Our modules are interdependent, so we are facing issues, such as the reusability of code and unresolved bugs due to changes in one module. These are deployment challenges. To tackle these issues, let's segregate our application in such a way that we will be able to divide modules into submodules. We can divide our Order module so that it will implement the interface, and this can be initiated from the constructor.
Dependency injection (DI) is a design pattern and provides a technique so that you can make a class independent of its dependencies. It can be achieved by decoupling an object from its creation.
Here is a short code snippet that shows how we can apply this to our existing monolithic application. The following code example shows our Order class, where we use constructor injection:
using System;
using System.Collections.Generic;
using FlixOne.BookStore.Models;
namespace FlixOne.BookStore.Common
{
public class Order : IOrder
{
private readonly IOrderRepository _orderRepository;
public Order() => _orderRepository = new OrderRepository();
public Order(IOrderRepository orderRepository) => _orderRepository = orderRepository;
public IEnumerable<OrderModel> Get() => _orderRepository.GetList();
public OrderModel GetBy(Guid orderId) => _orderRepository.Get(orderId);
}
}
Inversion of control, or IoC, is the way in which objects do not create other objects on whom they rely to do their work.
In the previous code snippet, we abstracted our Order module in such a way that it could use the IOrder interface. Afterward, our Order class implements the IOrder interface, and with the use of inversion of control, we create an object, as this is resolved automatically with the help of inversion of control.
Furthermore, the code snippet for IOrderRepository is as follows:
using FlixOne.BookStore.Models;
using System;
using System.Collections.Generic;
namespace FlixOne.BookStore.Common
{
public interface IOrderRepository
{
IEnumerable<OrderModel> GetList();
OrderModel Get(Guid orderId);
}
}
We have the following code snippet for OrderRepository, which implements the IOrderRepository interface:
using System;
using System.Collections.Generic;
using System.Linq;
using FlixOne.BookStore.Models;
namespace FlixOne.BookStore.Common
{
public class OrderRepository : IOrderRepository
{
public IEnumerable<OrderModel> GetList() => DummyData();
public OrderModel Get(Guid orderId) => DummyData().FirstOrDefault(x => x.OrderId == orderId);
}
}
In the preceding code snippet, we have a method called DummyData(), which is used to create Order data for our sample code.
The following is a code snippet showing the DummyData() method:
private IEnumerable<OrderModel> DummyData()
{
return new List<OrderModel>
{
new OrderModel
{
OrderId = new Guid("61d529f5-a9fd-420f-84a9-
ab86f3eaf8ad"),
OrderDate = DateTime.Now,
OrderStatus = "In Transit"
},
...
};
}
Here, we are trying to showcase how our Order module gets abstracted. In the previous code snippet, we returned default values (using sample data) for our order just to demonstrate the solution to the actual problem.
Finally, our presentation layer (the MVC controller) will use the available methods, as shown in the following code snippet:
using FlixOne.BookStore.Common;
using System;
using System.Web.Mvc;
namespace FlixOne.BookStore.Controllers
{
public class OrderController : Controller
{
private readonly IOrder _order;
public OrderController() => _order = new Order();
public OrderController(IOrder order) => _order = order;
// GET: Order
public ActionResult Index() => View(_order.Get());
// GET: Order/Details/5
public ActionResult Details(string id)
{
var orderId = Guid.Parse(id);
var orderModel = _order.GetBy(orderId);
return View(orderModel);
}
}
}
The following diagram is a class diagram that depicts how our interfaces and classes are associated with each other and how they expose their methods, properties, and so on:
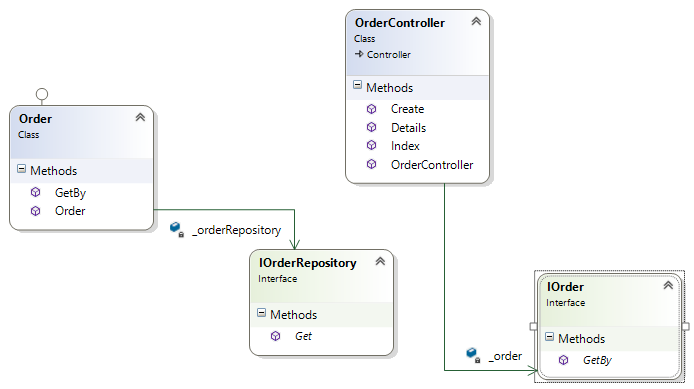
Here, we again used constructor injection where IOrder passed and got the Order class initialized. Consequently, all the methods are available within our controller.
Getting this far means we have overcome a few problems, including the following:
- Reduced module dependency: With the introduction of IOrder in our application, we have reduced the interdependency of the Order module. This way, if we are required to add or remove anything to or from this module, then other modules will not be affected, as IOrder is only implemented by the Order module. Let's say we want to make an enhancement to our Order module; this would not affect our Stock module. This way, we reduce module interdependency.
- Introducing code reusability: If you are required to get the order details of any application modules, you can easily do so using the IOrder type.
- Improvements in code maintainability: We have now divided our modules into submodules or classes and interfaces. We can now structure our code in such a manner that all the types (that is, all the interfaces) are placed under one folder and follow the structure for the repositories. With this structure, it will be easier for us to arrange and maintain code.
- Unit testing: Our current monolithic application does not have any kind of unit testing. With the introduction of interfaces, we can now easily perform unit testing and adopt the system of test-driven development with ease.








