

The extensive success of Hadoop 1.X in organizations also led to the understanding of its limitations, which are as follows:
Hadoop gives unprecedented access to cluster computational resources to every individual in an organization. The MapReduce programming model is simple and supports a develop once deploy at any scale paradigm. This leads to users exploiting Hadoop for data processing jobs where MapReduce is not a good fit, for example, web servers being deployed in long-running map jobs. MapReduce is not known to be affable for iterative algorithms. Hacks were developed to make Hadoop run iterative algorithms. These hacks posed severe challenges to cluster resource utilization and capacity planning.
Hadoop 1.X has a centralized job flow control. Centralized systems are hard to scale as they are the single point of load lifting. JobTracker failure means that all the jobs in the system have to be restarted, exerting extreme pressure on a centralized component. Integration of Hadoop with other kinds of clusters is difficult with this model.
The early releases in Hadoop 1.X had a single NameNode that stored all the metadata about the HDFS directories and files. The data on the entire cluster hinged on this single point of failure. Subsequent releases had a cold standby in the form of a secondary NameNode. The secondary NameNode merged the edit logs and NameNode image files, periodically bringing in two benefits. One, the primary NameNode startup time was reduced as the NameNode did not have to do the entire merge on startup. Two, the secondary NameNode acted as a replica that could minimize data loss on NameNode disasters. However, the secondary NameNode (secondary NameNode is not a backup node for NameNode) was still not a hot standby, leading to high failover and recovery times and affecting cluster availability.
Hadoop 1.X is mainly a Unix-based massive data processing framework. Native support on machines running Microsoft Windows Server is not possible. With Microsoft entering cloud computing and big data analytics in a big way, coupled with existing heavy Windows Server investments in the industry, it's very important for Hadoop to enter the Microsoft Windows landscape as well.
Hadoop's success comes mainly from enterprise play. Adoption of Hadoop mainly comes from the availability of enterprise features. Though Hadoop 1.X tries to support some of them, such as security, there is a list of other features that are badly needed by the enterprise.
In Hadoop 1.X, resource allocation and job execution were the responsibilities of JobTracker. Since the computing model was closely tied to the resources in the cluster, MapReduce was the only supported model. This tight coupling led to developers force-fitting other paradigms, leading to unintended use of MapReduce.
The primary goal of YARN is to separate concerns relating to resource management and application execution. By separating these functions, other application paradigms can be added onboard a Hadoop computing cluster. Improvements in interoperability and support for diverse applications lead to efficient and effective utilization of resources. It integrates well with the existing infrastructure in an enterprise.
Achieving loose coupling between resource management and job management should not be at the cost of loss in backward compatibility. For almost 6 years, Hadoop has been the leading software to crunch massive datasets in a parallel and distributed fashion. This means huge investments in development; testing and deployment were already in place.
YARN maintains backward compatibility with Hadoop 1.X (hadoop-0.20.205+) APIs. An older MapReduce program can continue execution in YARN with no code changes. However, recompiling the older code is mandatory.
The following figure lays out the architecture of YARN. YARN abstracts out resource management functions to a platform layer called ResourceManager (RM). There is a per-cluster RM that primarily keeps track of cluster resource usage and activity. It is also responsible for allocation of resources and resolving contentions among resource seekers in the cluster. RM uses a generalized resource model and is agnostic to application-specific resource needs. For example, RM need not know the resources corresponding to a single Map or Reduce slot.

Planning and executing a single job is the responsibility of Application Master (AM). There is an AM instance per running application. For example, there is an AM for each MapReduce job. It has to request for resources from the RM, use them to execute the job, and work around failures, if any.
The general cluster layout has RM running as a daemon on a dedicated machine with a global view of the cluster and its resources. Being a global entity, RM can ensure fairness depending on the resource utilization of the cluster resources. When requested for resources, RM allocates them dynamically as a node-specific bundle called a container. For example, 2 CPUs and 4 GB of RAM on a particular node can be specified as a container.
Every node in the cluster runs a daemon called NodeManager (NM). RM uses NM as its node local assistant. NMs are used for container management functions, such as starting and releasing containers, tracking local resource usage, and fault reporting. NMs send heartbeats to RM. The RM view of the system is the aggregate of the views reported by each NM.
Jobs are submitted directly to RMs. Based on resource availability, jobs are scheduled to run by RMs. The metadata of the jobs are stored in persistent storage to recover from RM crashes. When a job is scheduled, RM allocates a container for the AM of the job on a node in the cluster.
AM then takes over orchestrating the specifics of the job. These specifics include requesting resources, managing task execution, optimizations, and handling tasks or job failures. AM can be written in any language, and different versions of AM can execute independently on a cluster.
An AM resource request contains specifications about the locality and the kind of resource expected by it. RM puts in its best effort to satisfy AM's needs based on policies and availability of resources. When a container is available for use by AM, it can launch application-specific code in this container. The container is free to communicate with its AM. RM is agnostic to this communication.
A number of storage layer enhancements were undertaken in the Hadoop 2.X releases. The number one goal of the enhancements was to make Hadoop enterprise ready.
NameNode is a directory service for Hadoop and contains metadata pertaining to the files within cluster storage. Hadoop 1.X had a secondary Namenode, a cold standby that needed minutes to come up. Hadoop 2.X provides features to have a hot standby of NameNode. On the failure of an active NameNode, the standby can become the active Namenode in a matter of minutes. There is no data loss or loss of NameNode service availability. With hot standbys, automated failover becomes easier too.
