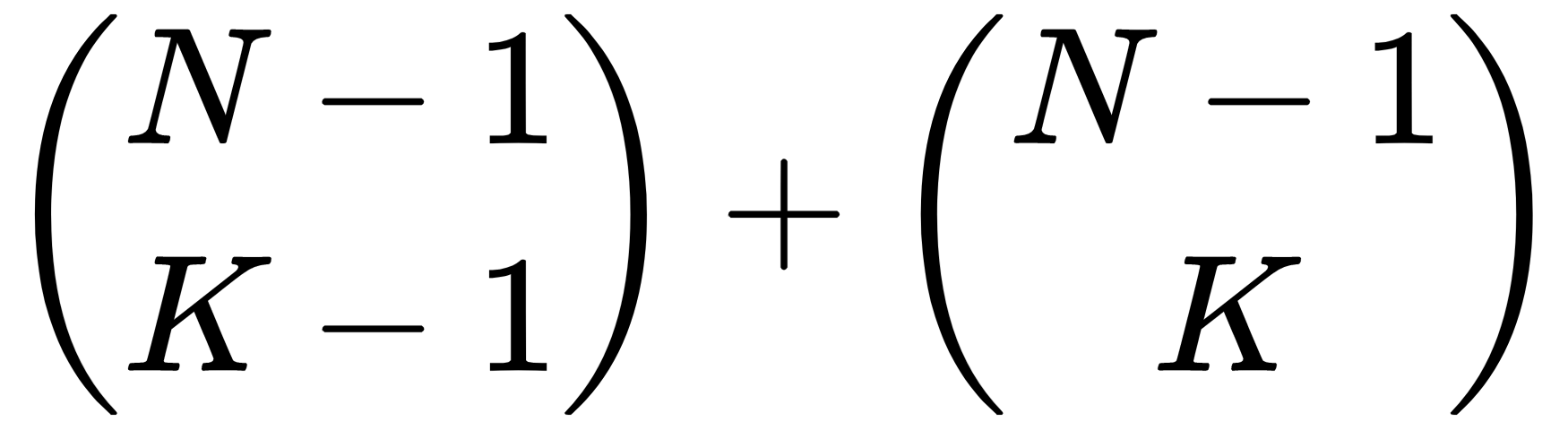
The method then returns the result.
This method works and does not have a problem with integer overflow, so it can calculate

. Unfortunately, it has a problem similar to the one encountered by the straightforward method to calculate Fibonacci numbers recursively: it calculates too many intermediate values.
To calculate a value, the method calculates two smaller values. Calculating those values requires the method to calculate two other smaller values, and so forth. If you draw a tree showing the calculations similar to the tree shown earlier for Fibonacci numbers, you get a binary tree with height and business depending on N and K. In the worst case scenario, the tree contains a huge number of nodes, so the calculation takes an extremely long time. The problem statement asked you to calculate
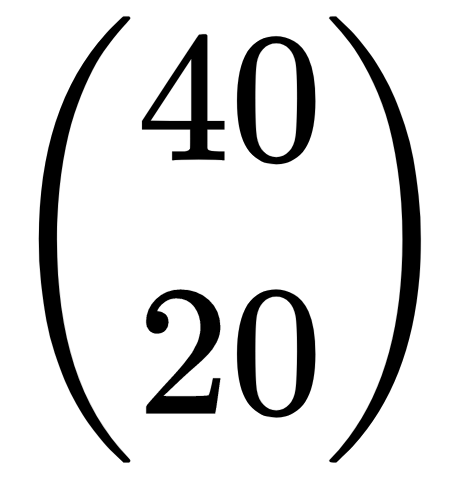
, and this method is just not up to the challenge.
Solution 5.Fibonacci Numbers, described several methods for avoiding this sort of problem with Fibonacci numbers. Unfortunately, a table or cache won't work in this case because the recursive binomial coefficient method calculates a huge number of values but no duplicates.
The other Fibonacci solution takes a bottom-up approach, using smaller values to calculate larger ones. That approach also works here, although it's a bit hard to understand.
To use this approach, consider the original binomial coefficient formula again and rearrange it as follows:
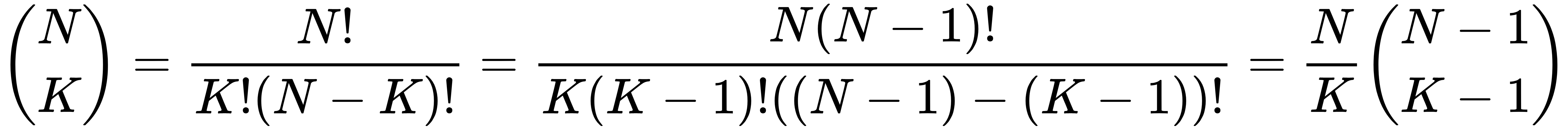
This lets you write
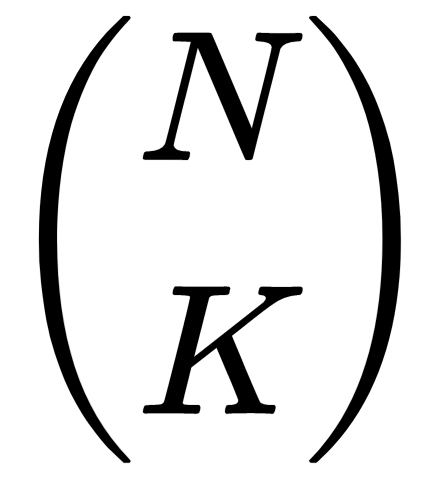
as the simple fraction N/K times the smaller value
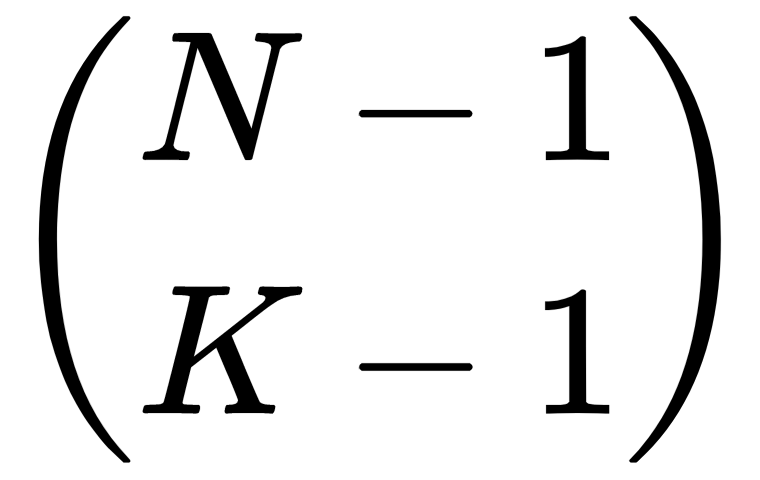
. If you repeat this process, you can rewrite the original value as a product of simple fractions:
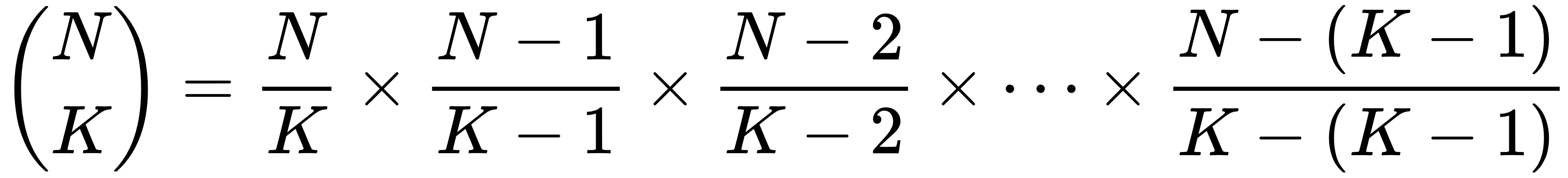
The last term simplifies to (N - (K - 1)) / 1, which has the value N - (K - 1).
Now, if you work from right-to-left, you can calculate each value in this sequence in terms of previous values (to the right).
Because each of the intermediate values is also a binomial coefficient, such as
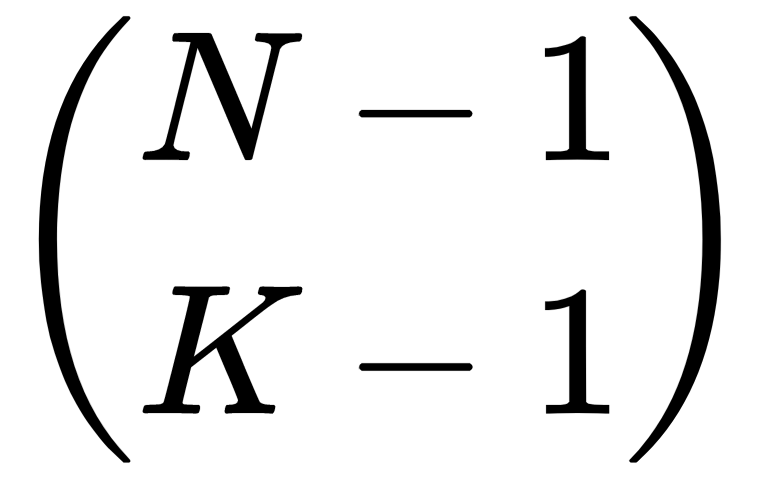
, you know that it must be an integer value. (There cannot be 6.3 ways to pick 20 items from a set of 40.) This means that at each stage of calculation, the numbers must cancel out to give an integer result.
All of this gives the following surprisingly simple method for calculating binomial coefficients:
// Use canceling to find the binomial coefficient
private long CancelingNchooseK(int n, int k)
{
checked
{
long result = 1;
for (int i = 1; i <= k; i++)
{
result *= n - (k - i); result /= i;
}
return result;
}
}This method is fast, only requiring K steps. The numbers also cancel as the calculation progresses, so there's no integer overflow unless the final result is too big. For example,

is just plain huge, no matter how you try to calculate it.
This method can verify the following:
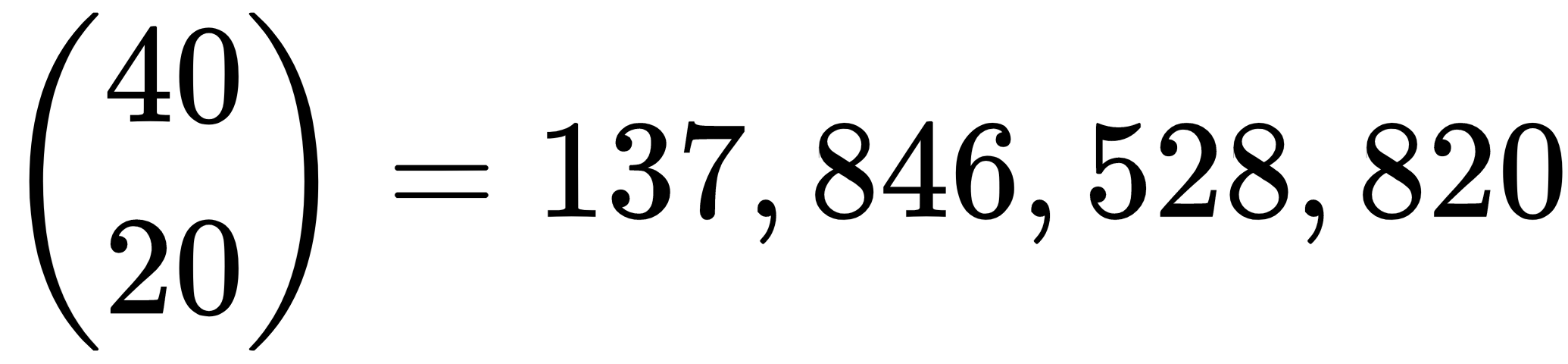
Note
You can use the solution to this problem to verify the number of solutions found for Problem 3. Combinations. That problem asked you to find combinations of K items picked from a total of N items. This problem asks you to calculate the number of those combinations.
Download the BinomialCoefficients example solution to see additional details.
The following method generates the indicated number of rows in Pascal's triangle:
// Make a Pascal's triangle with the desired number of rows.
private List<List<int>> MakePascalsTriangle(int numRows)
{
// Make the result list.
List<List<int>> triangle = new List<List<int>>();
// Make the first row.
List<int> prevRow = new List<int>();
prevRow.Add(1);
triangle.Add(prevRow);
// Make the other rows.
for (int rowNum = 2; rowNum <= numRows; rowNum++)
{
// Make the next row.
List<int> newRow = new List<int>();
newRow.Add(1);
for (int colNum = 2; colNum < rowNum; colNum++)
{
newRow.Add(
prevRow[colNum - 2] +
prevRow[colNum - 1]);
}
newRow.Add(1);
// Prepare for the next row.
triangle.Add(newRow);
prevRow = newRow;
}
return triangle;
}This method creates a result list and then adds the top row of the triangle containing the single value 1.
It then enters a loop to calculate each of the remaining rows from the rows above them in the result list.
Alternatively, you could use one of the methods in Solution 6. Binomial Coefficients, to calculate each of the triangle's binomial coefficients directly.
The following method converts a triangle's entries from a List<List<int>> into a multiline string:
// Convert a Pascal's triangle into a string
private string TriangleToString(List<List<int>> triangle
{
StringBuilder sb = new StringBuilder();
foreach (List<int> row in triangle)
{
sb.AppendLine(
string.Join(" ",
row.ConvertAll(i => i.ToString())));
}
return sb.ToString();
}This method creates a StringBuilder and then loops through the triangle's rows. It uses the ConvertAll LINQ extension method to convert the row's values into strings, uses string.Join to concatenate those strings into a single space-delimited string, and adds the row's space-delimited values to the StringBuilder.
After it processes all of the rows, the method returns the text in the StringBuilder.
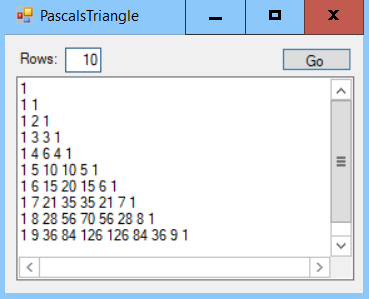
The following screenshot shows the PascalsTriangle example solution, displaying the first 10 rows of Pascal's triangle:
Displaying Pascal's triangle graphically is a bit more challenging. The PascalsTriangleGraphical example solution uses the following code to draw Pascal's triangle:
// The Pascal's triangle.
private List<List<int>> PascalsTriangle = null;
// Draw the triangle on the PictureBox.
private void DrawTriangle(Graphics gr, int cx)
{
gr.Clear(Color.White);
if (PascalsTriangle == null) return;
gr.TextRenderingHint = TextRenderingHint.AntiAliasGridFit;
gr.SmoothingMode = SmoothingMode.AntiAlias;
// The size of an item.
const int wid = 30;
const int hgt = 30;
const int margin = 2;
// Make a StringFormat to center text.
using (StringFormat sf = new StringFormat())
{
sf.Alignment = StringAlignment.Center;
sf.LineAlignment = StringAlignment.Center;
// Make a font to use.
using (Font font = new Font("Segoe", 9))
{
int y = 4;
// Draw each row.
int numRows = PascalsTriangle.Count;
for (int rowNum = 1; rowNum <= numRows; rowNum++)
{
// Start on the left so the row is centered.
int x = cx - rowNum * wid / 2;
// Draw the items in this row.
List<int> row = PascalsTriangle[rowNum - 1];
for (int colNum = 1; colNum <= rowNum; colNum++)
{
Rectangle rect = new Rectangle(
x + margin, y + margin,
wid - 2 * margin, hgt - 2 * margin);
gr.DrawString(row[colNum - 1].ToString(),
font, Brushes.Blue, rect, sf);
gr.DrawEllipse(Pens.Black, rect);
x += wid;
}
y += hgt;
}
}
}
}The PascalsTriangle variable holds the solution found by the previous MakePascalsTriangle method.
The DrawTriangle method first performs some setup chores. It makes a StringFormat object that it can use to center text in a rectangle and creates a font. It then initializes the variable y to indicate the vertical position of the first row.
The method then loops through the triangle's rows. For each row, the method calculates the row's width, divides that by 2, and subtracts the result from the X coordinate of the center of the PictureBox. That gives the X coordinate where the program must start drawing the row in order to center it horizontally.
Next, the code loops through the row to draw its values, updating the variable x after each.
To draw a value, the code makes a rectangle at position (x, y), and with the width and height given by the constants wid and hgt. It offsets the position and dimensions to make a margin between values.
This method draws the value centered inside the rectangle and then uses the same rectangle to draw an ellipse around the value.
The following screenshot shows the PascalsTriangleGraphical program in action:
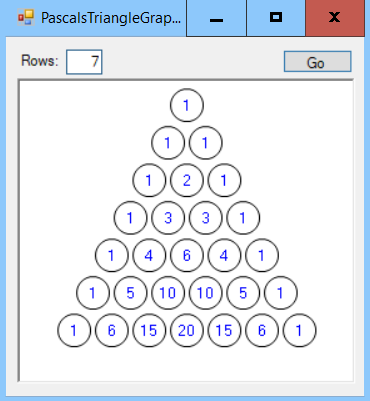
Note
Note that the program doesn't try to adjust the size of the ellipses depending on the length of the values. For example, the 20th row of the triangle contains the value 92,378, which won't fit in the ellipses drawn by the preceding code. Modifying the program to handle larger values would make an interesting exercise, so I encourage you to give it a try.
Download the PascalsTriangle and PascalsTriangleGraphical example solutions to see additional details.
The most obvious way to calculate GCD(A, B) is to simply try all of the values smaller than A and B and see which ones divide both numbers. That method is straightforward and reasonably fast, although it could take a while if A and B are very large. In particular, using this method to find GCD(10370370276, 82962962964) could take a long time.
A faster alternative would be to factor A and B (I'll talk about factoring later in this chapter) and then determine the factors that they have in common.
An even faster alternative was described by Euclid (pronounced yoo-klid) around 300 BC. Because he first described the algorithm, it is called Euclid's algorithm or the Euclidean algorithm.
The idea behind the algorithm is that, if A > B and C evenly divides both A and B, then C must also evenly divide A – B. That leads to the following algorithm:
- Set remainder = A mod B
- If remainder is 0, then B is the GCD
- Otherwise set A = B and B = remainder, and then repeat from step 1
For example, the following steps show the calculation for GCD(180, 48):
- Remainder = 180 % 48 = 36
- A = 48, B = 36
- Remainder = 48 % 36 = 12
- A = 36, B = 12
- Remainder = 36 % 12 = 0
- At this point, the remainder is 0, so the GCD is B, which is 12
This calculation found GCD(180, 48) in only six steps.
The following method uses this algorithm to calculate the GCD:
// Use Euclid's algorithm to find GCD(a, b).
private long GCD(long a, long b)
{
a = Math.Abs(a);
b = Math.Abs(b);
// Pull out remainders.
for (;;)
{
long remainder = a % b;
if (remainder == 0) return b;
a = b;
b = remainder;
};
}This code simply takes the absolute values of its inputs a and b, and then follows Euclid's algorithm.
Note
It's interesting to see what happens if a < b when the algorithm starts. I'll let you work through that on your own.
Download the GCD example solution to see additional details.
Once you know how to calculate GCDs, calculating LCMs is easy. To see why, suppose g = GCD(a, b). Then a = g × A and b = g × B for some integers A and B. In that case, LCM(a, b) is given by g × A × B.
You could divide a and b by g to find A and B, but you don't really need to know A and B. Instead, you can simply calculate LCM(a, b) = a × b/g. If you replace a and b in that equation with g × A and g × B, you get (g × A) × (g × B)/g. Canceling and rearranging a bit gives g × A × B, which is LCM(a, b).
That gives us the following simple method for calculating LCMs:
// Find LCM(a, b).
private long LCM(long a, long b)
{
return a * b / GCD(a, b);
}This method has one drawback. In the mathematical expression, the * and / operators have the same precedence, so the program evaluates them in left-to-right order. That means that it first calculates a * b and then divides that result by g. If a * b is too large, it will cause integer overflow. In particular, if you try to use this method to calculate LCM(1234567000, 7654321000), as required by this problem, the result is -8,996,971,959,702,551, which is clearly incorrect.
