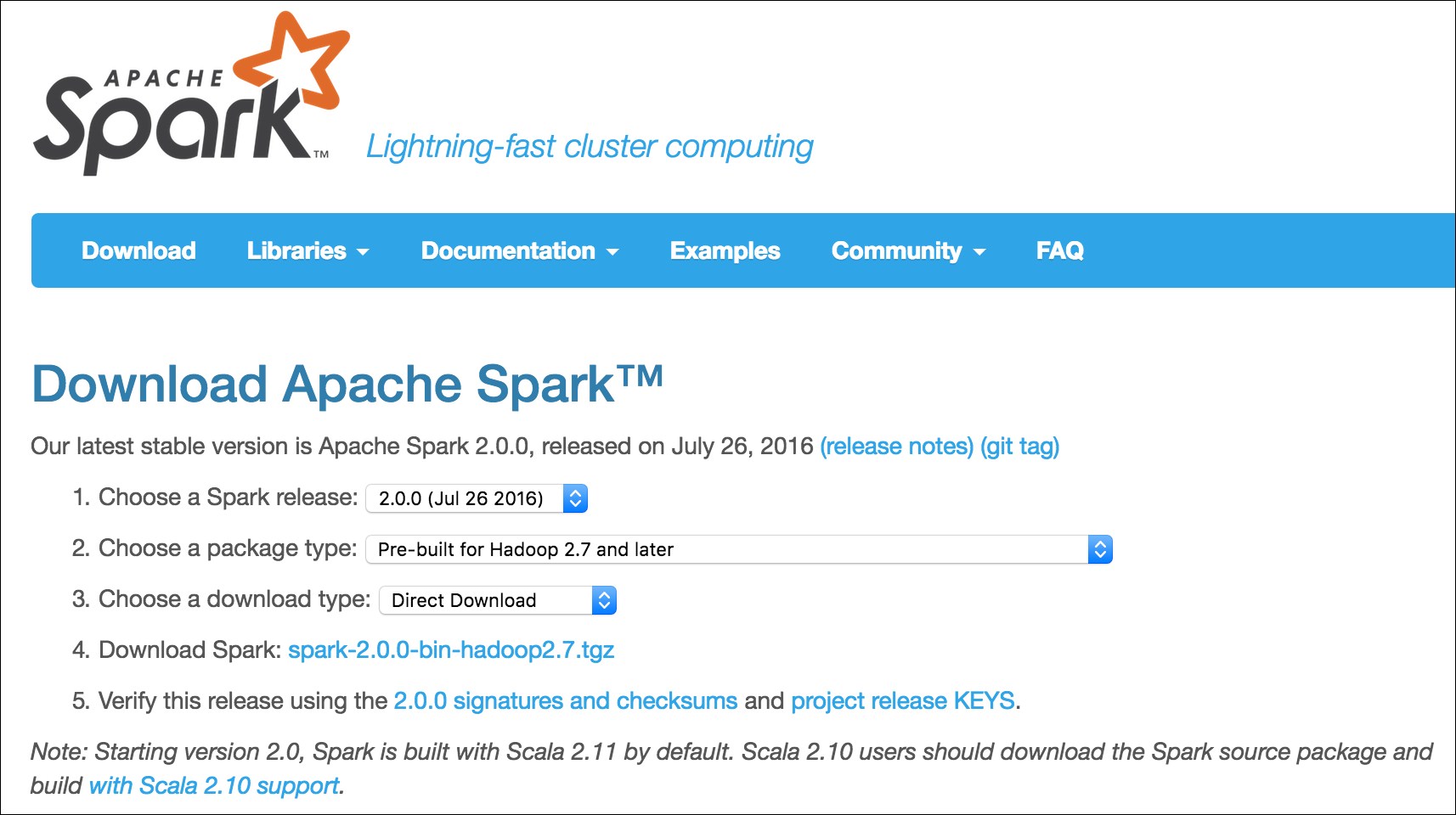
Let's download prebuilt Spark and install it. Later, we will also compile a version and build from the source. The download is straightforward. The download page is at http://spark.apache.org/downloads.html. Select the options as shown in the following screenshot:
We will use wget from the command line. You can do a direct download as well:
cd /opt sudo wget http://www-us.apache.org/dist/spark/spark-2.0.0/spark-2.0.0-bin-hadoop2.7.tgz
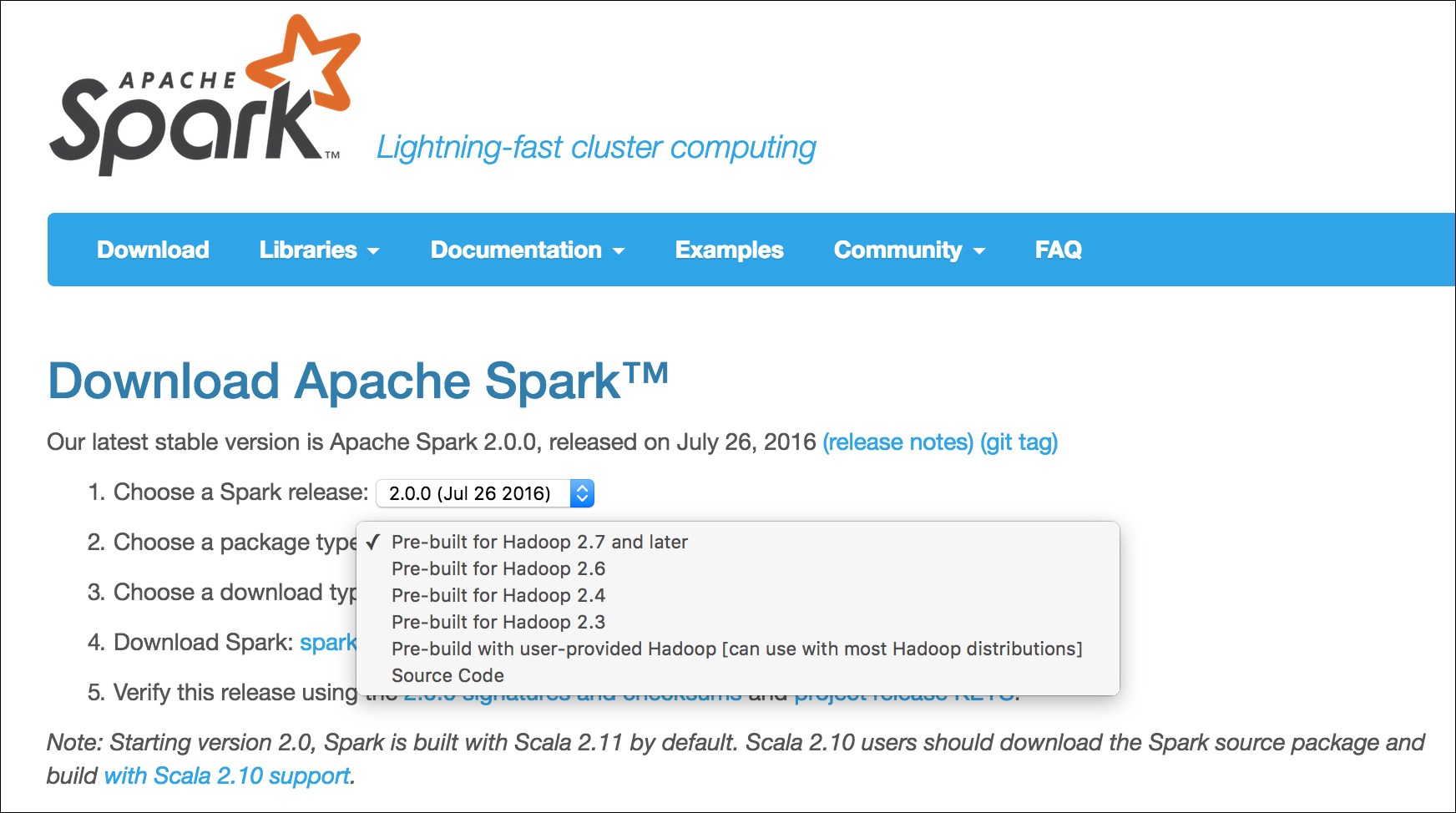
We are downloading the prebuilt version for Apache Hadoop 2.7 from one of the possible mirrors. We could have easily downloaded other prebuilt versions as well, as shown in the following screenshot:
To uncompress it, execute the following command:
sudo tar xvf spark-2.0.0-bin-hadoop2.7.tgz
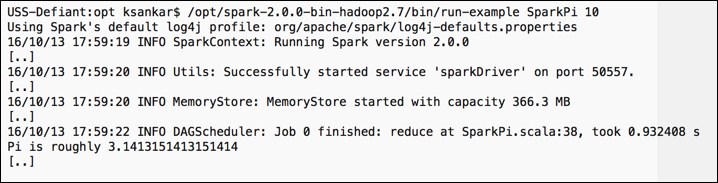
To test the installation, run the following command:
/opt/spark-2.0.0-bin-hadoop2.7/bin/run-example SparkPi 10
It will fire up the Spark stack and calculate the value of Pi. The result will be as shown in the following screenshot: