

Assessing architectural structures and paradigms
Establishing an architectural baseline helps to drive decisions regarding how the application and its components will ultimately be implemented. Additionally, it also provides an opportunity to evaluate different patterns and practices with the ultimate goal of selecting a path forward. This section covers the overall architectural design of the sample application and some core tenets that enable the creation and consumption of events.
A high-level logical architecture
The solution is predicated on the use of hardware interfaces (such as equipment) that can communicate to hosted services in the cloud via a standard network connection. There is a hardware gateway (such as Raspberry Pi) that hosts simple write-only services, which will integrate using relevant domain services to record turnstile usage, facial recognition hits, and possible malfunctions with the turnstile or camera. Any user interface can interact with a common API gateway layer, which allows for data exchange without needing to know all the particulars of the available APIs. The backend runtime is managed by Kubernetes (in this particular case, AKS), with containers for each of the available domain microservices. Each of these microservices interacts with the event bus to send events. Then, the events are handled according to the domain's applicable event handlers. A reporting layer is used to access information captured via the event stream. SQL databases will be used to maintain the append-only activity log of events that come in via Kafka, and read models will be consumed from domain databases using read-oriented services.
The following reference diagram shows the logical construction of the application:
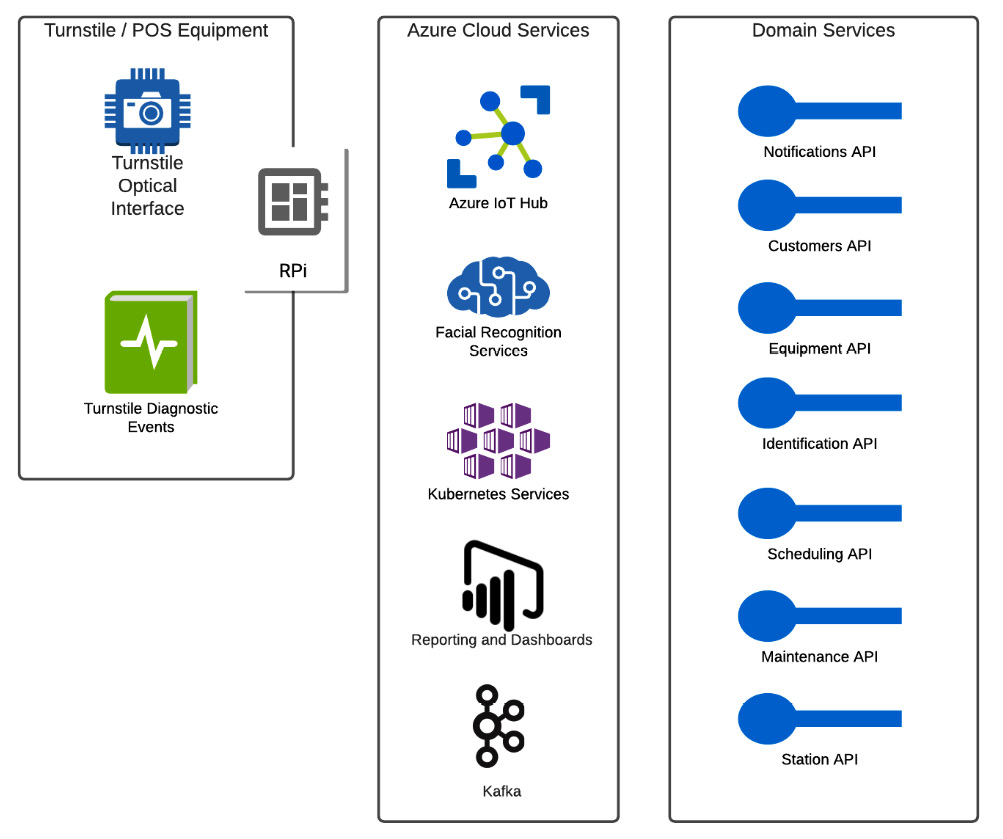
Figure 1.4 – A logical high-level reference architecture
The application uses the Producer-Consumer pattern to produce events, which are later consumed by components who need to know about them. You might also see this pattern referred to as Publish-Subscribe or pub-sub. The key point to take away from the use of this pattern is that any number of components could produce events containing relevant domain information, and any number of possible components could consume those events and act accordingly. We will dive into the producer-consumer pattern in much more detail in Chapter 2, The Producer-Consumer Pattern.
Digging down a layer, there are two technology architecture specifications that we will be using. One is for the device board inside the turnstile unit, which hosts the Equipment domain service. The other is the layout of the cloud components, as mentioned in the reference architecture in Figure 1.4. The high-level flow between the turnstile device and the cloud components is as follows:
- On the turnstile, after completing one turn, a message is sent to the equipment service indicating a completed rotation.
- The equipment service will send an event to the IoT hub with the results of the turnstile action.
- Using Kafka Connect, the message will be forwarded to Kafka, implemented within the Kubernetes cluster using the confluent platform.
- The event will be written to the appropriate stream.
- Any relevant event handlers will process the event.