You can reduce this problem by making two modifications. First, use the checked keyword to ensure that the program looks for overflow. Second, you can rearrange the calculation to keep the intermediate values as small as possible during the calculation.
The following code shows an improved version of this method:
// Find LCM(a, b).
private long LCM(long a, long b)
{
return checked(a / GCD(a, b) * b);
}
Now, the method first divides a by GCD(a, b). We know that GCD(a, b) divides evenly into a because it is a divisor of a, so a / GCD(a, b) is an integer. (In fact, that value is the value A that I described earlier.) The method then multiplies that intermediate value by b. The result may still cause overflow if the LCM is too big, but at least the method won't overflow during an intermediate calculation.
This version of the method can verify that LCM(1234567000, 7654321000) = 9,449,772,114,007,000.
There are two lessons here. First, as in earlier problems, use the checked keyword if there is a chance that the program might cause integer overflow. This lets the program detect the problem rather than trying to continue with a nonsensical result.
The second lesson is that you can sometimes rearrange calculations to avoid integer overflow.
Download the LCM example solution to see additional details.
One obvious approach for finding multiples of three and five is to loop through the numbers between 3 and the maximum value, check each number to see if it is a multiple of 3 or 5, and add the multiples to get a running total. The following method takes this approach into account:
private long Method1(long max)
{
long total = 0;
checked
{
for (long i = 3; i <= max; i++)
if ((i % 3 == 0) || (i % 5 == 0))
total += i;
}
return total;
}This is straightforward but not very efficient. If the max parameter is large, this method can take a while.
A better approach is to use a variable to keep track of the next multiple of five and then loop through the multiples of 3. If a multiple of 3 is greater than the next multiple of 5, add that multiple to the total and move it to the next multiple of 5. The following method uses this approach:
private long Method2(long max)
{
long total = 0;
checked
{
int next5 = 5;
for (long i = 3; i <= max; i += 3)
{
total += i;
if (i == next5)
{
next5 += 5;
}
else if (i > next5)
{
total += next5;
next5 += 5;
}
}
// Check the final few entries.
for (long i = max; i > max - 3; i--)
{
if (i % 3 == 0) break;
if (i % 5 == 0)
{
total += i;
break;
}
}
}
return total;
}This method is much faster than the first version for two reasons. First, it only considers values that are multiples of three or five. Second, it uses addition to increase the i and next5 values, so it always knows that those values are multiples of three or five, respectively. That means that it doesn't need to use the relatively slow modulus operator % to see if a value is a multiple.
This method is effective, but it's rather complicated. That means it will be harder to understand, debug, and maintain. You can make a simpler version if you think a bit more about the problem.
You could use two loops—one to add up multiples of three and a second one to add up multiples of 5. If you did that, however, multiples of both 3 and 5 such as 15 and 30 would be counted twice. You could then fix the total by using another loop to subtract those duplicated multiples of 15 so they are counted only once.
One of the lessons from Solution 9. Least common multiples, was that the evaluation order can sometimes cause integer overflow and that same lesson applies here. It is possible that adding up the multiples of 3 and then the multiples of 5 could cause an integer overflow. We can avoid that if we subtract the multiples of 15 after adding the multiples of three and before adding the multiples of five, as shown in the following code:
private long Method3(long max)
{
checked
{
long total = 0;
for (long i = 3; i <= max; i += 3) total += i;
for (long i = 15; i <= max; i += 15) total -= i;
for (long i = 5; i <= max; i += 5) total += i;
return total;
}
}This version is about as fast as the preceding version and won't cause integer overflow unless the final total is too big to fit in a long integer, in which case we're stuck anyway. However, we can do even better!
Once again, we need to think about the problem in a new way. The preceding solution adds up the numbers 3 + 6 + 9 + ... That sum equals 3 times the slightly simpler sum 1 + 2 + 3 + ... You can use the following equation to calculate the simpler sum without adding up the numbers individually:
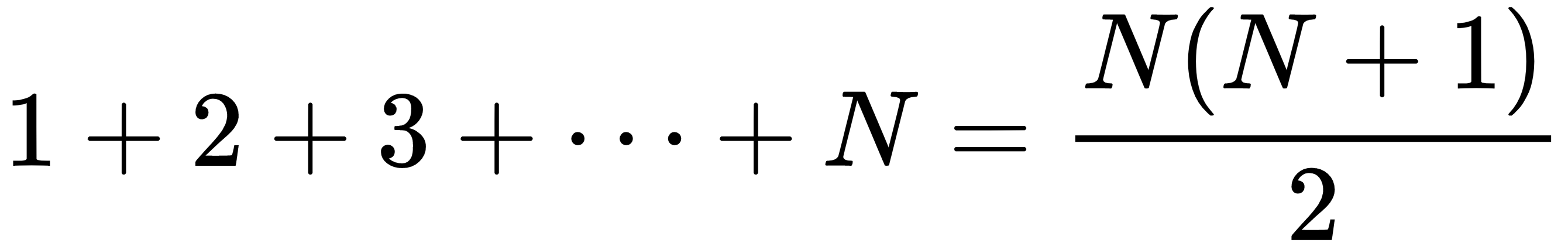
Now, you can use that formula to directly calculate the sums of the multiples of 3, 5, and 15 instead of using loops. The following code demonstrates this method:
private long Method4(long max)
{
checked
{
long num3s = max / 3;
long threes = num3s * (num3s + 1) / 2 * 3;
long num5s = max / 5;
long fives = num5s * (num5s + 1) / 2 * 5;
long num15s = max / 15;
long fifteens = num15s * (num15s + 1) / 2 * 15;
return threes - fifteens + fives;
}
}This code first calculates max / 3 to get the largest multiple of three less than or equal to max. For example, if max is 25, then max / 3 = 8. (Keep in mind that this is integer division, so the fractional part is discarded.) The code uses the formula to calculate 1 + 2 + ... + 8 and multiplies the result by 3 to get the total 3 + 6 + ... + 24.
The method repeats those steps to calculate the sums of the multiples of 5 and 15 and combines them to get the final result.
This version of the method performs only a few calculations instead of using long loops, so it is much faster than any of the previous solutions.
The following screenshot shows the example solution adding multiples between 0 and 100 million:
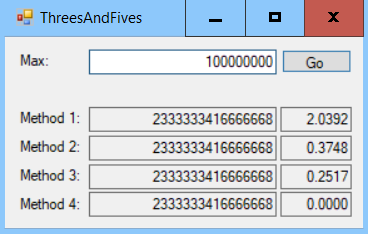
The first solution took around 2 seconds. The second and third approaches took around 0.38 and 0.25 seconds, respectively. Those times are reasonably comparable. The final solution took so little time that it is virtually instantaneous. Unlike the other solutions, the final approach does not depend on the maximum value, so it takes no longer to add up a few values or millions of values.
One lesson to be learned here is that you should (as usual) use the checked keyword to look for integer overflow. You should also look at a problem from multiple directions to see if you can restate the problem in a simpler form. In this case, we converted a long, slow loop into a series of faster loops, and then we converted those loops into some simple calculations.
Download the SumsOfMultiples example solution to see additional details.
One simple way to determine whether a number N is prime is to loop through all of the integers between 2 and N – 1 and use the modulus operator % to see if any of them divide the number evenly. There are a couple of ways that you can improve this approach.
First, note that once you check a potential divisor, you don't need to check any multiples of that divisor. For example, if 2 doesn't divide evenly into N, then 4, 6, 8, and other multiples of 2 also cannot divide evenly into N. To make the basic approach faster, you can test the divisor 2 separately and then make the loop consider only odd numbers.
You can also improve this method by changing the loop's upper limit. The original method considers values between 2 and N – 1, but you can change the upper limit to
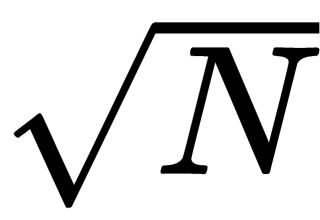
. To see why that works, suppose N has a factor A where A >
, so the loop won't find A. In that case, N = A × B for some value, B. If A >
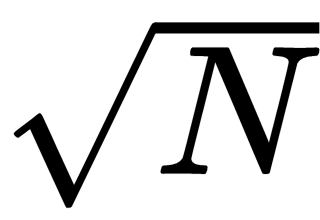
, then B must be less than
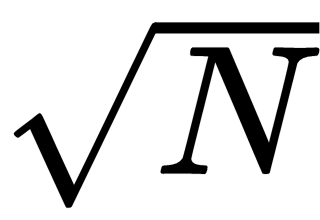
, so the loop won't find A, but it will find B.
Making the loop consider only odd numbers and making the loop end at
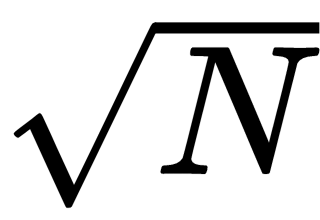
gives the following method for determining whether a number is prime:
// Return true if the number is prime.
private bool IsPrime(long number)
{
// Handle 2 separately.
if (number == 2) return true;
if (number % 2 == 0) return false;
// See if the number is divisible by odd values up to Sqrt(number).
long sqrt = (long)Math.Sqrt(number);
for (long i = 3; i <= sqrt; i += 2)
if (number % i == 0) return false;
// If we get here, the number is prime.
return true;
}Note that this method only uses numbers that are smaller than N, so it cannot cause an integer overflow.
Download the PrimalityTesting example solution to see additional details.
The obvious approach is to loop through all of the values in the array and call the IsPrime method, described in the previous solution, to see which values are prime. The following method uses this approach:
// Use the IsPrime method to make a table of prime numbers.
private bool[] MakePrimesTable(int max)
{
// Make the array and mark 2 and odd numbers greater than 1 as
// prime.
bool[] isPrime = new bool[max + 1];
isPrime[2] = true;
for (int i = 3; i <= max; i += 2) isPrime[i] = IsPrime(i);
return isPrime;
}This method allocates an array big enough to hold all of the desired values. It then sets isPrime[2] = true because 2 is prime. It leaves the other even values alone because they are set to false when the array is allocated.
The code then loops through the array's odd numbers and calls the IsPrime method, described in the preceding solution, to set each value's array entry. The method finishes by returning the array.
This method is easy to understand, but it's fairly slow. The IsPrime method loops over many values, so putting calls to IsPrime inside another loop makes the method slow.
While describing the IsPrime method in the preceding solution, I mentioned that we could skip multiples of 2 because, if 2 does not divide evenly into a number, then multiples of 2 cannot either.
We can generalize this rule to make building the table of primes faster. After we consider a prime number p, we know that all multiples of p greater than p are non-prime. For example, we know that 2 is prime, so we can conclude that the multiples 2 × 2, 2 × 3, 2 × 4, ... are not prime.
This leads to the Sieve of Eratosthenes, named after the Greek mathematician Eratosthenes of Cyrene, who discovered it. The idea is to start with a table that contains an entry for all of the numbers of interest. Initially, we assume that all of the numbers are prime.
Now, you start at entry 2 and cross out the later multiples of 2 to indicate that they are not prime.
You then move from 2 to the next entry that is still marked prime, in this case 3, and you cross out the later multiples of 3.
Again, you move to the next numbers that is still marked as prime. The value 4 was crossed out when we considered multiples of 2. The next prime number is 5, so you cross out later multiples of 5.
You continue these steps, finding the next prime number and crossing out its later multiples, until you have considered all of the values in the table.
The following code implements this method:
// Make a sieve of Eratosthenes.
private bool[] MakeSieveOfEratosthenes(int max)
{
// Make the array and mark 2 and odd numbers greater than 1 as
// prime.
bool[] isPrime = new bool[max + 1];
isPrime[2] = true;
for (int i = 3; i <= max; i += 2) isPrime[i] = true;
// Cross out multiples of odd primes.
for (int i = 3; i <= max; i++)
{
// See if i is prime.
if (isPrime[i])
{
// Knock out multiples of i.
for (int j = i * 2; j <= max; j += i)
isPrime[j] = false;
}
}
return isPrime;
}
When the method allocates the isPrime array, its entries are initially false. The code marks 2 and the odd numbers as prime, and leaves the remaining even numbers flagged as non-prime.
Next, the code loops through the odd numbers. If a number is marked as prime, the code marks all of its later multiples as non-prime.
This method is much faster than the previous one, which checked each number individually to see if it was prime. The Sieve of Eratosthenes remained state-of-the art for almost 2,000 years until the 18th century when Euler (pronounced oiler) discovered a major improvement. Euler noticed that you don't need to cross out all multiples of a prime, p; you only need to cross out multiples p × q where q ≥ p and q is also prime.
For example, when you're crossing out multiples of 7, you cross out 7 × 7, 11 × 7, 13 × 7, 17 × 7, and so forth. You already crossed out multiples of smaller primes when you considered them. For example, you crossed out 5 × 7 when you considered multiples of 5.
Also, you already considered non-prime numbers, q, that are bigger than 7 when you considered the prime factors of those numbers. For example, you crossed out 21 × 7 when you examined multiples of 3.
That's the basic improvement on Eratosthenes' algorithm. When you consider a new prime p, you cross out p times larger values in the table that are still marked as prime.
There's one implementation trick here. When you consider multiples of p, you cannot immediately cross them out because you may need them later. For example, suppose you're considering multiples of 3. You start by crossing out the value 3 × 3 = 9.
The next values of q that you consider are 5 and 7. They're still marked as prime, so you cross out 3 × 5 = 15 and 3 × 7 = 21.
The next value of q that you consider is 9. Unfortunately you just crossed out 9 a little while ago, so it's no longer marked as prime. That means you won't cross out 3 × 9 = 27, and that's a problem because 27 is not prime.
The way Euler handled this was to initially mark multiples of 3 as ready for crossing out, but to leave them in the table until after marking all of the multiples of 3. In this example, the program would mark 9 but not cross it out until after it checked the other multiples including 3 × 9 = 27.
The solution shown here handles this problem in a different way by examining multiples of 3 in decreasing order that lets it consider consider 3 × 9 before it considers 3 × 3.
The following code shows the method that builds Euler's sieve:
// Make Euler's sieve.
private bool[] MakeEulersSieve(int max)
{
// Make the array and mark 2 and odd numbers greater than 1 as
// prime.
bool[] isPrime = new bool[max + 1];
isPrime[2] = true;
for (int i = 3; i <= max; i += 2) isPrime[i] = true;
// Cross out multiples of the primes.
for (int i = 3; i <= max; i += 2)
{
// See if i is prime.
if (isPrime[i])
{
// Knock out multiples of p.
int maxQ = max / i;
if (maxQ % 2 == 0) maxQ--; // Make it odd.
for (int q = maxQ; q >= i; q -= 2)
{
// Only use q if it is prime.
if (isPrime[q]) isPrime[i * q] = false;
}
}
}
return isPrime;
}This method allocates the isPrime array and marks 2 and the odd numbers as prime. It then loops through the odd numbers, looking for those that are still marked as prime.
When it finds a number p that is marked as prime, the code sets the maxQ variable to the largest odd number, q, where p × q is within the table. For example, suppose i is 19 and max is 1,000. Then the program sets maxQ to 51 because 19 × 51 = 969 is the largest odd multiple of 19 that is less than or equal to 1,000.
The program then loops backwards over odd numbers between maxQ and i. If one of those numbers is still marked as prime, the program crosses out that value times i.
The following screenshot shows the example program building prime tables program by using the three methods described here. The Sieve of Eratosthenes is muchfasterthan the brute-force approach, but Euler's sieve is even faster:
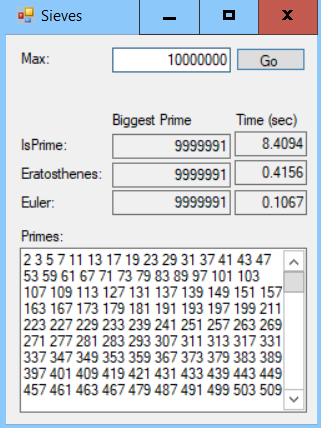
Download the PrimesTable example solution to see additional details.
The most obvious approach to prime factoring a number is to loop through values less than that number and see if they divide into that number evenly. Each time you find such a factor, you divide it from the number. You continue this process until the modified number equals 1.
The following method uses this approach:
// Divide by smaller values up the the square root of the value.
private List<long> Method1(long number)
{
checked
{
List<long> factors = new List<long>();
// Pull out 2s.
while (number % 2 == 0)
{
factors.Add(2);
number /= 2;
}
// Pull out odd factors.
long limit = (long)Math.Sqrt(number);
for (long factor = 3; factor <= limit; factor += 2)
{
while (number % factor == 0)
{
factors.Add(factor);
number /= factor;
limit = (long)Math.Sqrt(number);
}
}
// Add the leftover.
if (number != 1) factors.Add(number);
return factors;
}
}The method first uses a loop to pull out factors of 2. As long as the number is divisible by 2, the method adds 2 to the list of factors and divides the number by 2.
Next, the code loops over odd values between 3 and the square root of the number. It doesn't need to consider values greater than the number's square root because, if there is a factor p greater than the square root, then there is another factor, q, less than the square root so that p × q equals the number.
When it finds a factor that divides into the number evenly, the code adds it to the factor list, divides the number by the factor, and then updates the square root for the updated number.
When it finishes examining possible factors, the number is either 1, in which case we have found all of the factors, or it is prime. If the number is prime, the code adds it to the factor list.
This method is reasonably efficient if you only want to factor a single value. If you need to factor a large number of values, however, then you can improve performance by making a pre-calculated table of prime numbers.
The preceding method considers all odd numbers as possible factors, but it really only needs to consider prime numbers as factors. If you build Euler's sieve as was described in the preceding solution, then you can use it to decide which numbers might be factors.
The PrimeFactors example solution uses the methods described in the preceding solution to build Euler's sieve. It then uses the following code snippet to convert the sieve into a list containing the prime numbers:
// Convert the sieve into a list of primes.
Primes = new List<long>();
Primes.Add(2);
for (int i = 3; i <= max; i += 2)
if (!isComposite[i]) Primes.Add(i);This code creates a list to hold the prime numbers. It then scans through the sieve stored in the isComposite array, adding the primes to the list.
The following method uses the list of prime numbers to factor a value:
// Use a pre-made sieve of primes up to MaxNumber.
// Update the limit when we find a prime.
private List<long> Method2(long number)
{
checked
{
List<long> factors = new List<long>();
// Pull out primes.
long limit = (long)Math.Sqrt(number);
foreach (long prime in Primes)
{
while (number % prime == 0)
{
factors.Add(prime);
number /= prime;
limit = (long)Math.Sqrt(number);
}
if (prime > limit) break;
}
// Add the leftover.
if (number != 1) factors.Add(number);
return factors;
}
}This method is similar to the earlier one, except it only considers prime numbers when looking for factors. It sets limit to the square root of the number. It then loops through the precomputed primes list. While a prime evenly divides into the number, the code adds the prime to the factor list, divides the number by the prime, and then updates the limit.
If the prime that the method is considering is greater than the limit, the code breaks out of its loop.
Finally, if the number has not been reduced to 1 by the time the loop ends, the code adds it to the factor list as before.
The following screenshot shows the PrimeFactors example solution factoring the number 12,345,678,901,234:
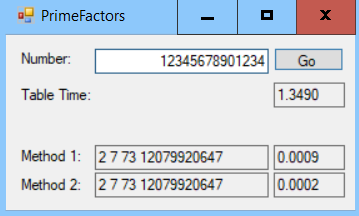
When you enter a value and click Go, the program uses the two methods described earlier to factor the number. In the preceding screenshot, you can see that the first method took around 0.0009 seconds and the second method too around 0.0002 seconds when using the second method. The second method is considerably faster, although the absolute times are minuscule, so it would only be worth using the second approach if you needed to factor a lot of values. When it started, the program took 1.35 seconds to build a primes list containing numbers up to the square root of 1 × 1015. It can use that list to factor numbers up to 1 × 1015.
Download the PrimeFactors example solution to see additional details.
One obvious way to find a number's unique prime factors is to find all of its prime factors and then remove duplicates. That would be relatively straightforward and fast.
