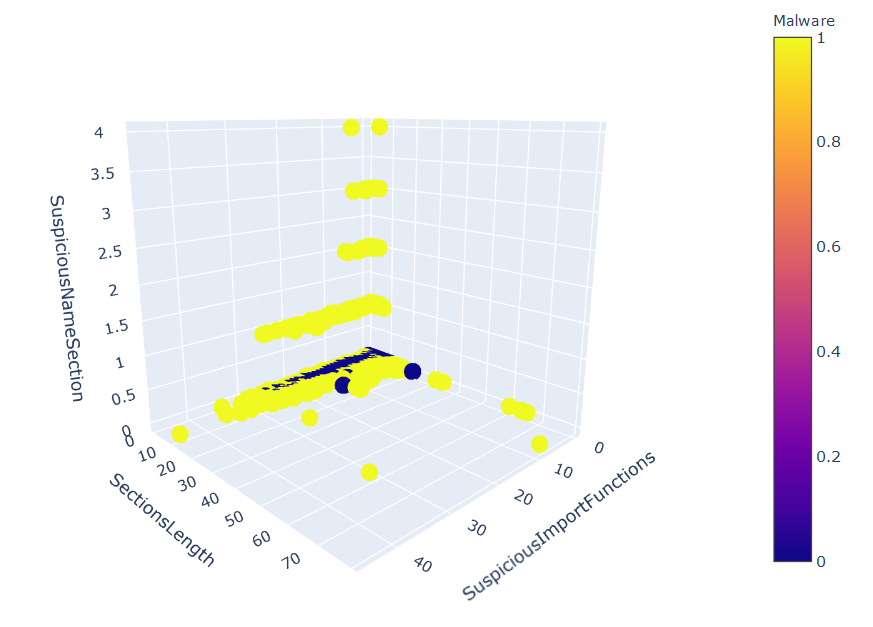
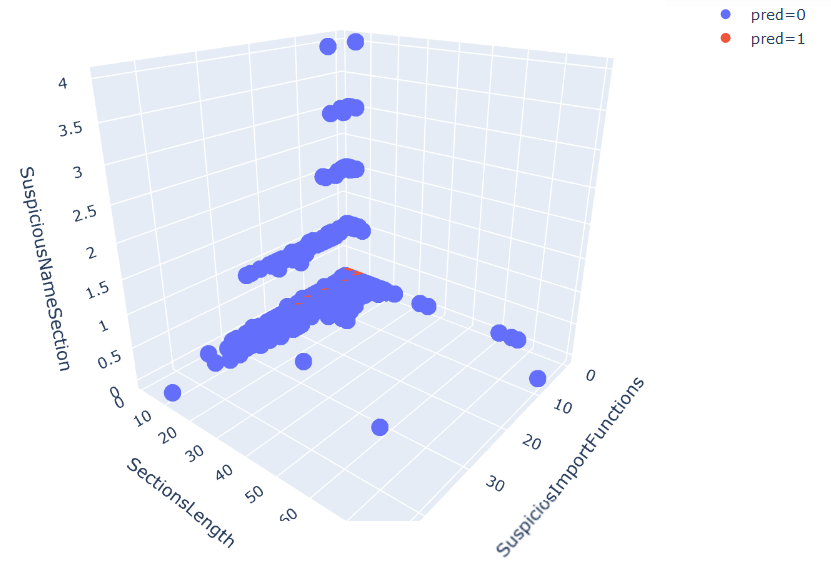
Clustering is a collection of unsupervised machine learning algorithms in which parts of the data are grouped based on similarity. For example, clusters might consist of data that is close together in n-dimensional Euclidean space. Clustering is useful in cybersecurity for distinguishing between normal and anomalous network activity, and for helping to classify malware into families.
-
Book Overview & Buying

-
Table Of Contents

Machine Learning for Cybersecurity Cookbook
By :
Machine Learning for Cybersecurity Cookbook
By:
Overview of this book
Organizations today face a major threat in terms of cybersecurity, from malicious URLs to credential reuse, and having robust security systems can make all the difference. With this book, you'll learn how to use Python libraries such as TensorFlow and scikit-learn to implement the latest artificial intelligence (AI) techniques and handle challenges faced by cybersecurity researchers.
You'll begin by exploring various machine learning (ML) techniques and tips for setting up a secure lab environment. Next, you'll implement key ML algorithms such as clustering, gradient boosting, random forest, and XGBoost. The book will guide you through constructing classifiers and features for malware, which you'll train and test on real samples. As you progress, you'll build self-learning, reliant systems to handle cybersecurity tasks such as identifying malicious URLs, spam email detection, intrusion detection, network protection, and tracking user and process behavior. Later, you'll apply generative adversarial networks (GANs) and autoencoders to advanced security tasks. Finally, you'll delve into secure and private AI to protect the privacy rights of consumers using your ML models.
By the end of this book, you'll have the skills you need to tackle real-world problems faced in the cybersecurity domain using a recipe-based approach.
Table of Contents (11 chapters)
Preface
 Free Chapter
Free Chapter
Machine Learning for Cybersecurity
Machine Learning-Based Malware Detection
Advanced Malware Detection
Machine Learning for Social Engineering
Penetration Testing Using Machine Learning
Automatic Intrusion Detection
Securing and Attacking Data with Machine Learning
Secure and Private AI
Other Books You May Enjoy