

We'll now apply the k-means algorithm to cluster the countries together:
>>> km = KMeans(3, init='k-means++', random_state = 3425) # initialize >>> km.fit(df.values) >>> df['countrySegment'] = km.predict(df.values) >>> df[:5]
After the preceding code is executed we'll get the following output:
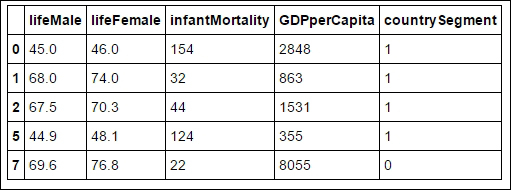
Let's find the average GDP per capita for each country segment:
>>> df.groupby('countrySegment').GDPperCapita.mean() >>> countrySegment 0 13800.586207 1 1624.538462 2 29681.625000 Name: GDPperCapita, dtype: float64
We can see that cluster 2 has the highest average GDP per capita and we can assume that this includes developed countries. Cluster 0 has the second highest GDP, we can assume this includes developing countries, and finally, cluster 1 has a very low average GDP per capita. We can assume this includes developed nations:
>>> clust_map = { 0:'Developing', 1:'Under Developed', ...