An alternative strategy would be to modify the code that factors numbers so that it only saves one copy of each prime factor. The following method takes this approach:
// Find a number's unique prime factors.
private List<long> FindUniquePrimeFactors(long number)
{
checked
{
List<long> factors = new List<long>();
// Pull out 2s.
if (number % 2 == 0)
{
factors.Add(2);
while (number % 2 == 0) number /= 2;
}
// Pull out odd factors.
long limit = (long)Math.Sqrt(number);
for (long factor = 3; factor <= limit; factor += 2)
{
if (number % factor == 0)
{
factors.Add(factor);
while (number % factor == 0)
{
number /= factor;
limit = (long)Math.Sqrt(number);
}
}
}
// Add the leftover.
if (number != 1) factors.Add(number);
return factors;
}
}This method is similar to the one used in the preceding solution, except it only keeps one copy of each prime factor.
Like the preceding solution, you can make this solution faster if you build a prefilled list of prime numbers to use when searching for factors.
The lesson to be learned here is that you can sometimes solve a new problem by reusing an existing solution, but sometimes it's worth modifying the existing solution to make the new approach simpler.
Download the UniquePrimeFactors example solution to see additional details.
This is a relatively straightforward problem. Simply create an Euler's sieve and then search it for primes that have the right spacing and number. The following method takes this approach:
// Look for groups of primes.
private List<List<int>> FindPrimeGroups(int max,
int spacing, int number, bool[] isPrime)
{
List<List<int>> results = new List<List<int>>();
// Treat 2 specially.
List<int> group = GroupAt(2, max, spacing, number, isPrime);
if (group != null) results.Add(group);
// Check odd primes to see if a group starts there.
for (int p = 3; p <= max; p += 2)
{
group = GroupAt(p, max, spacing, number, isPrime);
if (group != null) results.Add(group);
}
// Return the groups we found.
return results;
}This method's final parameter, isPrime, is an Euler's sieve containing primes up to the maximum value, max.
The method calls the GroupAt method, which will be described shortly, to see if there is a group of primes with the desired spacing and number starting with the value 2. Like many programs that deal with primes, this one treats 2 specially because it is the only even prime number, and that lets the code look only at odd values later.
After considering 2, the method loops over odd values up to max and uses the GroupAt method to see if any of them begin the right kind of prime groups.
The following code shows the GroupAt method:
// Determine whether the indicated number begins a group.
// Return the group or null if there is no group here.
private List<int> GroupAt(int startIndex, int max,
int spacing, int number, bool[] isPrime)
{
// See if there is room for a group.
if (startIndex + (number - 1) * spacing > max)
return null;
// If there is no group here, return null.
for (int i = 0; i < number; i++)
if (!isPrime[startIndex + i * spacing])
return null;
// We found a group. Return it.
List<int> result = new List<int>();
for (int i = 0; i < number; i++)
result.Add(startIndex + i * spacing);
return result;
}This method first checks to see if there is room before the max value for the desired primes. For example, if max is 100 and we're looking for a group of two primes spaced four apart, then there's no need to check for a group starting at position 97 because 97 + 4 = 101 is greater than max. (This check is important because it prevents the program from trying to access isPrime[101], which would cause an IndexOutOfRangeException.)
The method then loops through the desired number of values with the indicated spacing. For example, if spacing is 6, number is 3, and startIndex is 17, then the program would examine the values 17, 23, and 29.
If the isPrime array shows that any of the values are not prime, the method returns null.
If all of the examined values are prime, the method returns them in a list.
If you experiment with the program for a while, you'll notice something interesting about the values. If you look for two primes with any even spacing (as in {p, p + 2}, {p, p + 4}, {p, p + 6}, and so on), you'll find lots of results. However, if you look for three or four primes (as in {p, p + 2, p + 4} or {p, p + 6, p + 12}), you'll only get interesting results if the spacing is a multiple of three.
To see why, suppose we're looking for three primes and the spacing is 2, so we're looking for a set {p, p + 2, p + 4}. In that case, one of those three values must be a multiple of three, so that value cannot be prime. (Unless the first value is 3, as in {3, 5, 7} or {3, 7, 11}.) This means that you won't find groups of three or more with a spacing of 2.
The same argument works if the spacing is some other value that is not a multiple of three.
In contrast, if the spacing is a multiple of three, then either all of the values are multiples of three, or none of them are. If none of them are multiples of three, then they mightall be prime.
Download the PrimeTuples example solution to see additional details.
An obvious method for finding the proper divisors of the number N is to consider all of the values between 1 and N/2 and see which ones divide into N evenly. The following method takes this approach:
// Examine values between 1 and number / 2.
private List<long> Method1(long number)
{
checked
{
List<long> divisors = new List<long>();
long limit = number / 2;
for (long factor = 1; factor <= limit; factor++)
{
if (number % factor == 0)
divisors.Add(factor);
}
return divisors;
}
}This method is straightforward, but it can be slow if the number is large. For example, if the number is 10 billion, then the method must examine 5 billion values.
In contrast, the prime factoring algorithms described earlier in this chapter only needed to examine values up to the square root of the number. For example, if the number is 10 billion, then its square root is 100,000, which is 50,000 times smaller than the 5 billion numbers examined by the preceding code.
The reason why prime factoring code only needs to examine values up to the square root of the number is that each larger factor would be paired with a smaller factor. If the number N = p × q and p >
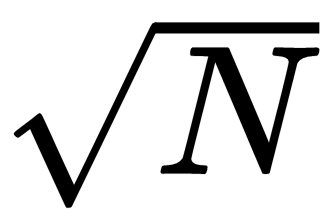
, then q <
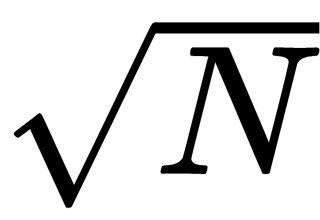
. If we only examine values up to
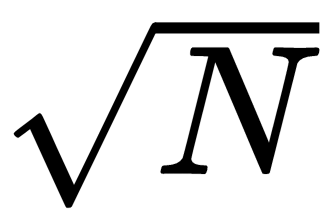
, we won't find p, but we will find q.
We can use similar logic when we look for divisors. Continuing from the previous example, if we only examine values up to
, we still won't find p. However, when we find q, we can use it to calculate p because N = p × q. That gives us the following method for finding divisors:
// Examine values between 2 and Sqrt(number).
private List<long> GetProperDivisors(long number)
{
checked
{
List<long> divisors = new List<long>();
divisors.Add(1);
long limit = (long)Math.Sqrt(number);
for (long divisor = 2; divisor <= limit; divisor++)
{
if (number % divisor == 0)
{
divisors.Add(divisor);
long divisor2 = number / divisor;
if (divisor != divisor2) divisors.Add(divisor2);
}
}
divisors.Sort();
return divisors;
}
}This method creates the divisors list and adds 1 to it. It then loops over values between 2 and the square root of the number.
If a value divides evenly into the number, then it is a divisor, so the method adds it to the divisors list.