The key to keep the standby in a hot state is to keep its data as current as possible with respect to the active Namenode. This is achieved by reading the edit logs of the active NameNode and applying it onto itself with very low latency. The sharing of edit logs can be done using the following two methods:
A shared NFS storage directory between the active and standby NameNodes: the active writes the logs to the shared location. The standby monitors the shared directory and pulls in the changes.
A quorum of Journal Nodes: the active NameNode presents its edits to a subset of journal daemons that record this information. The standby node constantly monitors these journal daemons for updates and syncs the state with itself.
The following figure shows the high availability architecture using a quorum of Journal Nodes. The data nodes themselves send block reports directly to both the active and standby NameNodes:
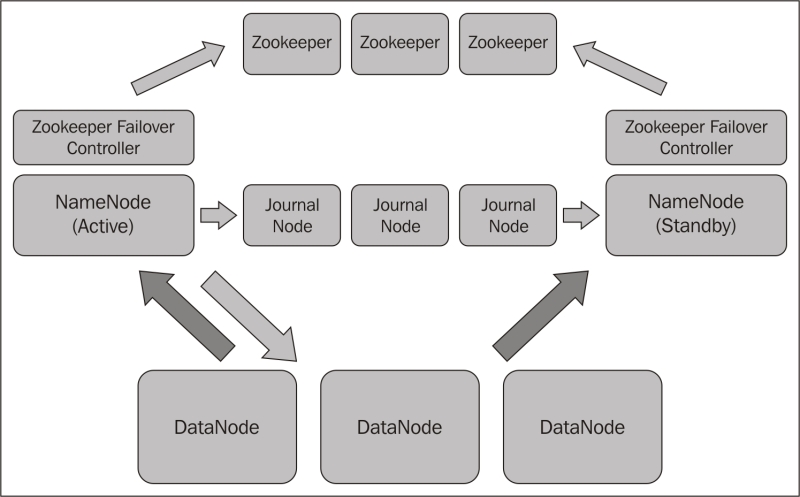
Zookeeper or any other High Availability monitoring service can be used to track NameNode failures. With the assistance of Zookeeper, failover procedures to promote the hot standby as the active NameNode can be triggered.
Similar to what YARN did to Hadoop's computation layer, a more generalized storage model has been implemented in Hadoop 2.X. The block storage layer has been generalized and separated out from the filesystem layer. This separation has given an opening for other storage services to be integrated into a Hadoop cluster. Previously, HDFS and the block storage layer were tightly coupled.
One use case that has come forth from this generalized storage model is HDFS Federation. Federation allows multiple HDFS namespaces to use the same underlying storage. Federated NameNodes provide isolation at the filesystem level. In Chapter 10, HDFS Federation, we will delve into the details of this feature.
Snapshots are point-in-time, read-only images of the entire or a particular subset of a filesystem. Snapshots are taken for three general reasons:
Protection against user errors
Backup
Disaster recovery
Snapshotting is implemented only on NameNode. It does not involve copying data from the data nodes. It is a persistent copy of the block list and file size. The process of taking a snapshot is almost instantaneous and does not affect the performance of NameNode.
There are a number of other enhancements in Hadoop 2.X, which are as follows:
The wire protocol for RPCs within Hadoop is now based on Protocol Buffers. Previously, Java serialization via Writables was used. This improvement not only eases maintaining backward compatibility, but also aids in rolling the upgrades of different cluster components. RPCs allow for client-side retries as well.
HDFS in Hadoop 1.X was agnostic about the type of storage being used. Mechanical or SSD drives were treated uniformly. The user did not have any control on data placement. Hadoop 2.X releases in 2014 are aware of the type of storage and expose this information to applications as well. Applications can use this to optimize their data fetch and placement strategies.
HDFS append support has been brought into Hadoop 2.X.
HDFS access in Hadoop 1.X releases has been through HDFS clients. In Hadoop 2.X, support for NFSv3 has been brought into the NFS gateway component. Clients can now mount HDFS onto their compatible local filesystem, allowing them to download and upload files directly to and from HDFS. Appends to files are allowed, but random writes are not.
A number of I/O improvements have been brought into Hadoop. For example, in Hadoop 1.X, clients collocated with data nodes had to read data via TCP sockets. However, with short-circuit local reads, clients can directly read off the data nodes. This particular interface also supports zero-copy reads. The CRC checksum that is calculated for reads and writes of data has been optimized using the Intel SSE4.2 CRC32 instruction.
Hadoop is also widening its application net by supporting other platforms and frameworks. One dimension we saw was onboarding of other computational models with YARN or other storage systems with the Block Storage layer. The other enhancements are as follows:
Hadoop 2.X supports Microsoft Windows natively. This translates to a huge opportunity to penetrate the Microsoft Windows server land for massive data processing. This was partially possible because of the use of the highly portable Java programming language for Hadoop development. The other critical enhancement was the generalization of compute and storage management to include Microsoft Windows.
As part of Platform-as-a-Service offerings, cloud vendors give out on-demand Hadoop as a service. OpenStack support in Hadoop 2.X makes it conducive for deployment in elastic and virtualized cloud environments.