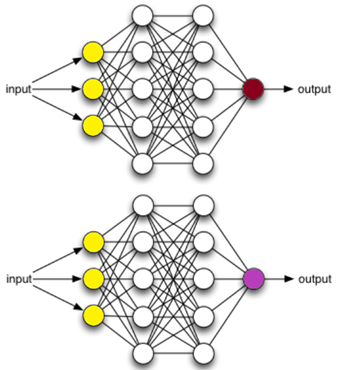
Let's start by defining exactly what we are going to call a neural network. Let me first note that you may also hear a neural network called an Artificial Neural Network (ANN). Although personally I do not like the term artificial, we'll use those terms interchangeably throughout this book.
Did you know that neural networks are more commonly, but loosely, modeled after the cerebral cortex of a mammalian brain? Why didn't I say that they were modeled after humans? Because there are many instances where biological and computational studies are used from brains from rats, monkeys, and, yes, humans. A large neural network may have hundreds or maybe even thousands of processing units, where as a mammalian brain has billions. It's the neurons that do the magic, and we could in fact write an entire book on that topic alone.
Here's why I say they do all the magic: If I showed you a picture of Halle Berry, you would recognize her right away. You wouldn't have time to analyze things; you would know based upon a lifetime of collected knowledge. Similarly, if I said the word pizza to you, you would have an immediate mental image and possibly even start to get hungry. How did all that happen just like that? Neurons! Even though the neural networks of today continue to gain in power and speed, they pale in comparison to the ultimate neural network of all time, the human brain. There is so much we do not yet know or understand about this neural network; just wait and see what neural networks will become once we do!
Neural networks are organized into layers made up of what are called nodes or neurons. These nodes are the neurons themselves and are interconnected (throughout this book we use the terms nodes and neurons interchangeably). Information is presented to the input layer, processed by one or more hidden layers, then given to the output layer for final (or continued further) processing—lather, rinse, repeat!
But what is a neuron, you ask? Using the following diagram, let's state this:
As I mentioned earlier, a neuron is sometimes also referred to as a node or a unit. It receives input from other nodes or external sources and computes an output. Each input has an associated weight (w1 and w2 below), which is assigned based on its relative importance to the other inputs. The node applies a function f (an activation function, which we will learn more about later on) to the weighted sum of its inputs. Although that is an extreme oversimplification of what a neuron is and what it can do, that's basically it.
Let's look visually at the progression from a single neuron into a very deep learning network. Here is what a single neuron looks like visually based on our description:
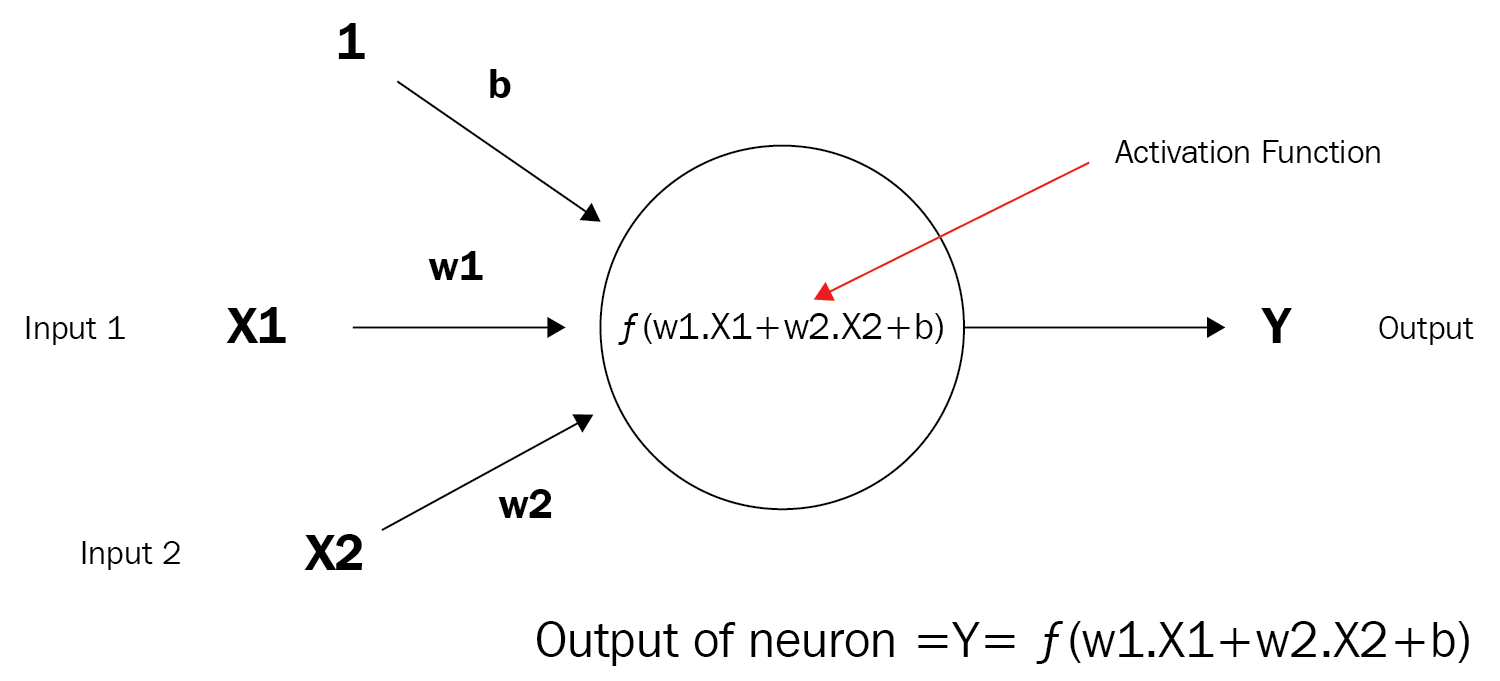
Next, the following diagram shows a very simple neural network comprised of several neurons:
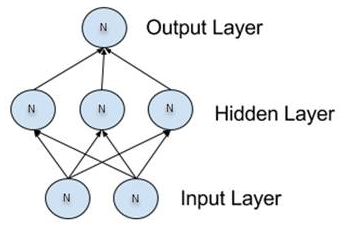
Here is a somewhat more complicated, or deeper, network: