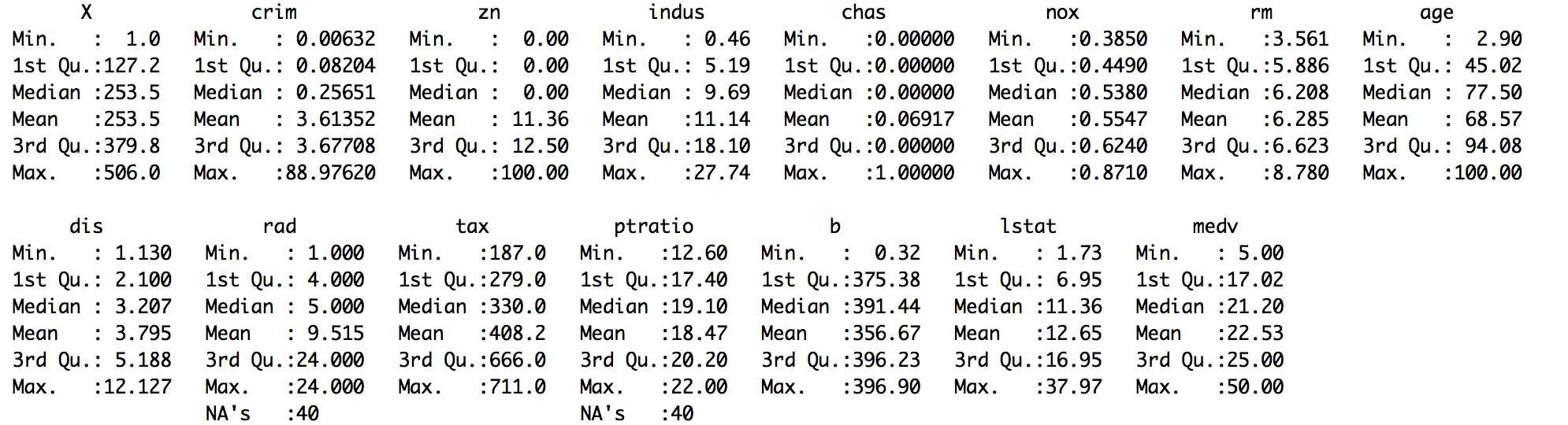
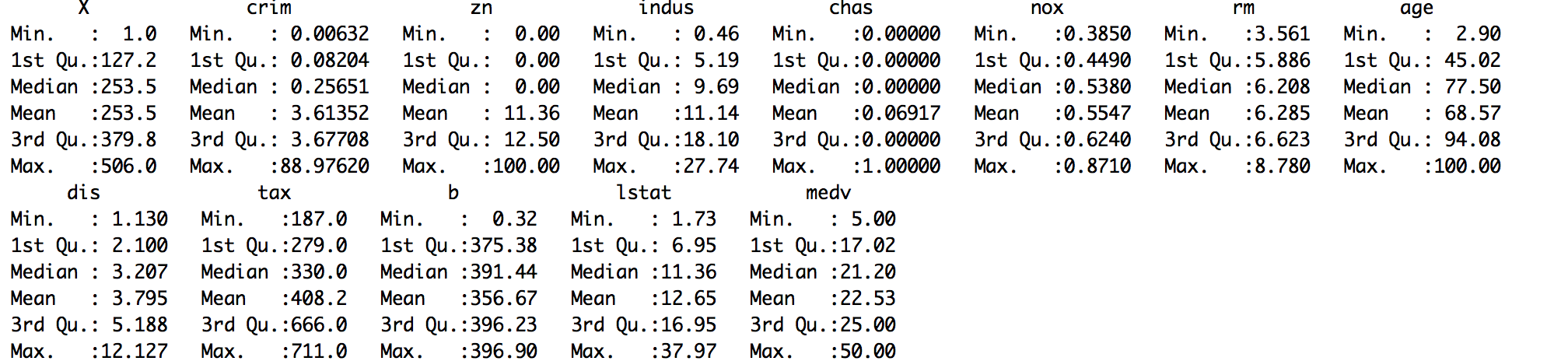
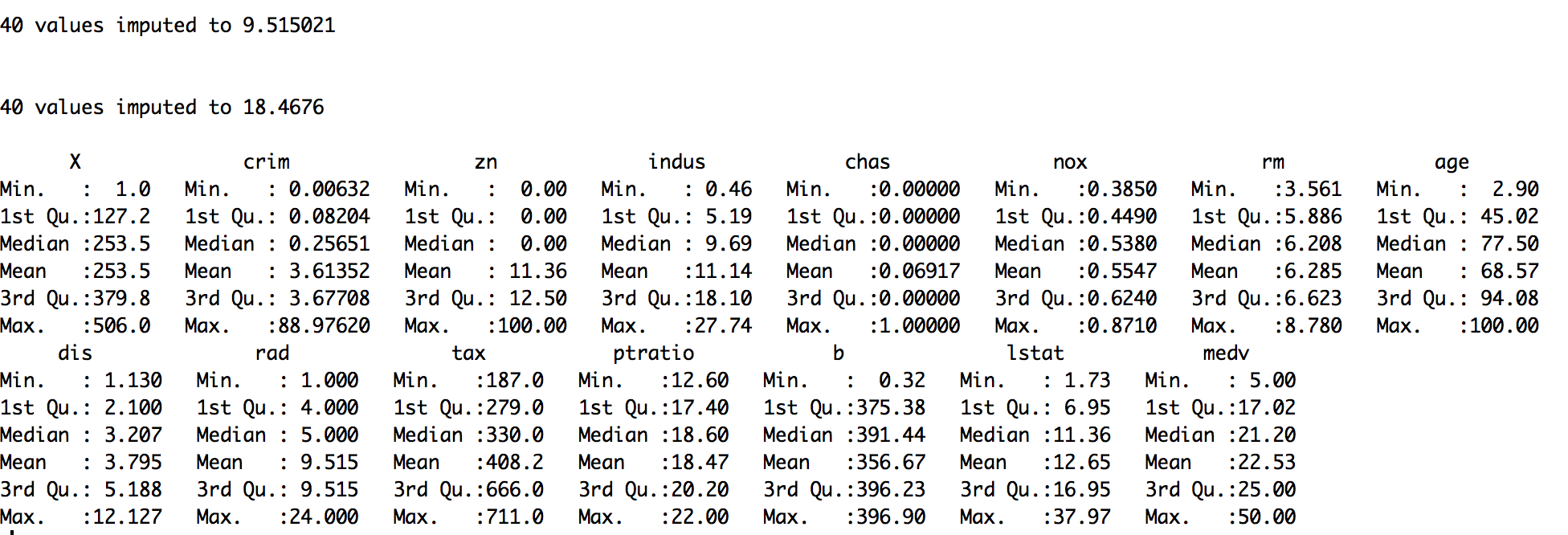
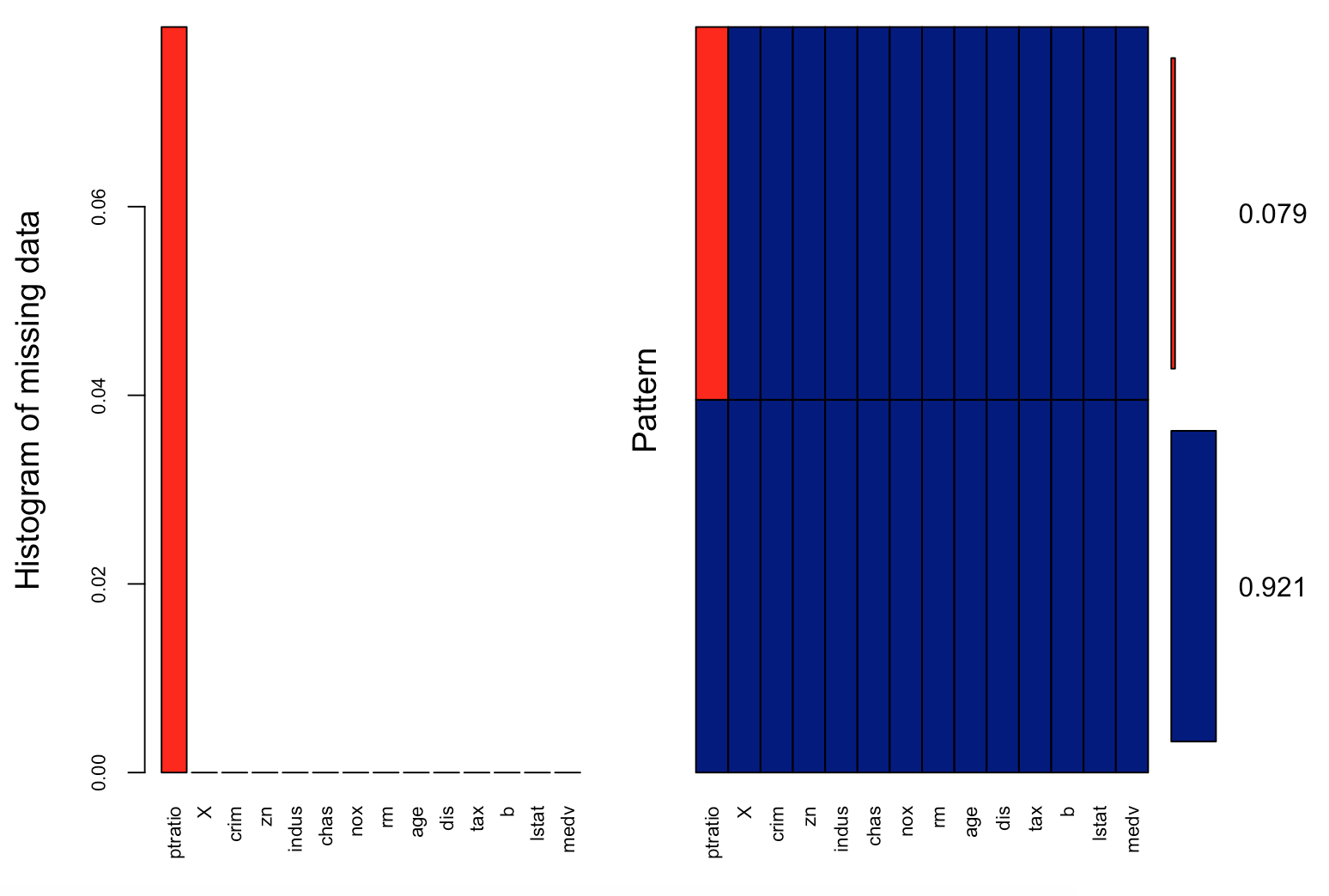
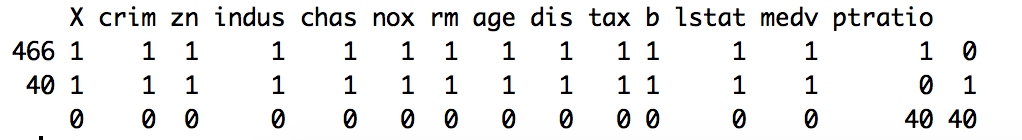In most real-world problems, data is likely to be incomplete because of incorrect data entry, faulty equipment, or improperly coded data. In R, missing values are represented by the symbol NA (not available) and are considered to be the first obstacle in predictive modeling. So, it's always a good idea to check for missing data in a dataset before proceeding for further predictive analysis. This recipe shows you how to handle missing data.
-
Book Overview & Buying

-
Table Of Contents

R Data Analysis Cookbook, Second Edition - Second Edition
By :
R Data Analysis Cookbook, Second Edition
By:
Overview of this book
Data analytics with R has emerged as a very important focus for organizations of all kinds. R enables even those with only an intuitive grasp of the underlying concepts, without a deep mathematical background, to unleash powerful and detailed examinations of their data.
