

In this recipe, we will determine hierarchies in relational models. This recipe will also go over some of the main attribute dimension types. Attribute dimensions are dynamic dimensions that allow users to report on their data without increasing the foot print of the database. Attributes work in a similar way to an alternate hierarchy, but unlike an alternate hierarchy you can use an attribute dimension to conduct cross tab reporting on a different axis than your base dimension.
To get started, open SQL Server Management Studio, and add a database TBC, or if you are using Oracle you can add schema TBC and use TOAD or Golden to complete the recipe.
Execute the following script to add the
ProductTable. We can change the script below to PL/SQL by replacingintwith INTEGER andvarchar()with VARCHAR2():--Create Product Table T-SQL create table PRODUCT ( PRODUCTID int not null, FAMILYID int null , SKU varchar(15) null , SKU_ALIAS varchar(25) null , CAFFEINATED varchar(5) null , OUNCES int null , PKGTYPE varchar(15) null , INTRODATE datetime null , constraint PK_PRODUCT primary key (PRODUCTID) ) Go
Execute the following queries to load data into the table you have just created. The SKUs do not repeat in this table, but as part of your discovery phase you should make sure that this is the case as duplicates will throw off your findings. The scripts that follow this step will help you do just that.
--Insert values into product table. This syntax should work with either Pl/SQL or T-SQL Insert into PRODUCT Values(1 , 1 , '100-10', 'Cola', 'TRUE', 12, 'Can', 'Mar 25 1996 12:00AM'); Insert into PRODUCT Values(2 , 1 , '100-20', 'Diet Cola', 'TRUE', 12, 'Can', 'Apr 1 1996 12:00AM'); Insert into PRODUCT Values(3 , 1 , '100-30', 'Caffeine Free Cola', 'FALSE', 16, 'Bottle', 'Apr 1 1996 12:00AM'); Insert into PRODUCT Values(4 , 2 , '200-10', 'Old Fashioned', 'TRUE', 12, 'Bottle', 'Sep 27 1995 12:00AM'); Insert into PRODUCT Values(5 , 2 , '200-20', 'Diet Root Beer', 'TRUE', 16, 'Bottle', 'Jul 26 1996 12:00AM'); Insert into PRODUCT Values(6 , 2 , '200-30', 'Sasparilla', 'FALSE', 12, 'Bottle', 'Dec 10 1996 12:00AM'); Insert into PRODUCT Values(7 , 2 , '200-40', 'Birch Beer', 'FALSE', 16, 'Bottle', 'Dec 10 1996 12:00AM'); Insert into PRODUCT Values(8 , 3 , '300-10', 'Dark Cream', 'TRUE', 20, 'Bottle', 'Jun 26 1996 12:00AM'); Insert into PRODUCT Values(9 , 3 , '300-20', 'Vanilla Cream', 'TRUE', 20, 'Bottle', 'Jun 26 1996 12:00AM'); Insert into PRODUCT Values(10, 3 , '300-30', 'Diet Cream', 'TRUE', 12, 'Can', 'Jun 26 1996 12:00AM'); Insert into PRODUCT Values(11, 4 , '400-10', 'Grape', 'FALSE', 32, 'Bottle', 'Oct 1 1996 12:00AM'); Insert into PRODUCT Values(12, 4 , '400-20', 'Orange', 'FALSE', 32, 'Bottle', 'Oct 1 1996 12:00AM'); Insert into PRODUCT Values(13, 4 , '400-30', 'Strawberry', 'FALSE', 32, 'Bottle', 'Oct 1 1996 12:00AM');
Execute the following script to determine the SKU count in the
PRODUCTtable:--Retrieve SKU count for both PL\SQL and T-SQL Select Count(SKU) From PRODUCT;
Execute the following scripts to determine the cardinality between the
SKUand theCAFFEINATEDcolumns:--Determine if there is one-to-many relationship between SKU and Caffeinated for both PL\SQL and T-SQL Select SKU, Count(CAFFEINATED) As Cnt From PRODUCT Group By SKU Having Count(CAFFEINATED) = 1; Select CAFFEINATED, Count(SKU) As Cnt From PRODUCT T1 Group By CAFFEINATED;
Execute the following scripts to determine the cardinality between the
SKUand theOUNCEScolumns:--Determine if there is one-to-many relationship between SKU and Ounces for both PL\SQL and T-SQL Select SKU, Count(OUNCES) As Cnt From PRODUCT Group By SKU Having Count(OUNCES) = 1; Select OUNCES, Count(SKU) As Cnt From PRODUCT Group By OUNCES;
Execute the following scripts to determine the cardinality between the
SKUandPKGTYPEcolumns:--Determine if there is one-to-many relationship between SKU and PKGTYPE for both PL\SQL and T-SQL Select SKU, Count(PKGTYPE) As Cnt From PRODUCT Group By SKU Having Count(PKGTYPE) = 1; Select PKGTYPE, Count(SKU) As Cnt From PRODUCT Group By PKGTYPE;
Execute the following script to determine the cardinality between the
SKUandINTRODATEcolumns:--Determine if there is one-to-many relationship between SKU and IntroDate for both PL\SQL and T-SQL Select SKU, Count(INTRODATE) As Cnt From PRODUCT Group By SKU Having Count(INTRODATE) = 1; Select INTRODATE, Count(SKU) As Cnt From PRODUCT Group By INTRODATE;
Execute the following scripts to determine the cardinality between the
SKUandPRODUCTIDcolumns:Execute the following scripts to determine the cardinality between the
PRODUCTIDandFAMILYIDcolumns:--Determine if there is one-to-many relationship between PRODUCTID and FAMILYID for both PL\SQL and T-SQL Select PRODUCTID, Count(FAMILYID) As Cnt From PRODUCT Group By PRODUCTID Having Count(PRODUCTID) = 1; Select FAMILYID, Count(PRODUCTID) As Cnt From PRODUCT Group By FAMILYID;
The first and second steps setup a Product Table and populate it with data. The third step retrieves a count of the SKUs in your Product table. You will need this count to determine if the attribute column has a one-to-many relationship with the SKU. This query returned exactly 13 valid SKUs.
The first script in step 4 returns a row for every time the SKU rolls up to one parent. You can see in the following screenshot, that there are exactly 13 rows signifying that each SKU rolls up to one CAFFEINATED value.
This query returns the value, as shown in the following screenshot:
Select SKU, Count(CAFFEINATED) As Cnt From PRODUCT Group By SKU Having Count(CAFFEINATED) = 1;1;
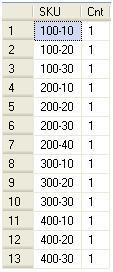
The second script in step 4 shows you that the CAFFEINATED column has a true and false value, which makes this column a good candidate for a Boolean attribute dimension. The reason this is a Boolean attribute is because it has exactly either of the two values TRUE or FALSE. The counts from this query and the previous one shows you that there are one-to-many relationships as SKUs rollup to only one CAFFEINATED value, but a single CAFFEINATED value can have many SKU children.
This script returns TRUE and FALSE values as depicted in the following screenshot:
Select CAFFEINATED, Count(SKU) As Cnt From PRODUCT T1 Group By CAFFEINATED;
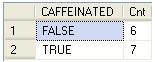
The scripts in step 5 show a one-to-many relationship between SKU and OUNCES. Script 2 of step 5 shows that OUNCES will make a good candidate for a NUMERIC attribute dimension. A NUMERIC attribute type is as the word implies a number. We can use a NUMERIC attribute's value in calculating scripts or outline formulas to create formulas based on the attribute assigned.
This query returns a list of numeric values as depicted in the following screenshot:
SelectOUNCES,Count(SKU)AsCntFromPRODUCTGroupByOUNCES;
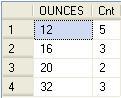
The scripts in step 6 show a one-to-many relationship between SKU and PKGTYPE as it returns exactly 13 unique records. Script 2 of step 6 shows the PKGTYPE that would make a good TEXT attribute or an alternate dimension. A
TEXT attribute allows for a comparison in calculations and a selection of a member based on the attribute assigned. Text attributes are the default attribute in Essbase.
This query returns a list of text values as depicted in the following screenshot:
SelectPKGTYPE,Count(SKU)AsCntFromPRODUCTGroupByPKGTYPE;
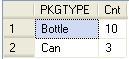
The scripts in step 7 also show a one-to-many relationship between SKU and INTRODATE. Script 2 of step 7 shows that INTRODATE is, as the name implies, a date and as such will make a good DATE attribute dimension. You can use DATE attributes in calculation as well. We can compare different Products, for example, based on the DATE attribute for specific Market. Date attributes from January 1, 1970 through January 1, 2038 are supported.
This query returns a list of date values as depicted in the following screenshot:
SelectINTRODATE,Count(SKU)AsCntFromPRODUCTGroupByINTRODATE;
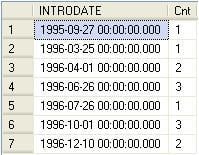
Moreover, in step 8 you will see a one-to-one relationship between SKU and PRODUCTID, which means there is exactly one PRODUCTID for each SKU, and one SKU will rollup to exactly one parent. Script 2 of step 8 shows that this will more than likely be the main rollup in your PRODUCT dimension. This is also intuitive as the SKU in this case is the column representing the product:
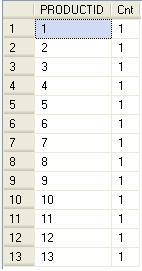
Finally, the relationship between FAMILYID and PRODUCTID is a one-to-many relationship, shown in step 9. A possible outcome of these findings is to create a dimension and hiearchy with three generations as depicted in the following table:
|
DIMENSION |
GENERATION |
LEVEL |
|---|---|---|
|
PRODUCT |
1 |
2 |
|
FAMILYID |
2 |
1 |
|
SKU |
3 |
0 |
In real world situations, you may come across scenarios where your relationships are not always one-to-one or one-to-many. Keep a note of these exceptions as you may need to concatenate columns, create alternate rollups with shared members, add a prefix or suffix, create a new dimension, or turn on duplicate members in your outline in order to deal with these issues. We will go over some of these in other chapters. That said, the preceding scripts will help you see these discrepancies before you begin building your cube, which will save you time later in your development. In addition, note that when building a BSO cube you can only assign attributes to a sparse dimension.
Refer to the recipes Adding attribute dimensions to hierarchies and Setting Essbase Properties in Chapter 3 to learn how to set up attribute dimensions and their properties in Essbase Studio.