

As an initial start, the objective function can be defined as the minimization of the average negative log-likelihood of reconstructing the visible vector v where P(v) denotes the vector of generated probabilities:
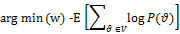
This section provides the requirements for image reconstruction using the input probability vector.
mnistdata is loaded in the environment- The images are reconstructed using the recipe Backward or reconstruction phase
This current recipe present the steps for, a contrastive divergence (CD) technique used to speed up the sampling process:
- Compute a positive weight gradient by multiplying (outer product) the input vector
Xwith a sample of the hidden vectorh0from the given probability distributionprob_h0:
w_pos_grad = tf$matmul(tf$transpose(X), h0)
- Compute a negative weight gradient by multiplying (outer product) the sample of the reconstructed input data
v1with the updated hidden activation...