-
Book Overview & Buying

-
Table Of Contents

Spark for Data Science
By :
Spark for Data Science
By:
Overview of this book
This is the era of Big Data. The words ‘Big Data’ implies big innovation and enables a competitive advantage for businesses. Apache Spark was designed to perform Big Data analytics at scale, and so Spark is equipped with the necessary algorithms and supports multiple programming languages.
Whether you are a technologist, a data scientist, or a beginner to Big Data analytics, this book will provide you with all the skills necessary to perform statistical data analysis, data visualization, predictive modeling, and build scalable data products or solutions using Python, Scala, and R.
With ample case studies and real-world examples, Spark for Data Science will help you ensure the successful execution of your data science projects.
Table of Contents (12 chapters)
Preface

 Free Chapter
Free Chapter
1. Big Data and Data Science – An Introduction
2. The Spark Programming Model
3. Introduction to DataFrames
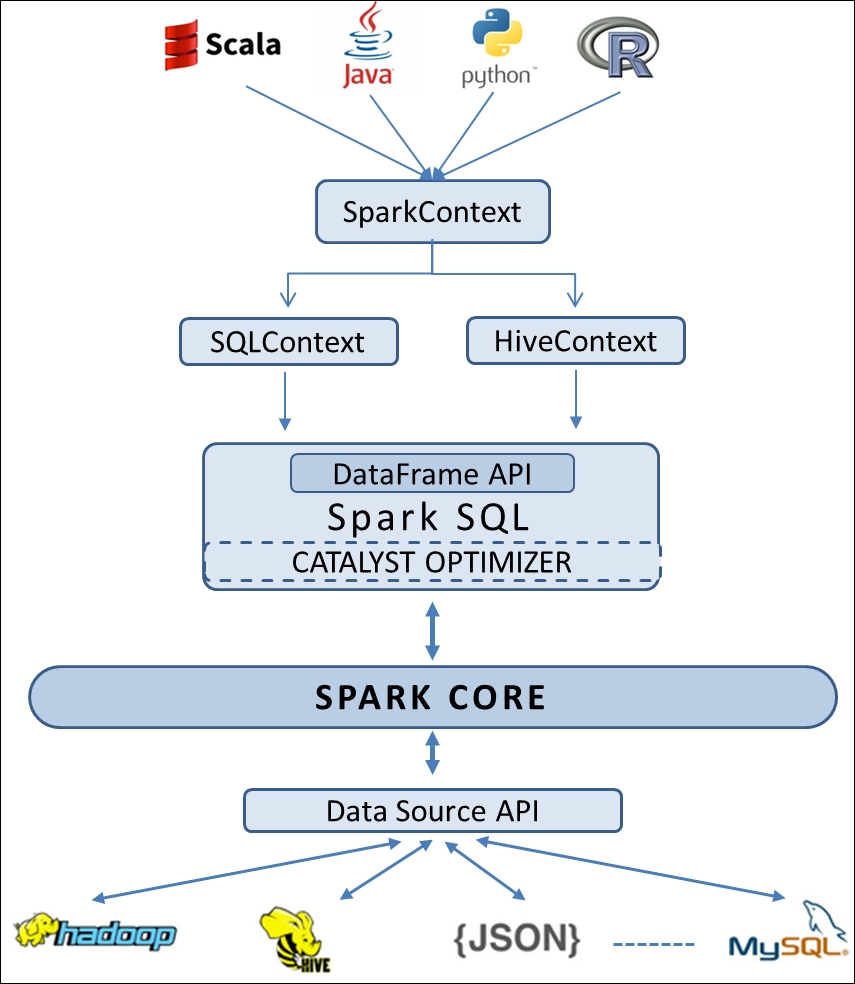
4. Unified Data Access
5. Data Analysis on Spark
6. Machine Learning
7. Extending Spark with SparkR
8. Analyzing Unstructured Data
9. Visualizing Big Data
10. Putting It All Together
11. Building Data Science Applications