This book will show you how you can put your data analysis skills in R to practical use, with recipes catering to the basic as well as advanced data analysis tasks. Right from acquiring your data and preparing it for analysis to the more complex data analysis techniques, the book will show you how you can implement each technique in the best possible manner. You will also visualize your data using the popular R packages like ggplot2 and gain hidden insights from it. Starting with implementing the basic data analysis concepts like handling your data to creating basic plots, you will master the more advanced data analysis techniques like performing cluster analysis, and generating effective analysis reports and visualizations. Throughout the book, you will get to know the common problems and obstacles you might encounter while implementing each of the data analysis techniques in R, with ways to overcoming them in the easiest possible way.
By the end of this book, you will have all the knowledge you need to become an expert in data analysis with R, and put your skills to test in real-world scenarios.
Table of Contents (14 chapters)
Preface
 Free Chapter
Free Chapter
Acquire and Prepare the Ingredients - Your Data
What's in There - Exploratory Data Analysis
Where Does It Belong? Classification
Give Me a Number - Regression
Can you Simplify That? Data Reduction Techniques
Lessons from History - Time Series Analysis
How does it look? - Advanced data visualization
This may also interest you - Building Recommendations
It's All About Your Connections - Social Network Analysis
Put Your Best Foot Forward - Document and Present Your Analysis
Work Smarter, Not Harder - Efficient and Elegant R Code
Where in the World? Geospatial Analysis
Playing Nice - Connecting to Other Systems