A more detailed diagram of the technology architecture can be seen in Figure 1.5, where both the turnstile unit and the cloud components are represented:
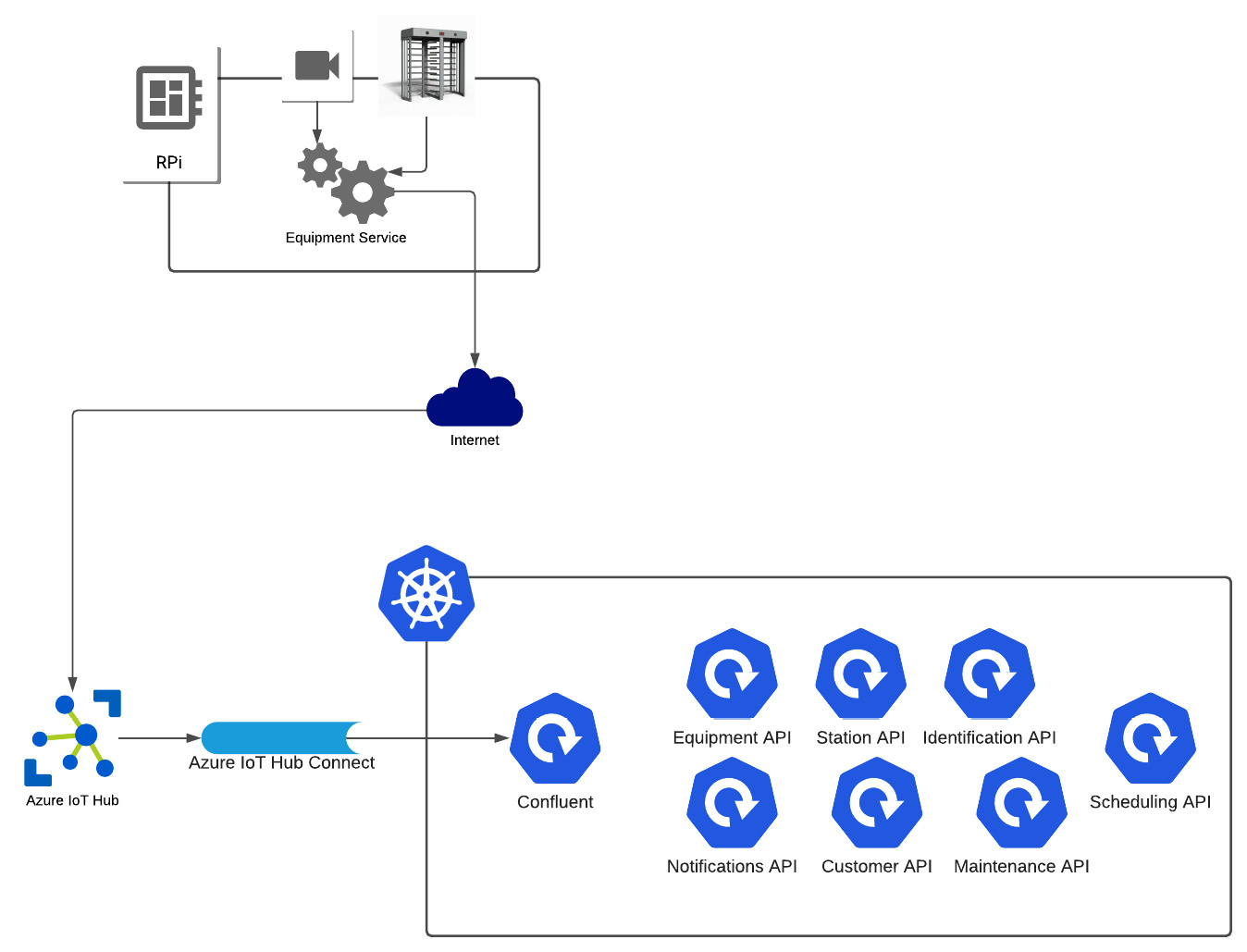
Figure 1.5 – The technology architecture for turnstile-to-cloud communication
Next, we will move on to the design of the event sourcing technique.
Event sourcing
Event sourcing is a technique that allows an application to append data to a log or stream in order to capture a definitive list of changes related to an object. One of the benefits of using event sourcing versus traditional create, retrieve, update, and delete (CRUD) methods with relational databases is that the performance can be tuned and increased at the service level, as the overhead of using CRUD methods is not needed. Also, it facilitates implementing a separation of concerns and the single responsibility principle, as outlined by the SOLID development practices (https://en.wikipedia.org/wiki/SOLID).
Another benefit of using event sourcing is its ability to achieve high message throughput while maintaining a high degree of resiliency. Technologies such as Kafka inherently allow for multiple message brokers and multiple partitions within topics. This design ensures that, at the very least, one broker is available to communicate with, and multiple partitions within a topic allow for data redundancy and scalability since Kafka will replicate partition data to each broker in the cluster. This enables multiple consumers to access or write data in parallel.
When using event stores with streaming capabilities, it enables you to debug point-in-time data and replay events to aid in debugging. For example, if an event has data that causes an error in the service code, you are fully able to go back to the point in time before that error was thrown and replay events to help identify potential bugs. Additionally, it can be used to perform "what if" testing. In some cases, normal use cases might have related edge cases that could either cause issues or introduce complexities that they were not originally designed for. Using "what if" testing allows you to go to a certain point in time and begin issuing new events that would correlate to the edge case while also monitoring application performance and potential failures.
Command-Query Responsibility Segregation
Command-Query Responsibility Segregation (CQRS) is a design pattern introduced by Greg Young that is used to describe the logical and physical separation of concerns for reading and writing data. Normally, you will see specific functionality implemented to only allow writing to an event store (commands) or only allow reading from an event store (queries). This allows for the independent scaling of read and write operations depending on the needs of the application or the needs of a presentation layer, either in the form of business intelligence software, such as PowerBI, or web applications accessible from desktop and mobile clients.
Details around how CQRS impacts the design of the application's domain services are covered in the next section. It's important to note that having that distinct separation of concerns is vital to leverage the pattern effectively.