

Before diving deep into pandas, it is worth knowing the components of the DataFrame. Visually, the outputted display of a pandas DataFrame (in a Jupyter Notebook) appears to be nothing more than an ordinary table of data consisting of rows and columns. Hiding beneath the surface are the three components--the index, columns, and data (also known as values) that you must be aware of in order to maximize the DataFrame's full potential.
Dissecting the anatomy of a DataFrame
Getting ready
This recipe reads in the movie dataset into a pandas DataFrame and provides a labeled diagram of all its major components.
How to do it...
- Use the read_csv function to read in the movie dataset, and display the first five rows with the head method:
>>> movie = pd.read_csv('data/movie.csv')
>>> movie.head()
- Analyze the labeled anatomy of the DataFrame:
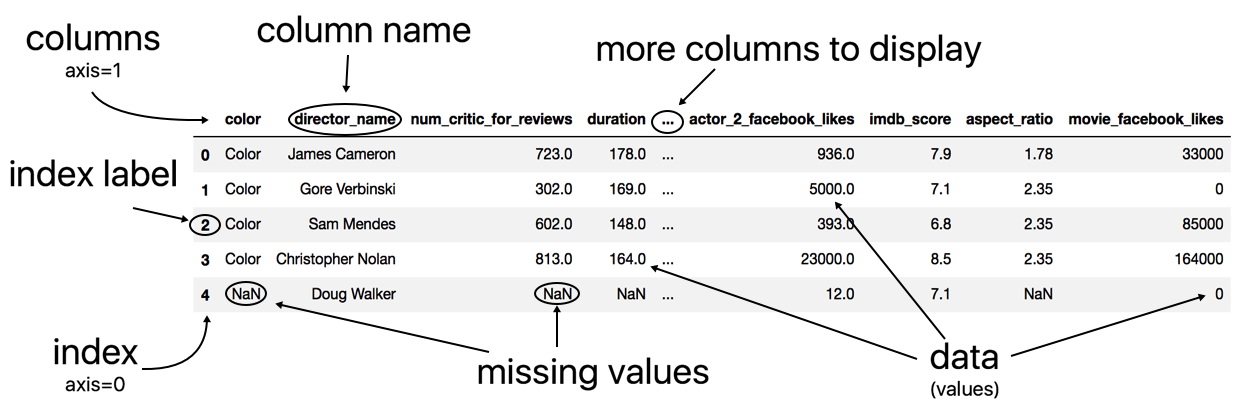
How it works...
Pandas first reads the data from disk into memory and into a DataFrame using the excellent and versatile read_csv function. The output for both the columns and the index is in bold font, which makes them easy to identify. By convention, the terms index label and column name refer to the individual members of the index and columns, respectively. The term index refers to all the index labels as a whole just as the term columns refers to all the column names as a whole.
The columns and the index serve a particular purpose, and that is to provide labels for the columns and rows of the DataFrame. These labels allow for direct and easy access to different subsets of data. When multiple Series or DataFrames are combined, the indexes align first before any calculation occurs. Collectively, the columns and the index are known as the axes.
A DataFrame has two axes--a vertical axis (the index) and a horizontal axis(the columns). Pandas borrows convention from NumPy and uses the integers 0/1 as another way of referring to the vertical/horizontal axis.
DataFrame data (values) is always in regular font and is an entirely separate component from the columns or index. Pandas uses NaN (not a number) to represent missing values. Notice that even though the color column has only string values, it uses NaN to represent a missing value.
The three consecutive dots in the middle of the columns indicate that there is at least one column that exists but is not displayed due to the number of columns exceeding the predefined display limits.
The Python standard library contains the csv module, which can be used to parse and read in data. The pandas read_csv function offers a powerful increase in performance and functionality over this module.
There's more...
The head method accepts a single parameter, n, which controls the number of rows displayed. Similarly, the tail method returns the last n rows.
See also
- Pandas official documentation of the read_csv function (http://bit.ly/2vtJQ9A)