

Before there was the cloud
There are a variety of tools on the market, ranging from open source to closed source and self-managed to hosted offerings, supporting build pipelines. Availability of the pipeline solution is critical in ensuring that code is built in a timely manner; otherwise, it may impact the productivity of multiple teams. Organizations may have separate teams that are responsible for maintaining the solution that executes the build pipeline.
Making sure there are enough resources
For self-managed solutions, the maintenance includes the underlying infrastructure, OS, tools, and libraries that make up the pipeline infrastructure. Scale is also a factor for build pipelines; depending on the complexity, organizations may have multiple concurrent builds occurring at the same time. Build pipelines need at least compute, memory, and disk to execute, typically referred to as workers within the build platform. A build pipeline may consist of multiple jobs, steps, or tasks to complete a particular pipeline to be executed. The workers are assigned tasks to complete from the build platform. Workers need to be made available so that they can be assigned tasks and such tasks are executed. Similar to capacity planning and sizing needs for applications, enough compute, memory, storage, or any other resource for workers must be planned out.
There must be enough hardware to handle builds at the peak. Peak is an important topic because in a data center scenario, hardware resources can be somewhat finite because it takes time to acquire and set up the hardware. Technologies such as virtualization have given us the ability to overprovision compute resources, but at some point, physical hardware becomes the bottleneck for growth if our build needs become more demanding. While an organization needs to size for peak, that also means that builds are not always running constantly at peak to make full use of the allocated resources. Virtualization, as mentioned previously, may help us with other workloads consuming compute during off-peak time, but this may require significant coordination efforts throughout the organization. We may be left with underutilized and wasted resources.
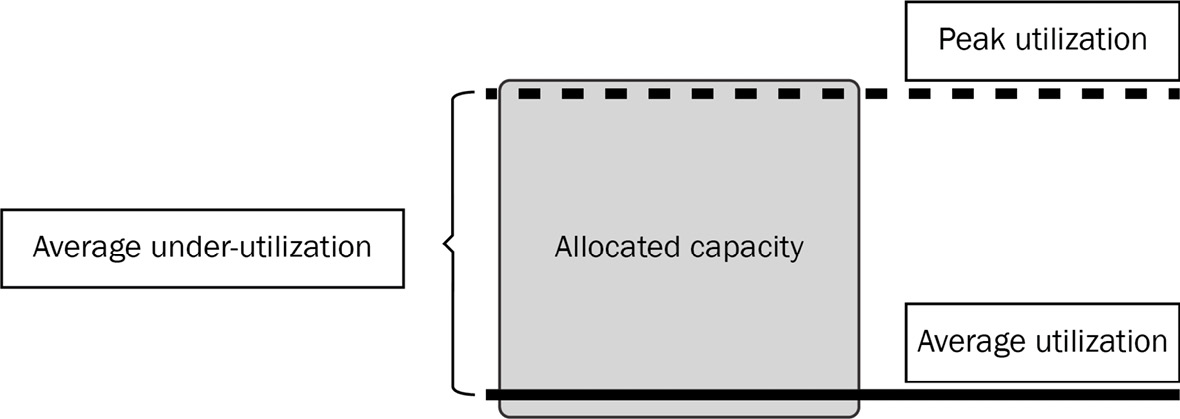
Figure 1.3 – Under-utilized resources when allocating for peak utilization
Who needs to manage all of this?
A team typically maintains and manages the build infrastructure within an organization. This team may be dedicated to ensuring the environment is available, resources are kept up to date, and new capabilities are added to support organizational needs. Requirements can come from all directions, such as developers, operators, platform administrators, and infrastructure administrators. Different build and pipeline tools on the market do help to facilitate some of this by offering plugins and extensions to extend capabilities. For instance, Jenkins has community contributions of 1,800+ plugins (https://plugins.jenkins.io/) at the time of writing this book. While that is quite an amount, this can also mean teams have to ensure plugins are updated and keep up to date with the plugins’ life cycles. For instance, if the plugin is no longer being maintained, what are the alternatives? If multiple plugins perform similar functions, which one should be chosen? A rich community is beneficial as popular plugins bubble up and may have better support.
While productivity is impacted as mentioned, not having enough capacity or improperly sizing the build infrastructure could lead to slower builds. Builds come in all shapes; they can run in seconds for some, while to others, they can take hours. For builds that take hours or a long time, this would mean the developer and many other downstream teams are waiting. Just because a build is submitted successfully, it does not mean it completes successfully too; it could possibly fail at any point of the build, leading to lost time.
The team that is responsible for managing the build infrastructure may also be likely responsible for maintaining a service-level agreement (SLA) to the users of the system. The design of the solution may also have been designed by another team. As noted earlier, if builds are not running, there may be a cost associated because it impacts the productivity of developers, delays in product releases, or delays in pushing out critical patches to the system. This needs to be taken into account when self-managing a solution. While this was the norm for much of the industry before there was the cloud, in an on-premises enterprise, vendors developed tools and platforms to ease the burden of infrastructure management. Managed service providers (MSPs) also provided tooling layers to help organizations manage compute resources, but organizations still had to take into account resources that were being spun up or down.
Security is a critical factor to be considered when organizations need to manage their own software components on top of infrastructure or the entire stack. It’s not just the vulnerability of the code itself being built, but the underlying build system needs to be securely maintained as well. In the last few years, a significant vulnerability was exposed across all industries (https://orangematter.solarwinds.com/2021/05/07/an-investigative-update-of-the-cyberattack/).
Eventually, when public cloud resources were available, much of the similar patterns discussed could be used – in this case, infrastructure as a service (IaaS) offerings in a cloud provider for handling the compute infrastructure. These eased the burden of having to deal with compute resources, but again, like MSPs, the notion of workers had to be determined and managed.
Organizations have had to deal with the build software pipeline platform regardless of whether the infrastructure was managed on-premises in their data center, in a co-location, or by an IaaS provider. It is critical to ensure that the platform is available and has sufficient capacity for workers to complete associated tasks. In many organizations, this consisted of dedicated teams that managed the infrastructure or teams that wore multiple hats to ensure the build platform was operational.