The number divided by the divisor is also a divisor, so the method also adds it to the list. The only trick here is that the two divisors might be the same if the number is a perfect square. For example, if the number is 49, then the method will find the two divisors 7 and 49/7 = 7. The method checks that the second divisor is different from the first before adding it to the list.
Because the method adds small and large divisors in pairs, the final list is not sorted, so the method sorts the list before returning it.
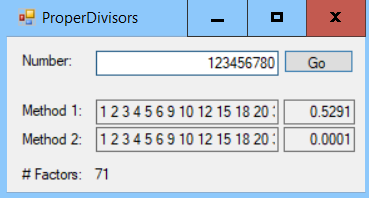
The following screenshot shows the ProperDivisors example solution finding the 71 proper divisors of the number 123,456,780. You can see that the second method is much faster than the first:
The trick to this solution was to think about the earlier technique used by the factoring algorithms and then find a way to apply a similar technique to this problem. Examining values only up to the square root of the number saved a huge amount of time.
Download the ProperDivisors example solution to see additional details.
The obvious approach to this problem is to examine each pair of values between 1 and the maximum and see if the sums of their proper divisors equal each other. There are two problems with this method.
First, there are a lot of pairs of values. If the maximum number is 100,000, then there are 100,000 numbers that can be paired with 99,999 other numbers, making a total of 100,000 × 99,999 = 9,999,900,000, or almost 10 billion pairs to consider.
The second problem is that this technique would recalculate the sum of each value's divisors every time it considered that value. For 100,000 numbers, that means finding and adding divisors almost 20 billion times, once for both values in every pair.
To solve the first problem, you can change the question slightly. Instead of asking whether a pair is amicable, you could ask, for a given value, what other value would be its pair if it has one. For example, when you consider the value 123, you would add its divisors {1, 3, 41} to get 1 + 3 + 41 = 45. You would then examine the value 45 and add that number's divisors {1, 3, 5, 9, 15} to get 1 + 3 + 5 + 9 + 15 = 33. This result, 33, is not the original value, 123, so the two numbers 123 and 45 are not amicable.
This greatly reduces the number of calculations we need to make. Instead of examining almost 10 billion pairs, we only examine 100,000 values and their potential pairs, making this around 200,000 calculations instead of 20 billion.
We can even reduce the second problem somewhat by pre-calculating each number's sum of divisors. We know that we will need to calculate every value's sum at least once, so we won't be performing any extra calculations by pre-calculating those values. That will also allow us to avoid calculating the sum for the second value in each potential pair, so we save roughly half of those calculations.
These two enhancements give us the following method for finding amicable pairs:
// Find amicable numbers <= max.
private List<List<long>> FindAmicablePairs(long max)
{
// Get the array of sums.
long[] sums = GetSumsOfDivisors(max);
// Look for pairs.
List<List<long>> pairs = new List<List<long>>();
for (int value = 1; value <= max; value++)
{
long sum = sums[value];
if ((sum > value) && (sum <= max) && (sums[sum] == value))
{
List<long> pair = new List<long>();
pair.Add(value);
pair.Add(sums[value]);
pairs.Add(pair);
}
}
return pairs;
}The method first calls the GetSumsOfDivisors method, which is described shortly, to build an array of every value's sum of divisors. It then loops through the values between 1 and the maximum number. For each value, the code looks up the value's sum of divisors to find its potential pair. It then compares the pair's sum with the current value. If the two match, then this is an amicable pair.
The code performs two other tests before it accepts the pair. First, it checks that the second value is greater than the original value. This prevents the code from deciding that a number is its own pair. (The definition of amicable numbers says that they are two different numbers.)
This test also ensures that we find each pair only once. For example, the program won't find the pair {220, 284} and then later find {284, 220}.
The second test also ensures that the second number in the potential pair is no greater than the maximum value. This guarantees that it is small enough to lie within the sums array, so we can look at its sum without causing an IndexOutOfRange exception.
The following code shows the GetSumsOfDivisors method:
// Calculate the sums of the divisors of numbers between 1 and max.
private long[] GetSumsOfDivisors(long max)
{
// Make room for the sums.
long[] sums = new long[max + 1];
// Fill in the sums.
for (long i = 1; i <= max; i++)
sums[i] = GetProperDivisors(i).Sum();
// Return the result.
return sums;
}This method creates an array to hold the sums and then loops through the values. It calls the GetProperDivisors method (which was used in the previous solution) for each value, adds the divisors, and saves the result in the sums array.
This technique is fast enough that the program can examine the first one million numbers for amicable pairs in just a few seconds. The two tricks here are to invert the problem so that we only need to examine the numbers once instead of looking at all of the pairs of numbers, and storing pre-calculated values so that we don't need to calculate them multiple times.
Download the AmicableNumbers example solution to see additional details.
You can modify the preceding solution to find perfect numbers. Because you only need to calculate the sum of each value's divisors once, there's no need to pre-calculate those values and store them in an array. That wouldn't cost you much time, but it would use up a bunch of unnecessary memory.
The following code shows a method that finds perfect numbers:
// Find perfect numbers <= max.
private List<long> FindPerfectNumbers(long max)
{
// Look for perfect numbers.
List<long> values = new List<long>();
for (int value = 1; value <= max; value++)
{
long sum = GetProperDivisors(value).Sum();
if (value == sum) values.Add(value);
}
return values;
}This method loops through the values that are less than the maximum. For each value, it calls the GetProperDivisors method, which is used in the previous solution, and calls Sum to add the divisors. If the sum equals the original number, the code adds the number to its list of perfect numbers.
Download the PerfectNumbers example solution to see additional details.
The obvious approach to this problem is to loop through the candidate numbers, convert each into a string, pull apart its digits, raise the digits to the correct power, and see if they add up to the original number.
The following method loops through values up to the desired maximum to build a list of Armstrong numbers:
// Look for Armstrong numbers <= max.
private List<long> FindArmstrongNumbers(long max)
{
List<long> values = new List<long>();
for (long i = 1; i <= max; i++)
if (IsArmstrong(i)) values.Add(i);
return values;
}
This method calls the following IsArmstrong method to see if a value is an Armstrong number:
// Return true if this is an Armstrong number.
private bool IsArmstrong(long number)
{
// Get the number's digits.
long copy = number;
List<long> digits = new List<long>();
while (copy > 0L)
{
digits.Add(copy % 10L);
copy = copy / 10L;
}
// Add the digits' powers.
long total = 0;
long numDigits = digits.Count;
foreach (long digit in digits)
total += (long)Math.Pow(digit, numDigits);
return (total == number);
}The only non-obvious pieces in this method are the two statements that calculate the digit and update the copy of the number. The calculation copy % 10L returns the number's least significant digit. For example, 417 % 10L returns 7.
The calculation copy / 10L returns the number with its least significant digit removed. For example, 417 % 10L returns 41.
Download the ArmstrongNumbers example solution to see additional details.