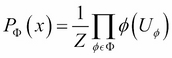-
Book Overview & Buying

-
Table Of Contents

Mastering Probabilistic Graphical Models with Python
By :
Mastering Probabilistic Graphical Models with Python
By:
Overview of this book
Probabilistic Graphical Models is a technique in machine learning that uses the concepts of graph theory to compactly represent and optimally predict values in our data problems. In real world problems, it's often difficult to select the appropriate graphical model as well as the appropriate inference algorithm, which can make a huge difference in computation time and accuracy. Thus, it is crucial to know the working details of these algorithms.
This book starts with the basics of probability theory and graph theory, then goes on to discuss various models and inference algorithms. All the different types of models are discussed along with code examples to create and modify them, and also to run different inference algorithms on them. There is a complete chapter devoted to the most widely used networks Naive Bayes Model and Hidden Markov Models (HMMs). These models have been thoroughly discussed using real-world examples.
Table of Contents (9 chapters)
Preface

 Free Chapter
Free Chapter
1. Bayesian Network Fundamentals
2. Markov Network Fundamentals
3. Inference – Asking Questions to Models
4. Approximate Inference
5. Model Learning – Parameter Estimation in Bayesian Networks
6. Model Learning – Parameter Estimation in Markov Networks
7. Specialized Models
Index